(Winter 2021)|Lecture 11 Question Answering
04 Feb 2022
Reading Comprehension이 어떤 task인지, 그리고 어떤 흐름을 거쳐서 현재 SOTA한 모델 중 하나인 SpanBERT까지 왔는지에 대한 내용이다. 후반부에서는 open-domain Question Answering task에 대해서 과거엔 어떤식으로 접근했고, 최근에는 어떤식으로 접근하는지 대한 내용이 있다. (Retriever(IR) ,Reader 모두 필요없다. 매우 큰 모델이 다 해결해준다..! )

Danqi Chen 이라는 분의 수업이었다. RoBERTa, SpanBERT의 coworker 이시고, dense passage retrieval method on open domain question answering에도 참여하셨다고 한다.

- brief introduction about Question & Answering, 근래에 사람들이 이 분야에 대해 어떤것을 연구하는지
- Question Answering problem중 reading comprehension problem에 대해 다룰 예정이다.
- very large collection of the documents에 대해 다루는 open-domain question answering에 대해서도 배운다.
Question Answering은 natural language에 의한 questions에 대해 automatically 대답하는 시스템을 만드는 것이 목적이다. 과거에는 dependency analysis와 같은 것을 사용해서 질문의 답에 해당하는 text를 찾았다.
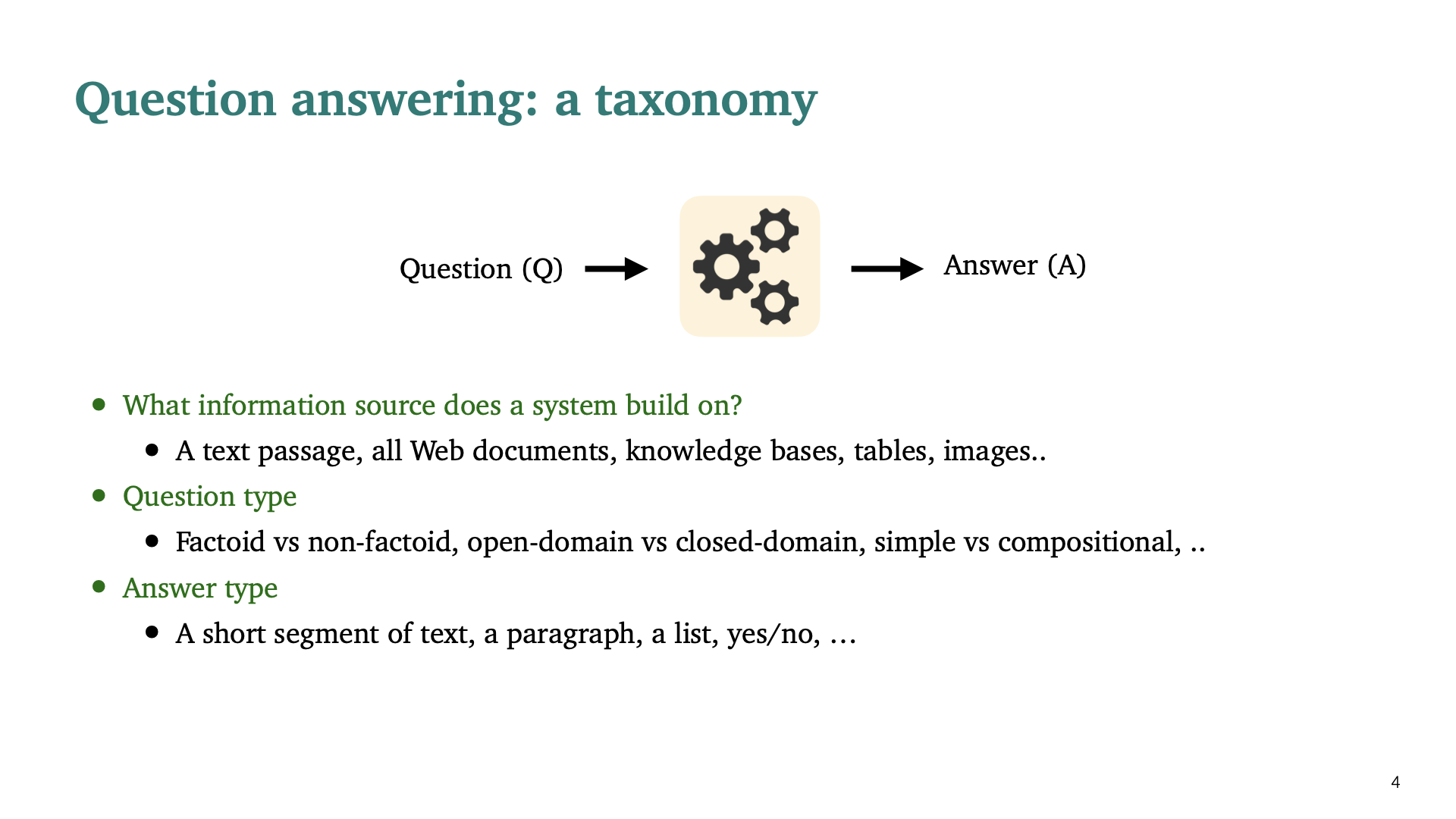
Question type, Answer type이 위와 같다. 매우 많은 종류의 Question Answering problem이 있고, 각각은 다른 종류의 데이터와 다른 technique, different metric을 필요로 한다
무엇인지 물어보는 question의 예시이다.
방법을 물어보는 how-to question에 대한 예시이다.
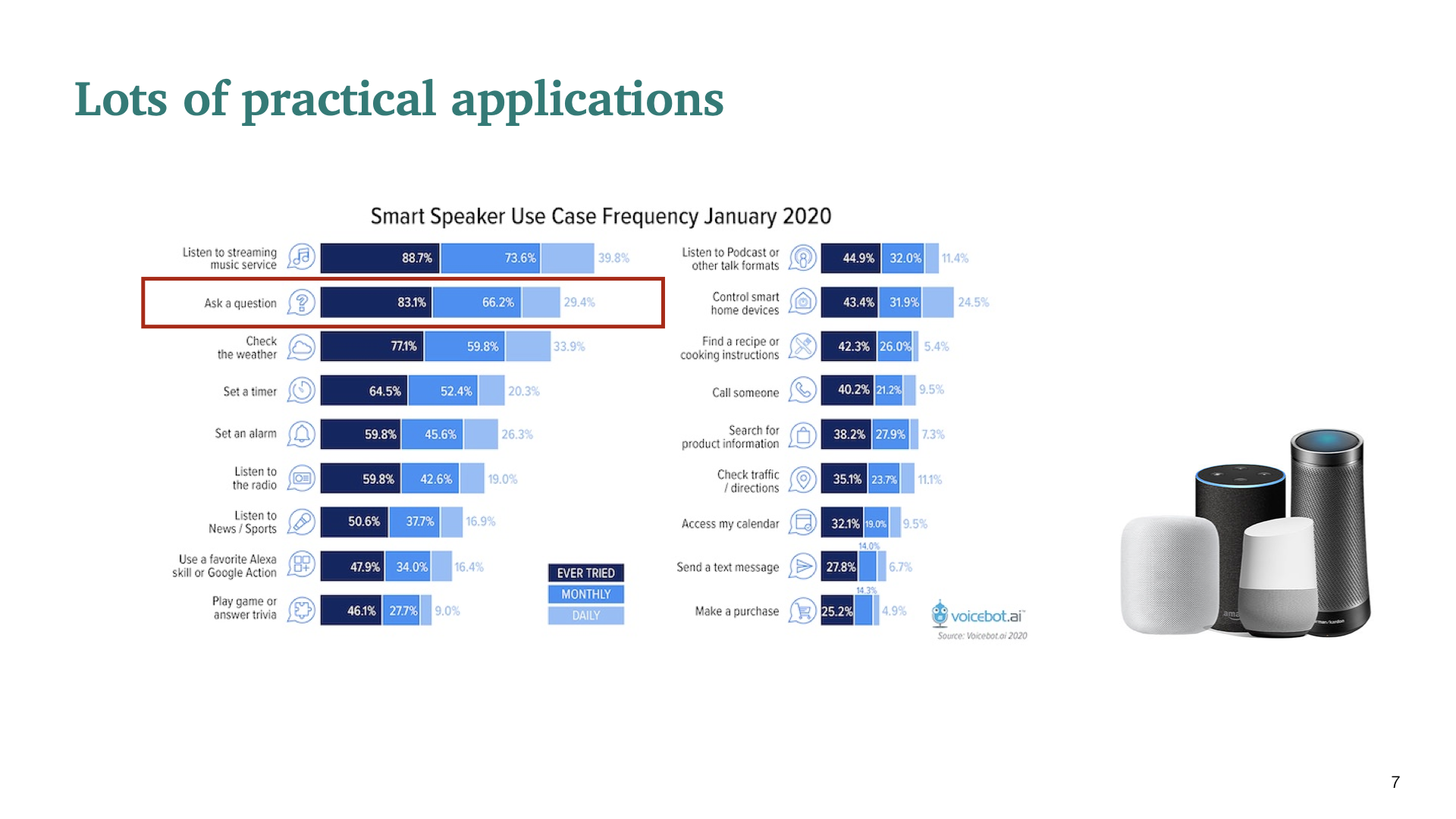
Ask a question이 google home에서 2번째로 가장 많이 사용하였다.

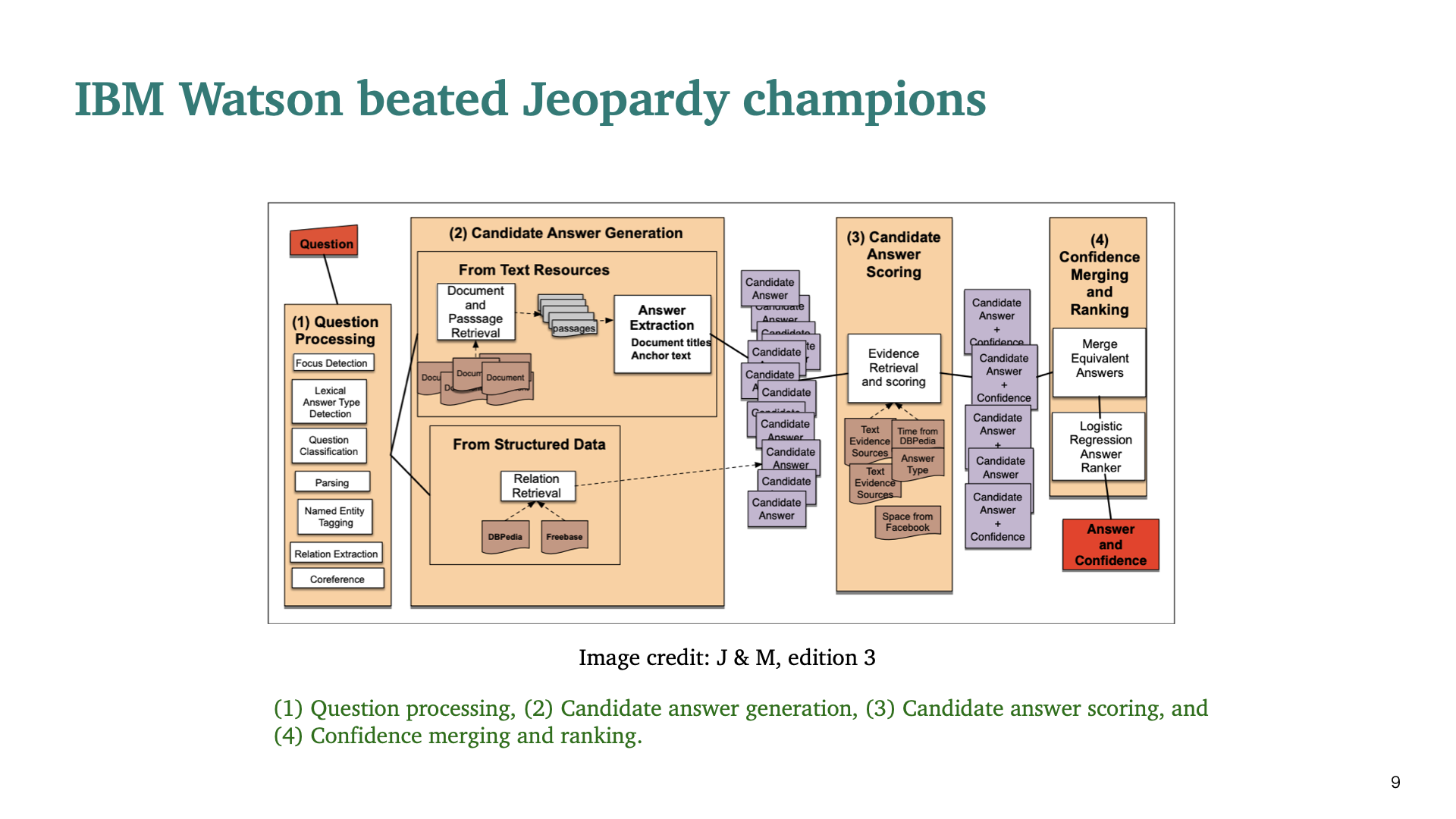
매우 복잡하고 많은 module이 있는 시스템이다. 각 stage마다 여러가지 NLP technique이 적용된 것을 확인할 수 있다. 10년전에는 이것이 SOTA한 시스템이었다.
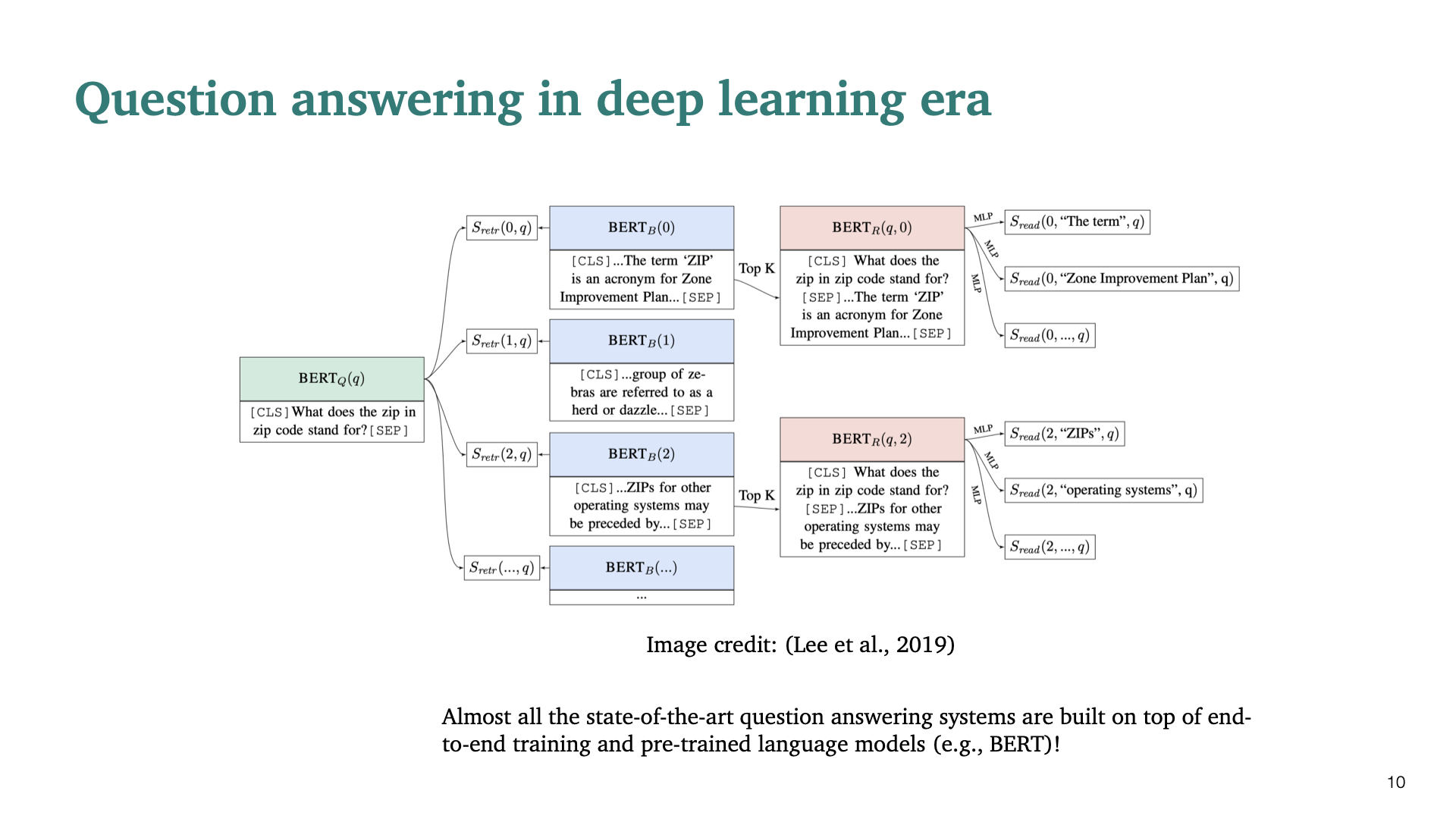
근래에는 딥러닝을 사용한 방법은 QA problem에 대해 매우 뛰어난 성능(SOTA)을 보이고 있다.
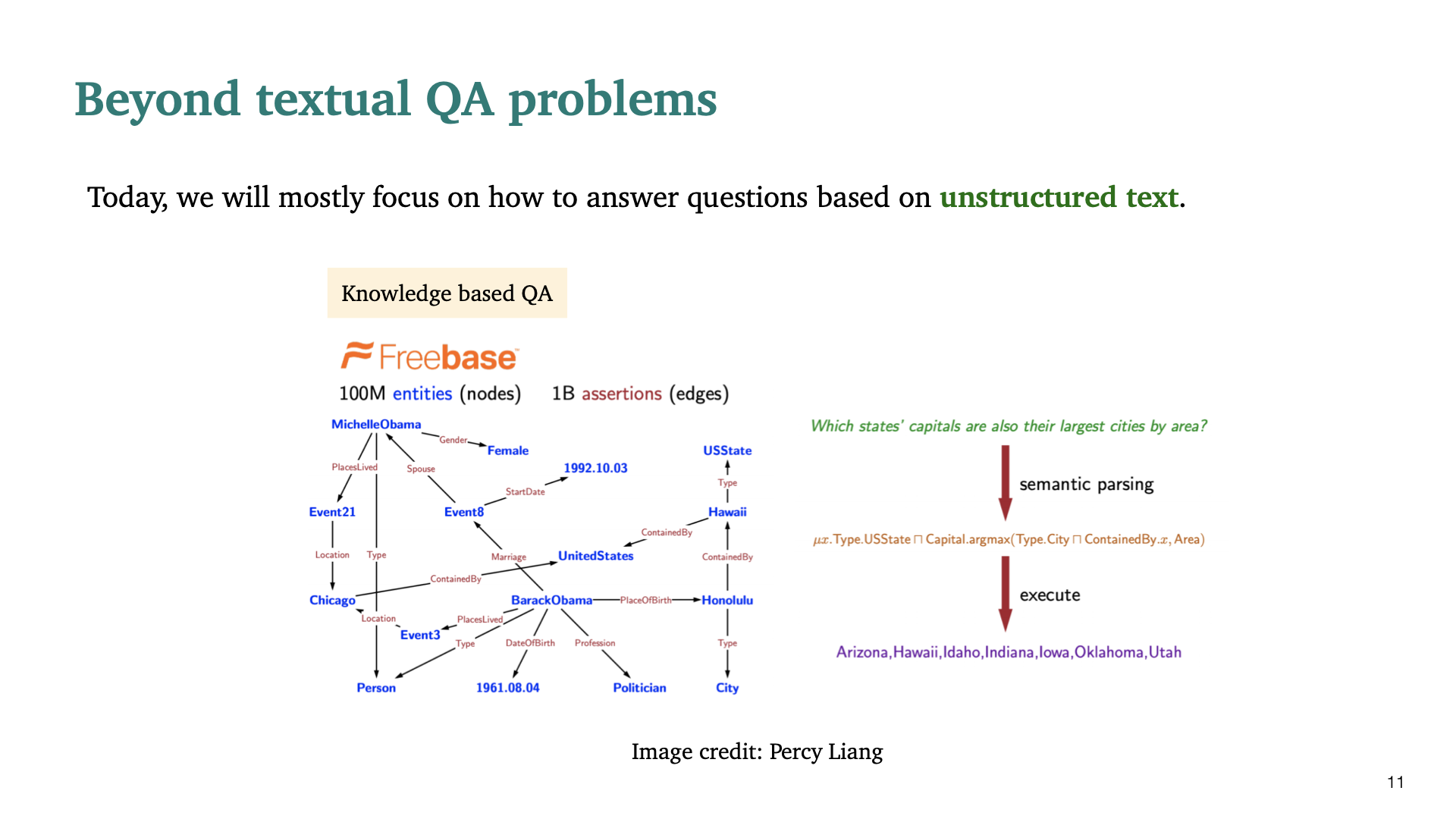
이번 수업에서는 text based, textual question answering problem에 초점을 맞춰 진행할 것이다. unstructured text에 대한 problem중 하나의 큰 클래스는 Knowledge based QA이다. 매우 큰 database를 기반으로 question에 대해 답하는 것이다. 주어진 질문에 대해 semantic parsing을 통해 특정한 logic form으로 바꾼후, 특정한 logic을 database에서 execute하여 원하는 답을 찾게 된다.

textual QA problem 말고도 위와 같은 visual QA problem이 있다. 하지만 이러한 종류는 본 수업에서 다루지 않을 예정이다.

Reading Comprehension은 passage of text를 이해하고 답하기 위해서 필요한 basic problem이다. Reading comprehension의 input은 passage of text, question이고, output(목적)은 question에 대한 answer이다.

사람에게는 어려운 질문이 아니겠지만, machine에게는 어려운 질문이다. Hindi와 3.3%가 어떤 것을 의미하는 지 이해해야 한다.

이제 왜 reading comprehension을 다루는지에 대해 설명할 것 이다. Real word에서 많은 실용적인 application이 있다. 그리고 다음과 같은 추가적인 두가지 이유가 있다.
- Reading comprehension은 컴퓨터가 human language를 얼마나 잘 이해하는 지에 대한 중요한 test bed라고 할 수 있다. 사람이 어떤 언어를 잘 이애하고 있나 평가하는 것과 매우 유사하다. 1977년 Wendy Lehnert가 말한 것을 참고해보면, 이 task가 왜 중요한 test bed인지 이해할 수 있다.
- 많은 NLP task들이 reading comprehension problem으로 수렴될 수 있다. 예를들어, information extraction과 Semantic role labeling이다. 전자에 대해선 버락 오바마에 대한 질문을 쪼개고, 다음 올 단어를 찾는 task를 reading comprehension task로 해결할 수 있다. 후자는 각 단어의 semantic role를 labeling하는 것인데, Question Answering problem으로 바꿔 이를 해결할 수 있다.

유명한 dataset인 SQuAD에 대한 것이다. 이 dataset은 supervised reading comprehension dataset으로, 100K annotated passage question and answer triple로 구성된다. 이러한 종류의 large scale supervised dataset은 reading comprehension을 위한 신경망을 학습하는 것에 있어서, key ingredient 이다. SQuAD에서 중요한 특성 중 하나는, 각 answer가 short segment of text 즉 span으로 이뤄져있다. 하지만 생각해보면, 모든 question에 대한 답이 이러한 span으로 이뤄져 있지는 않다. 그래서 span으로 답이 가능한 질문만 이 dataset에 포함되어 있다.

Evaluation에는 exact match와 F1 score가 사용되었다. 모든 질문에 대해 unique한 답이 없을 수 있기 때문에, question에 대한 3 gold answer를 testset으로 두었다.
학생질문 Q) BERT에 대해 QA task로 fine tuning을 하여 NER, relation extraction와 같은 다른 task에서 더좋은 성능을 낼 수 있게 하는 방법이 있나?
A) 모든 task가 QA task로 convert될 수 있지만, 이것에 대해 fair comparison할 만한 연구는 없는 것같다. NER task에 대해 SOTA는 sequence of word위에 tagger를 단순히 학습시키는 것이기도 하다.

이제 SQaUD dataset에 대한 Reading comprehension을 위한 Neural Model을 어떻게 build할 것인지 설명할 것이다. (passage, paragraph, context), (question, query)에 대한 표현을 interchangeably하게 사용할 것이다. answer은 passage안의 section of text여야 하기 때문에, output은 1≤ start ≤ end ≤ N이라 표현할 수 있다. 연구된 모델들은 다음 두 종류로 나눌 수 있다.
- 2016 ~ 2018 : Family of LSTM based model with attention
- After BERT like model
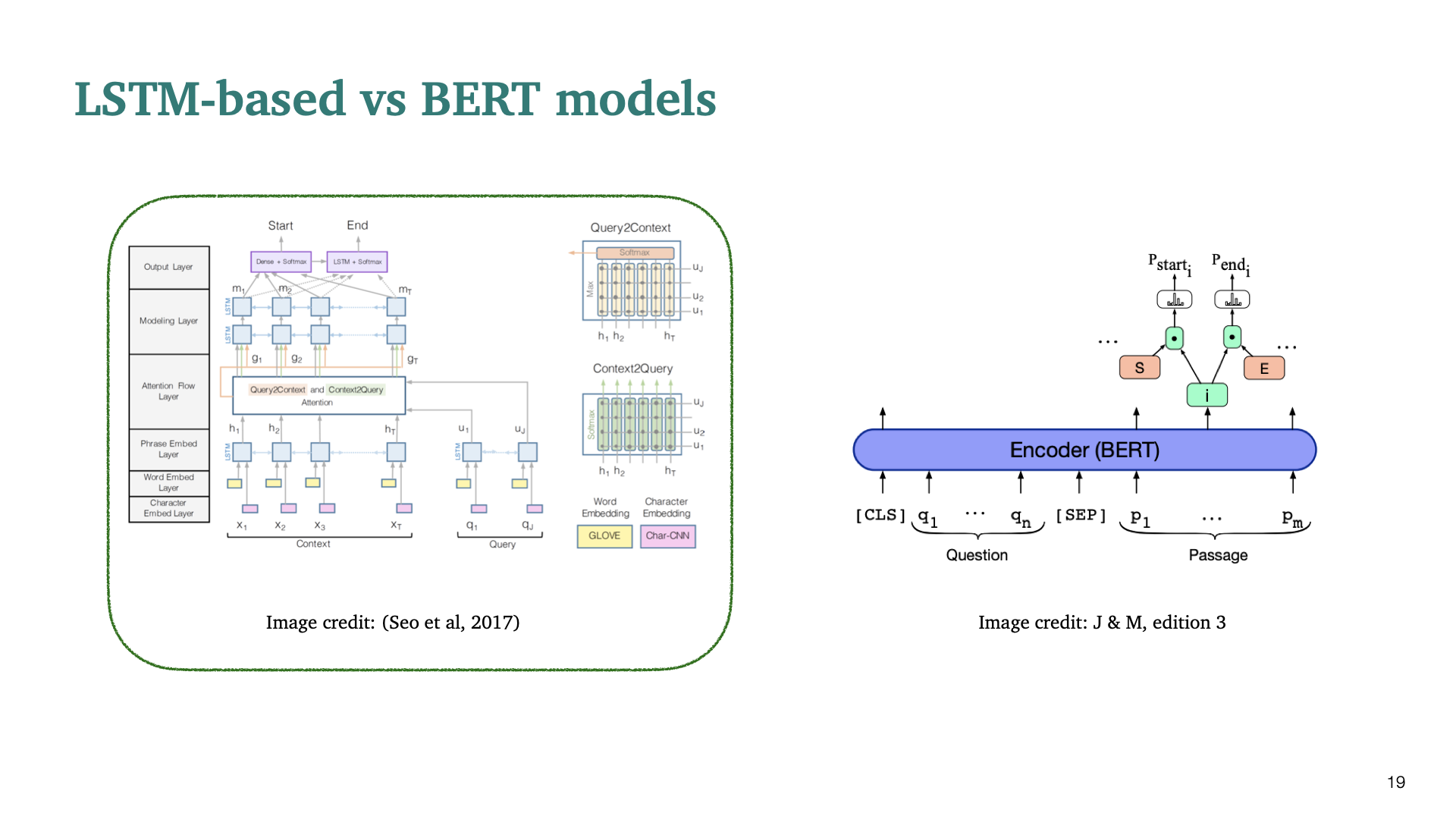
LSTM-based model을 중점적으로 설명한 뒤에, BERT을 사용한 모델을 간단하게 짚고 넘어가겠다.

Machine Translation을 다루는 seq2seq model의 decoder는 target sentence를 generate해야하므로 auto-regressive 해야했다. 하지만 reading comprehension task에서는 generate하지 않기 때문에 answer의 start, end position을 예측하는 classifier만을 학습하면 된다.
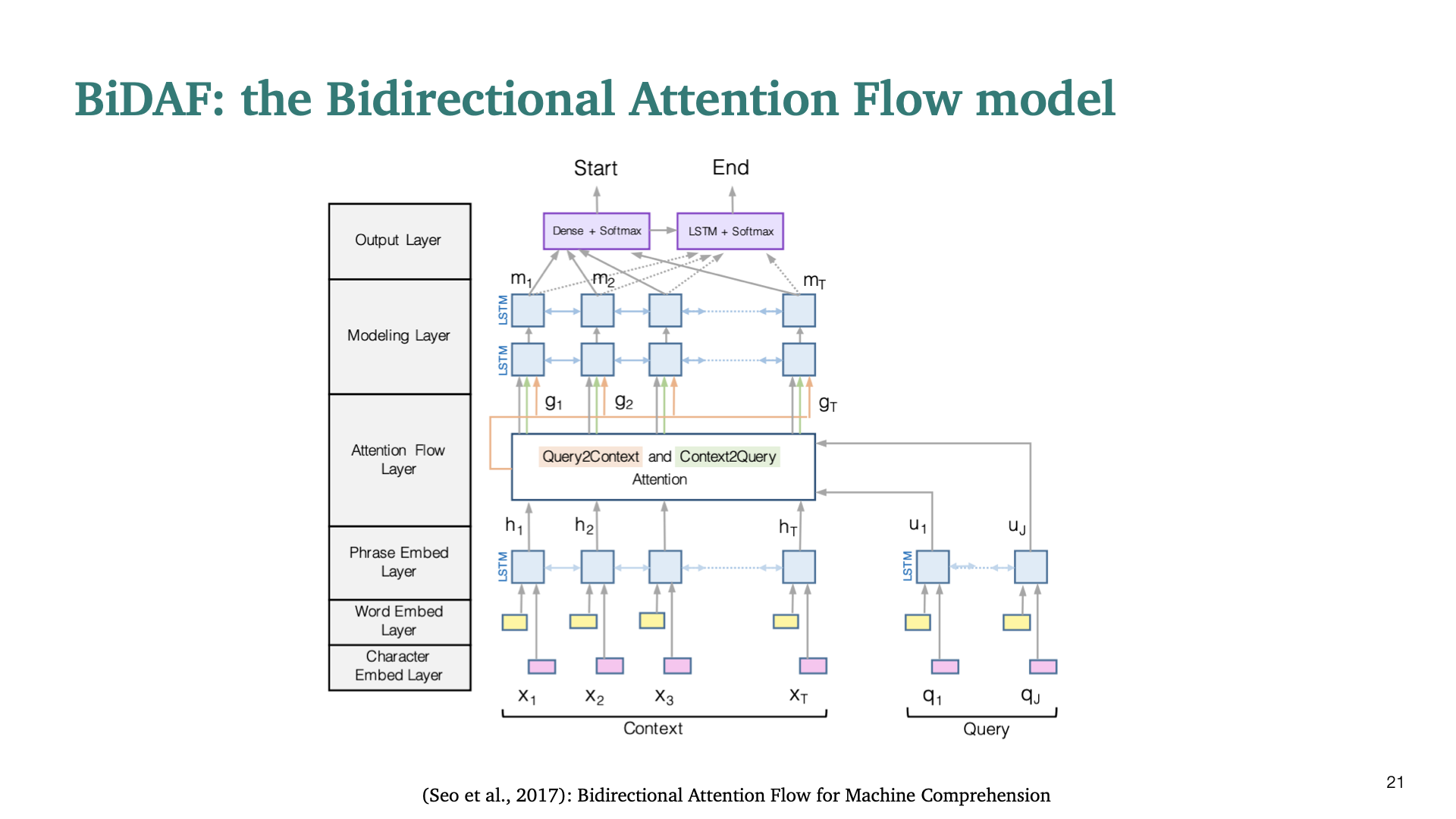
서민준 교수님이 발표한 BiDAF 논문으로, 당시 SQuAD dataset에서의 reading comprehension task에서 SOTA한 성능을 보였다고 한다. BiDAF모델을 bottom layer부터 top layer까지 하나씩 설명한다.
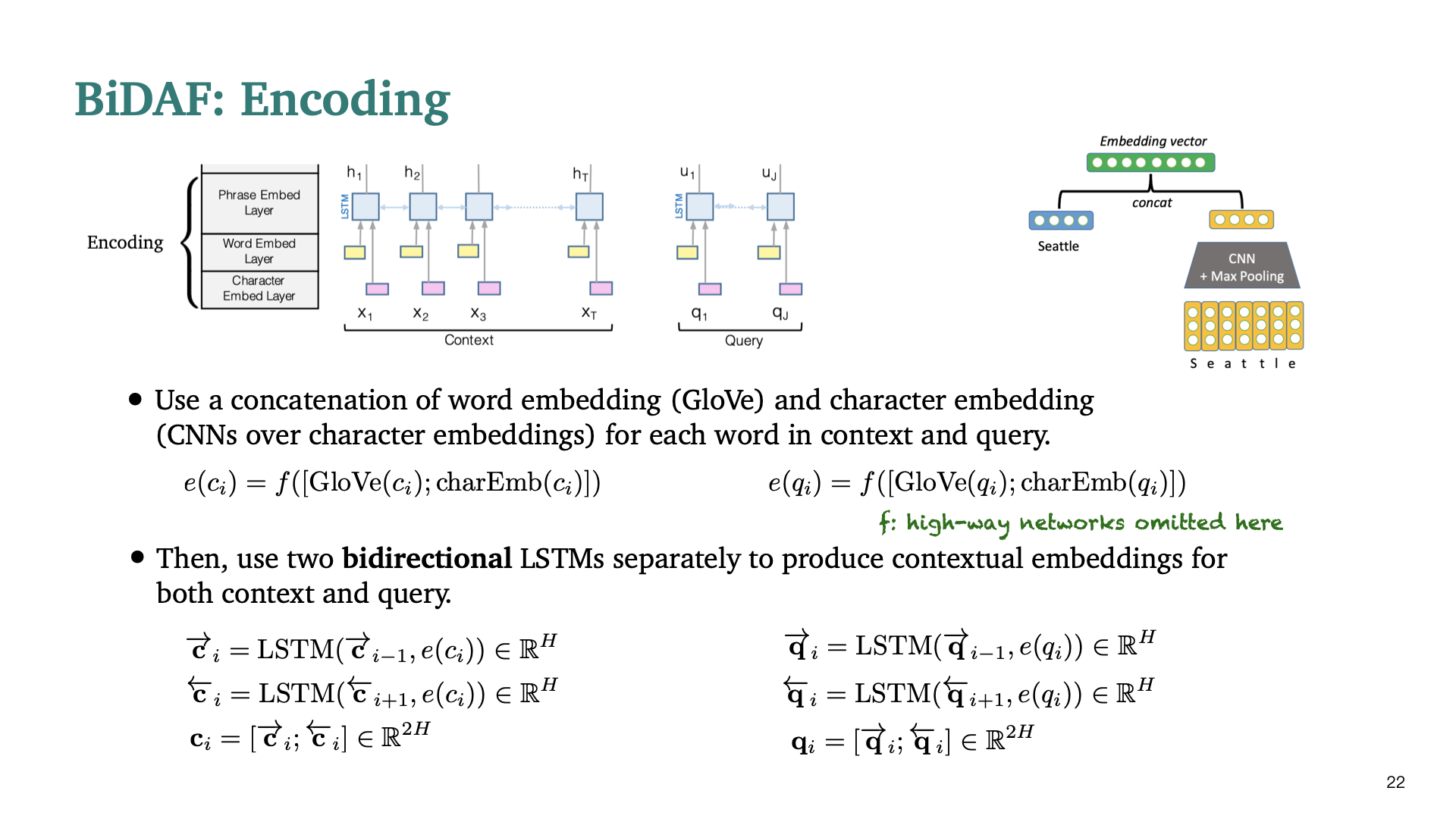
Context와 query 모두에 대해 contextualized embedding을 produce하기 위해 위 diagram에 표현된 Encoding을 거치게 된다. 먼저 Glove embedding과 character level → CNN+MAX pooling을 통한 embedding을 concatenate한 후에, 두개의 blstm을 context, query에 사용한다. (character level로 Embedding을 하면 unseen word에 대해서도 대처할 수 있게 된다.)
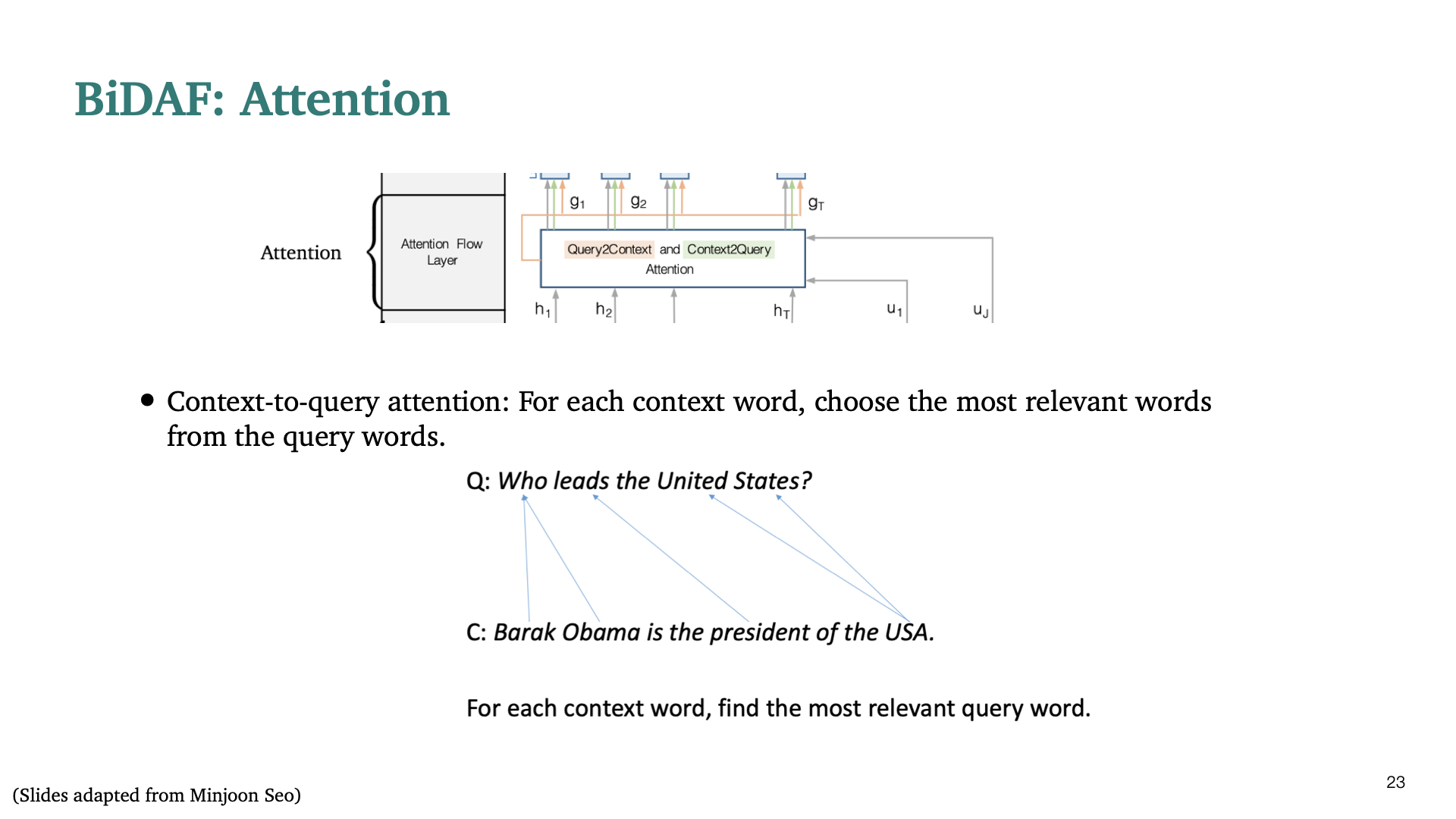
다음 component는 Attention이다. 여기서의 Attention의 목적은 query와 context 사이 의 interaction을 capture하는 데에 있다. 첫번째 attention으로, context-to-query attention은 각 context word에 대해, 위의 slide처럼 query의 어떤 단어에 가장 많이 attend하는지 찾게된다.

두번째 attention은 query - to - context attention으로써, 바로 전의 attention과 반대 방향으로 query의 각 단어에 대해 context의 어떤 단어에 attend할지 찾게된다.

context-query attention과 query-to-context attention을 실제로는 어떻게 계산하는지에 대한 수식이다. 먼저 모든 pair에 대한 similarity를 계산한후, 각 상황에 맞게 softmax를 적용하여 weighted sum을 구하면 된다.
Q1) context-query attention과 query-to-attention이 왜 symmetric하지 않은지에 대한 질문이 있었다. A1) 이에 대한 답변으로, 전자는 context의 각 단어가 query의 어떤 단어에 relevant하는지 찾는 것이고, 후자는 해당 query의 단어에 대해 context의 어떤 단어들이 relevant할지 안할지 찾는 것이기 때문에 symmetric하지 않다. $b_i$ 또한 context word에 대한 representation인데, 수식을 보면 context의 각 단어에 대해 query의 모든 단어와 relevant한지 안한지 모두 고려한다.
Q2) 왜 두가지 attention이 필요한가? 하나만 사용해도 되나? A2) 두가지 관계에 대해 모두 보는 것이 더 좋은 representation을 제공할 수 있다고 하였다.
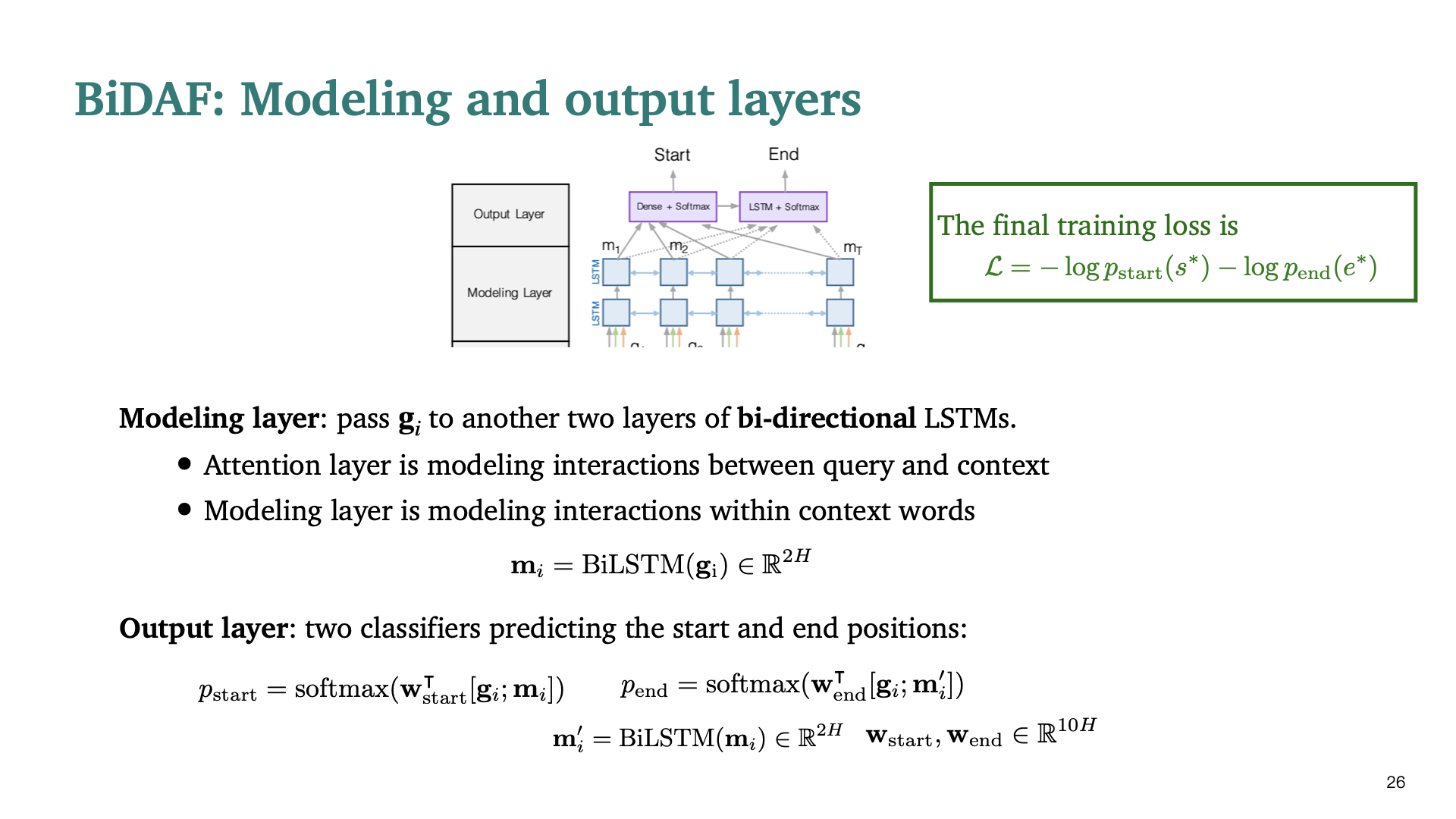
마지막으로, modeling layer와 output layer이다. modeling layer에서는 context words 사이의 interaction을 capture하는 데 있다. Output Layer는 두가지 classifier로 써, start/end position을 predict하는 Layer이다. Cost function은 각각의 softmax output의 product을 negative log한것과 동일하다.
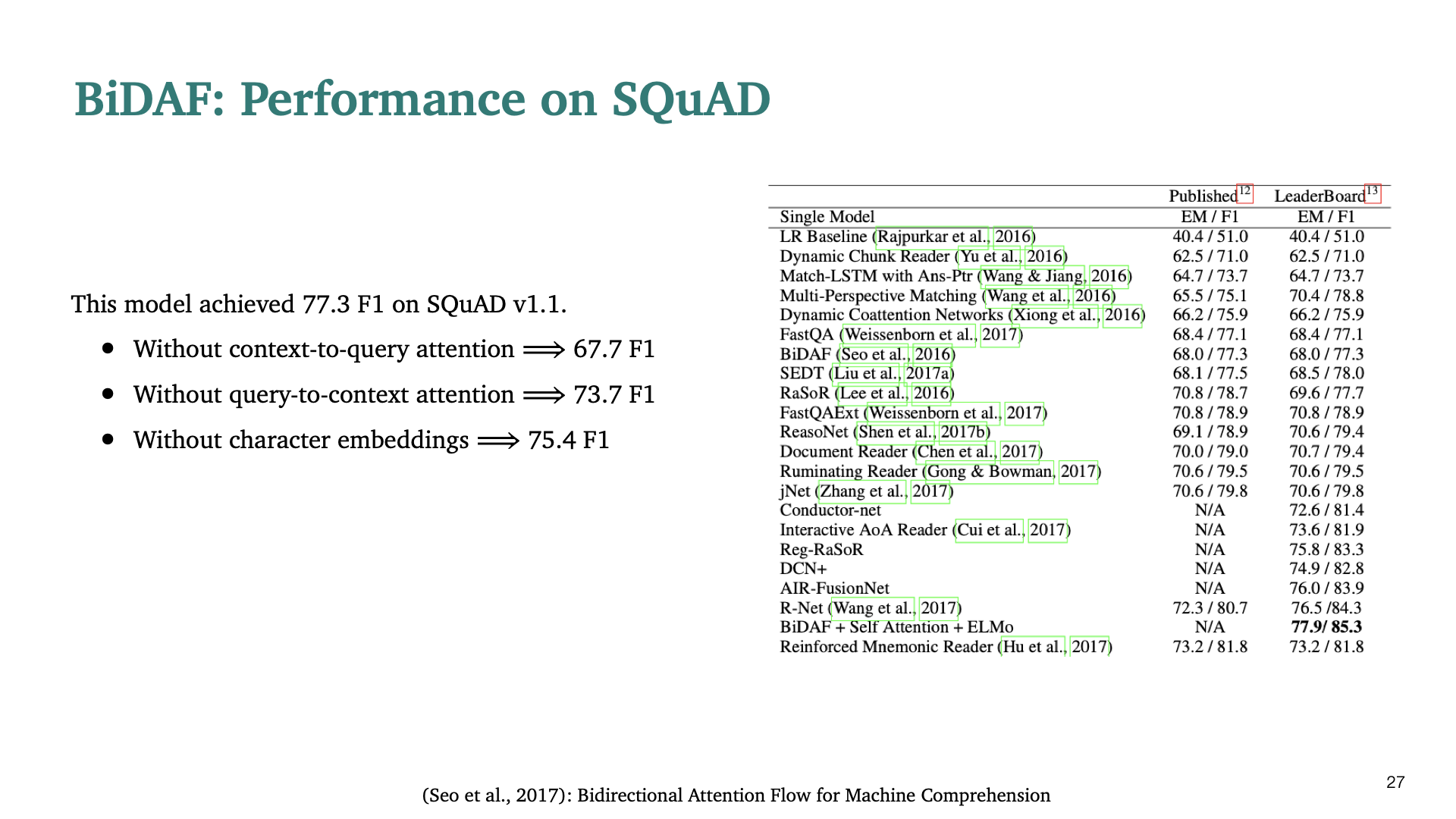
BiDAF의 성능에 관한 slide이다. 각 component의 유무에 따라서도 성능이 다르게 보인다.
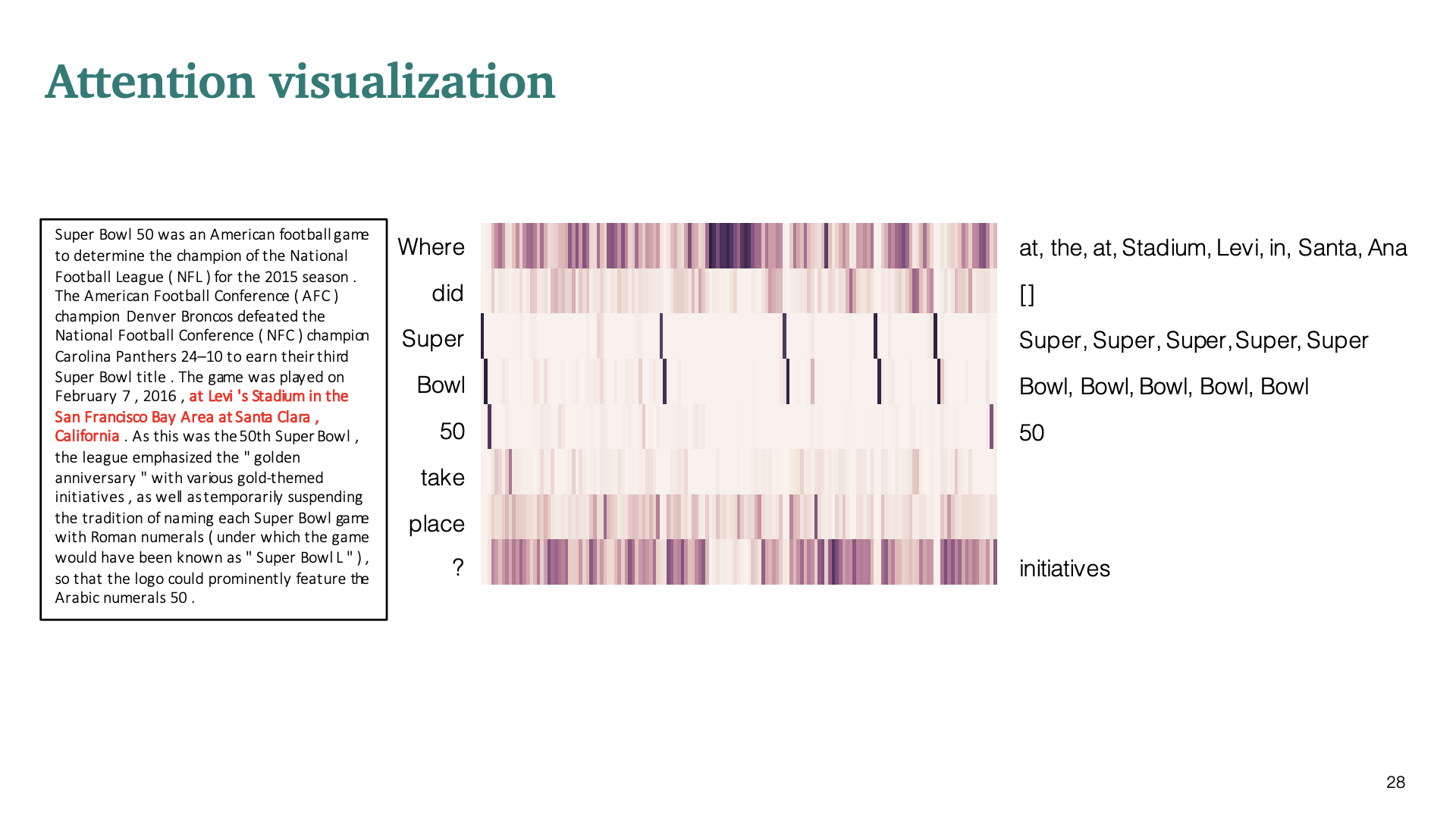
실제로 context와 question의 similarity를 capture할 수 있는지 보여주는 attention visualization이다.
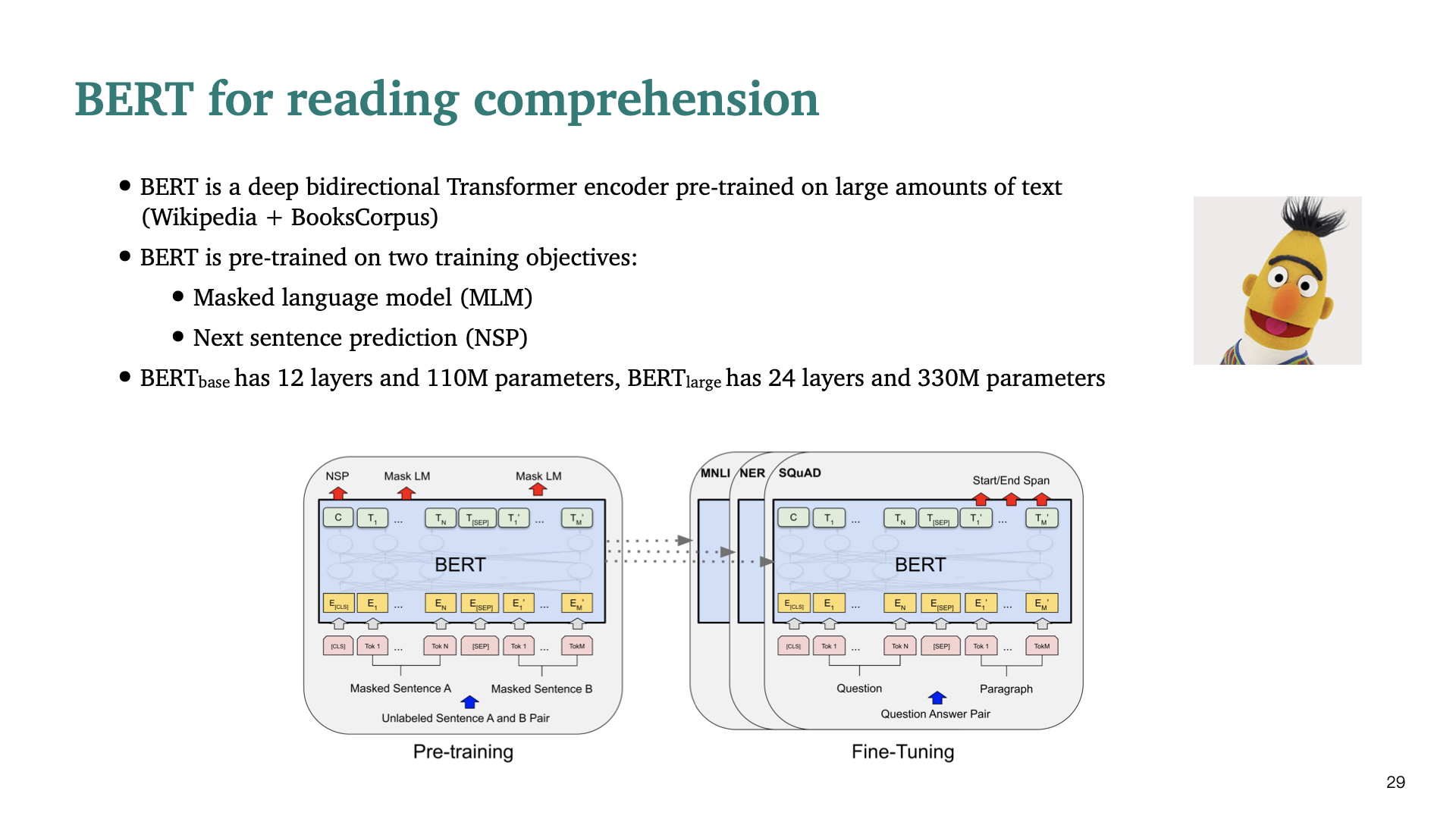
이제 reading comprehension task를 BERT로 어떻게 해결할지 설명한다. 기본적으로 BERT는 deep bidirectional Transformer pretrained encoder이다. 두가지 training objective MLM(Masked Language Modeling), Next Sentence prediction(NSP)로 pretrained 되었다.
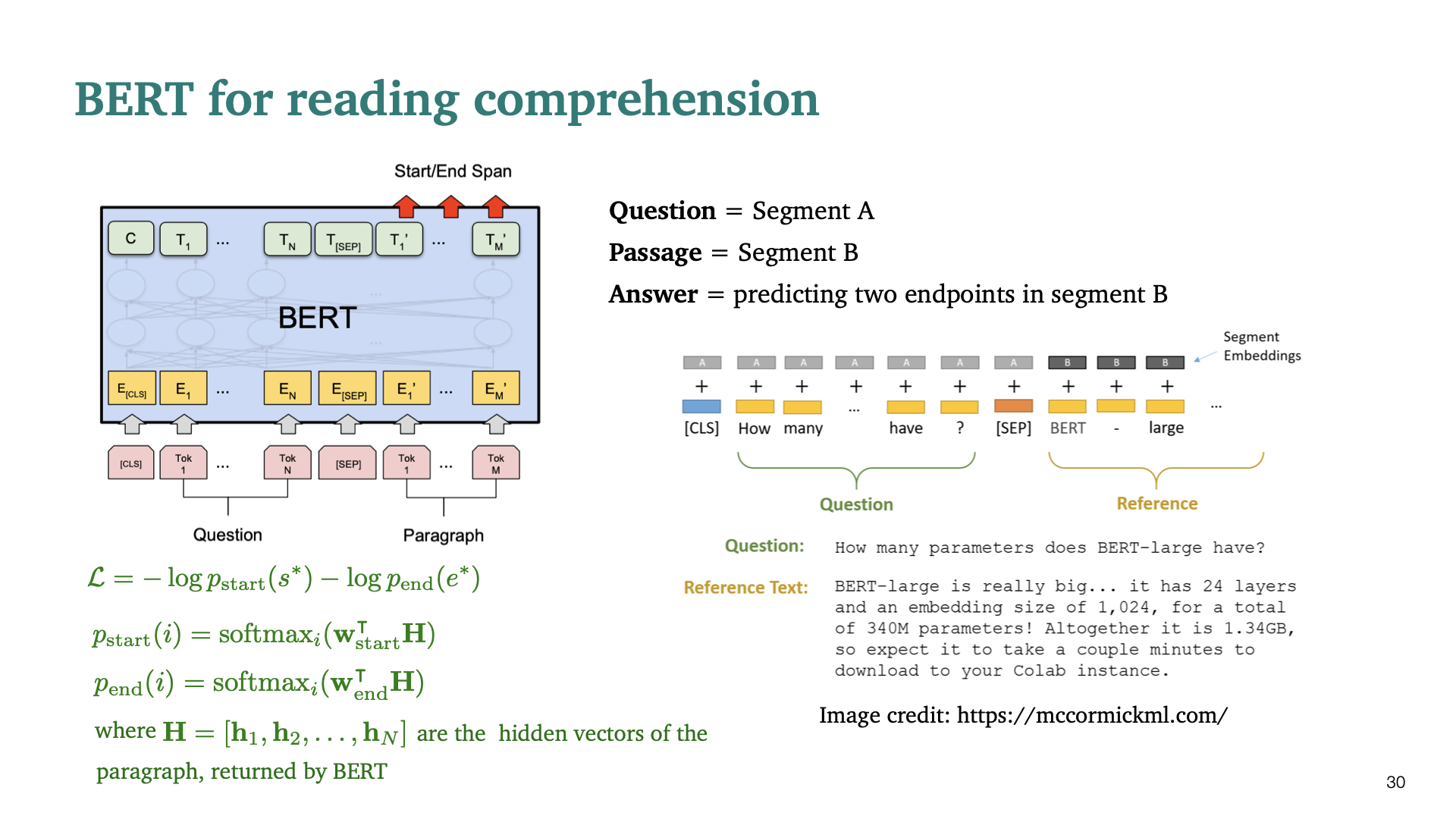
두번째 training objective였던 Next Sentence Prediction(NSP)에서는 두개의 segment를 사용한다. Reading comprehension의 context, quest을 두개의 segment로 보는것이다. 그래서 answer는 segment B의 두개의 endpoint를 predict하는 것이다. Question token과 context token을 위 slide처럼 [SEP] token을 경계로 concatenate한다. BiDAF와 마지막 output layer가 다르다. $h_i$는 encoder의 output으로 start, end position에 대해 weight를 각각 학습하게 된다.
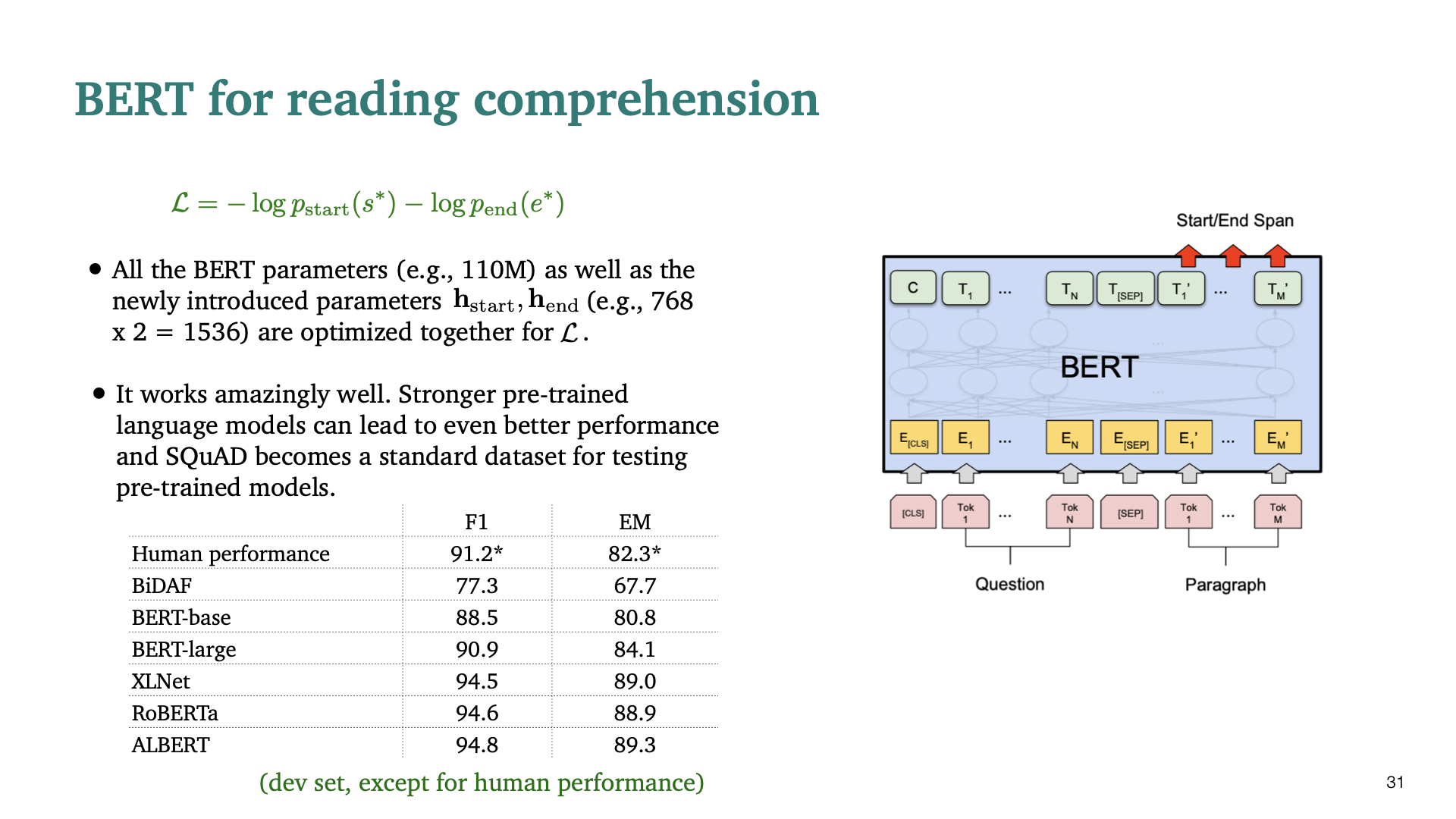
BERT를 기반으로 한 model들의 성능이다. Human performance 보다 훨씬 좋은 성능을 보이는 것을 볼 수 있다.

BiDAF와 BERT를 비교한 내용이다.

BiDAF와 BERT model이 근본적으로 크게 다르지 않다는 것을 보여주는 내용이다. attention( context, context)을 BiDAF에 추가했을 때, 더 좋은 성능을 보였다고 한다.
Q3) pretrained model이 아닌 Transformer model을 사용해도 괜찮은가? A3) google에서 QANet이라는 것을 발표했었고, transformer로 만들어진 모델이다. 하지만 BERT보다 under perform한다.

Reading comprehension을 위한 training objective를 만들 수 있나에 대한 내용이다. 이에 대한 답변이 SpanBERT라 불리는 모델이다. SpanBERT에서 제안한 핵심 두가지 아이디어는 다음과 같다.
- 각 단어를 단순히 masking하는 것이 아니라, contiguous spans of words를 masking하는 것이다.
- information of span을 두개의 end-point에 compress한다는 idea이다. 그래서 두개의 endpoint으로 사이의 모든 masked span을 예측한다는 것이다. 이렇기 때문에 SpanBERT라 불린다.
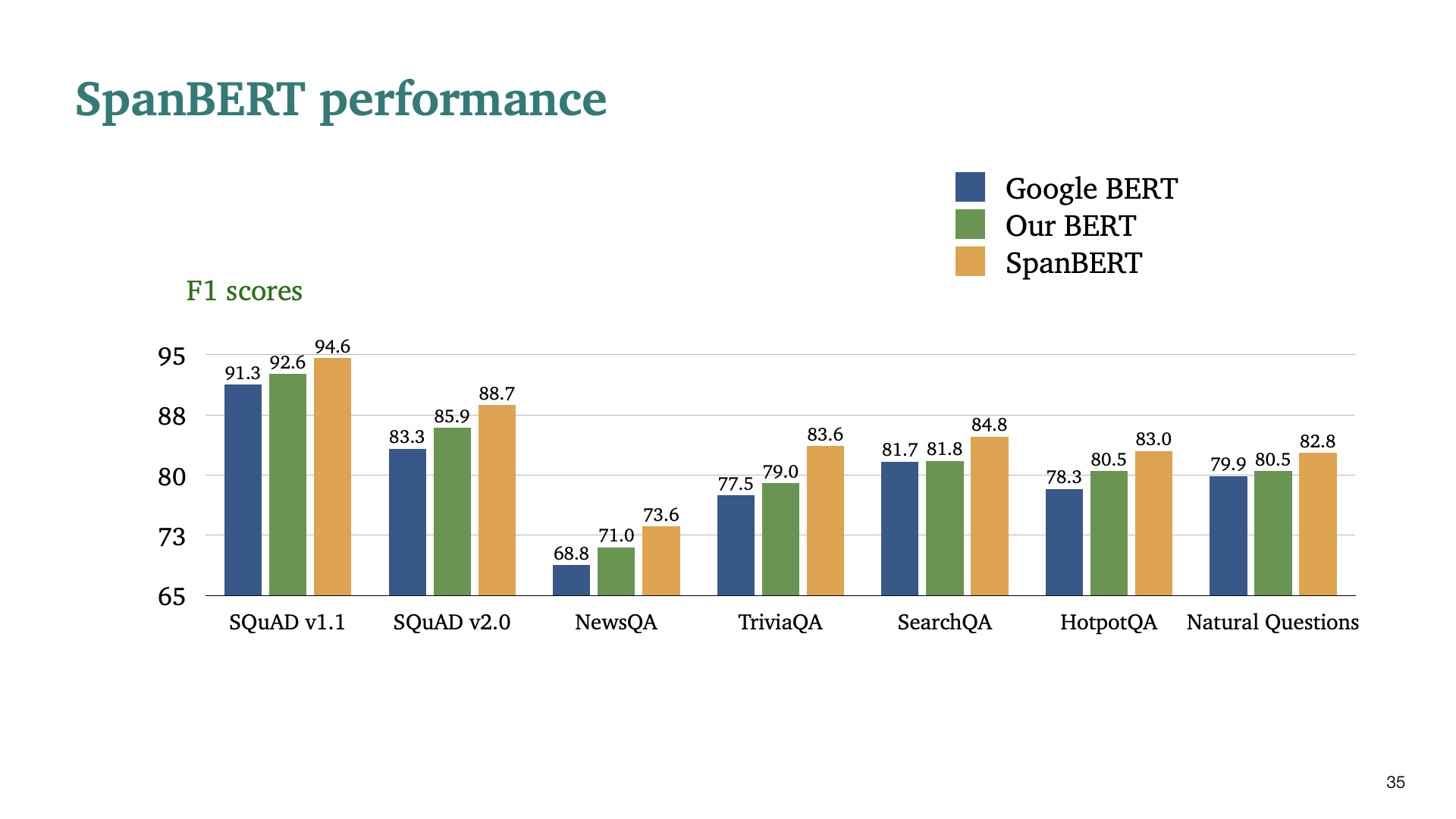
그래서 성능이 훨씬 좋아졌다!..

BERT, SpanBERT가 reading comprehension task에 대해 매우 좋은 성능을 보이는데, 이 task가 해결되었다고 봐도 무방한가에 대한 내용이다. 본론부터 말하면 그렇지 않다고 한다. Out of domain distribution으로부터의 adversarial example에서는 매우 저조한 성능을 보인다고 한다. (context와 관련없는 어떠한 문장에 대해 저조한 성능을 보인다는 뜻이다. 다시 말하면 관련없는 문장이 하나 있다면, system 자체를 바보로 만들 수 도 있다.)
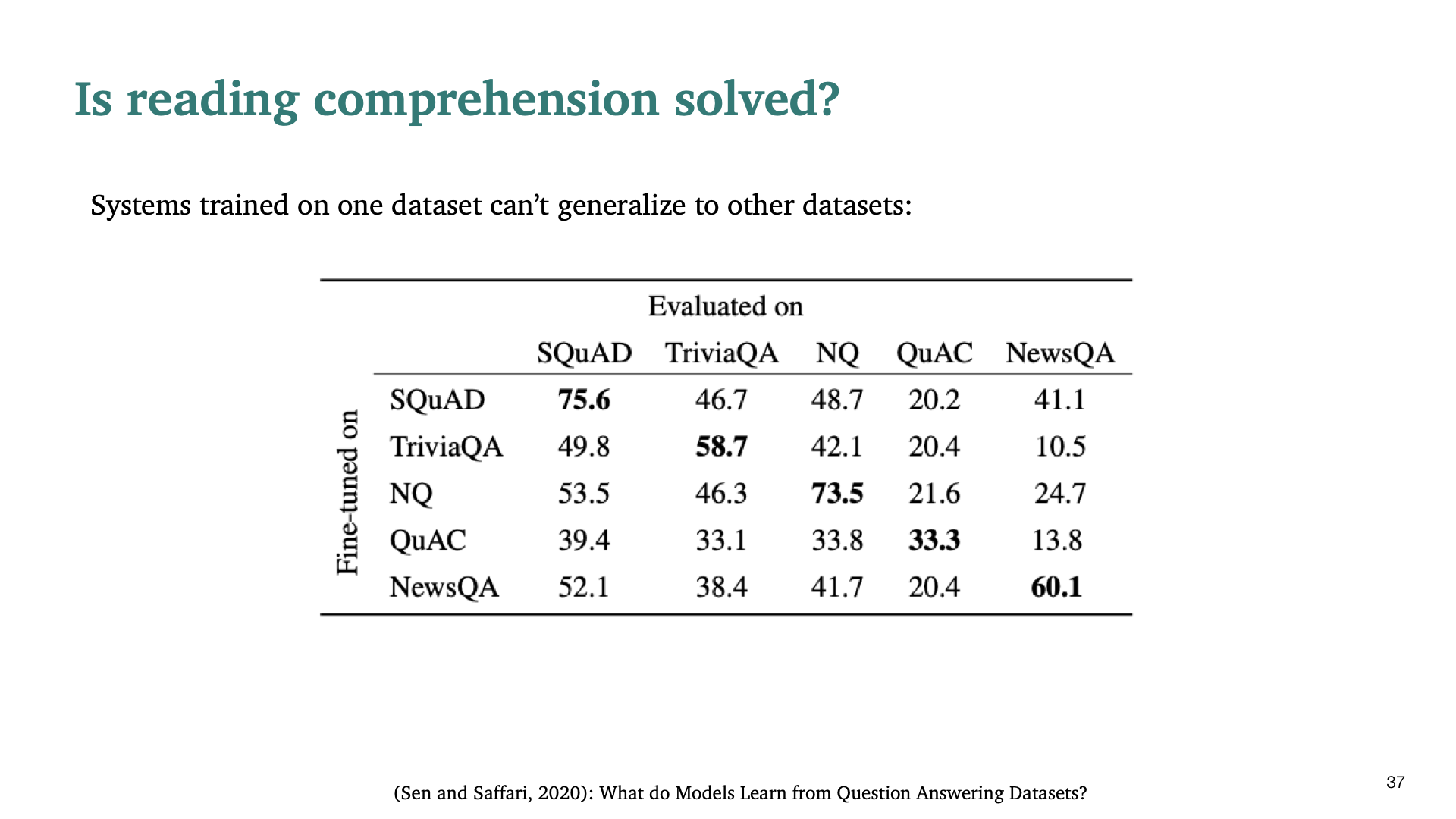
또 다른 근거로, 다른 dataset에 대해서 generalize된 성능을 보이지 못한다는 것이다.

NLP model의 성능에 대한 Checklist paper이다.


이제 open-domain question answering에 관해 설명한다. Reading comprehension과 다르게, 주어진 passage가 있다고 가정하지 않고 단순히 large collection of document만 주어지게 된다. 그래서 실제 answer가 어디 위치하는지 모른다. 이 task의 goal은 어떠한 open-domain question에 대해서도 답하는 것이다. 훨씬 더 어렵지만 더 practical한 problem이다.

위의 문제를 retrieval-reader framework을 이용하여 해결할 수 있다고 2017 wikipedia to Answer open-domain question이라는 논문에서 발표했다. Key idea는 다음과 같다. Question의 text에 대해 retrieve하고, 관련있는 모든 document를 모두 찾아보는 방식으로 해결한다.

위의 모델을 정리해서 설명하면, Retriever = standard TF-IDF (fixed module)이고, Reader가 우리가 지금까지 배운 reading comprehension model이다.
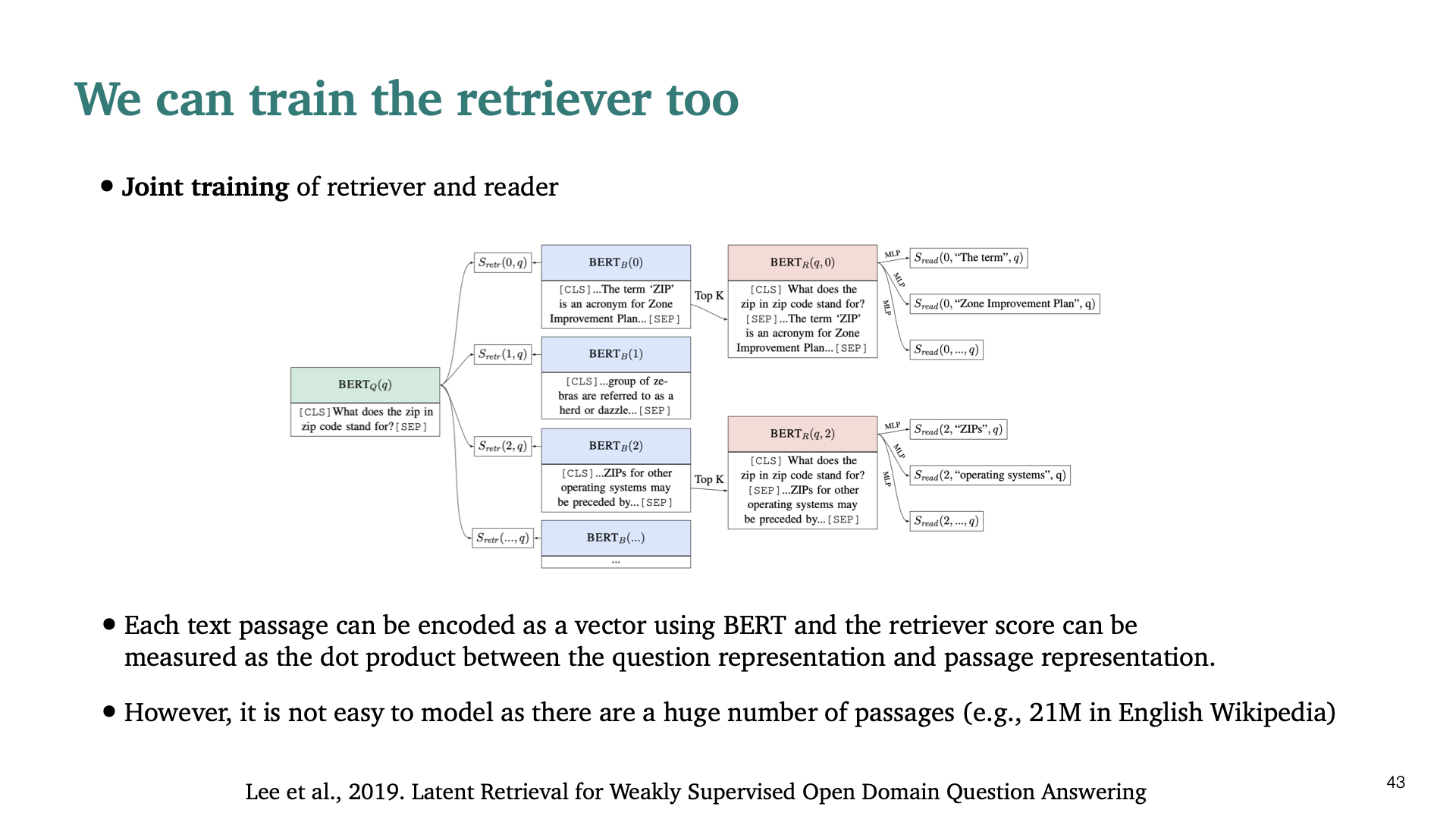
최근 2년동안 이와 관련되어 어떤일이 일어나고 있는지 간략하게 설명한다. 첫번째 아이디어는 retriever part 또한 학습할 수 있다는 것이다. Passage들과 question의 similarity를 계산하여 retriever을 학습한다. 하지만 model 자체가 매우 커지기 때문에 Scalability problem이 있다.
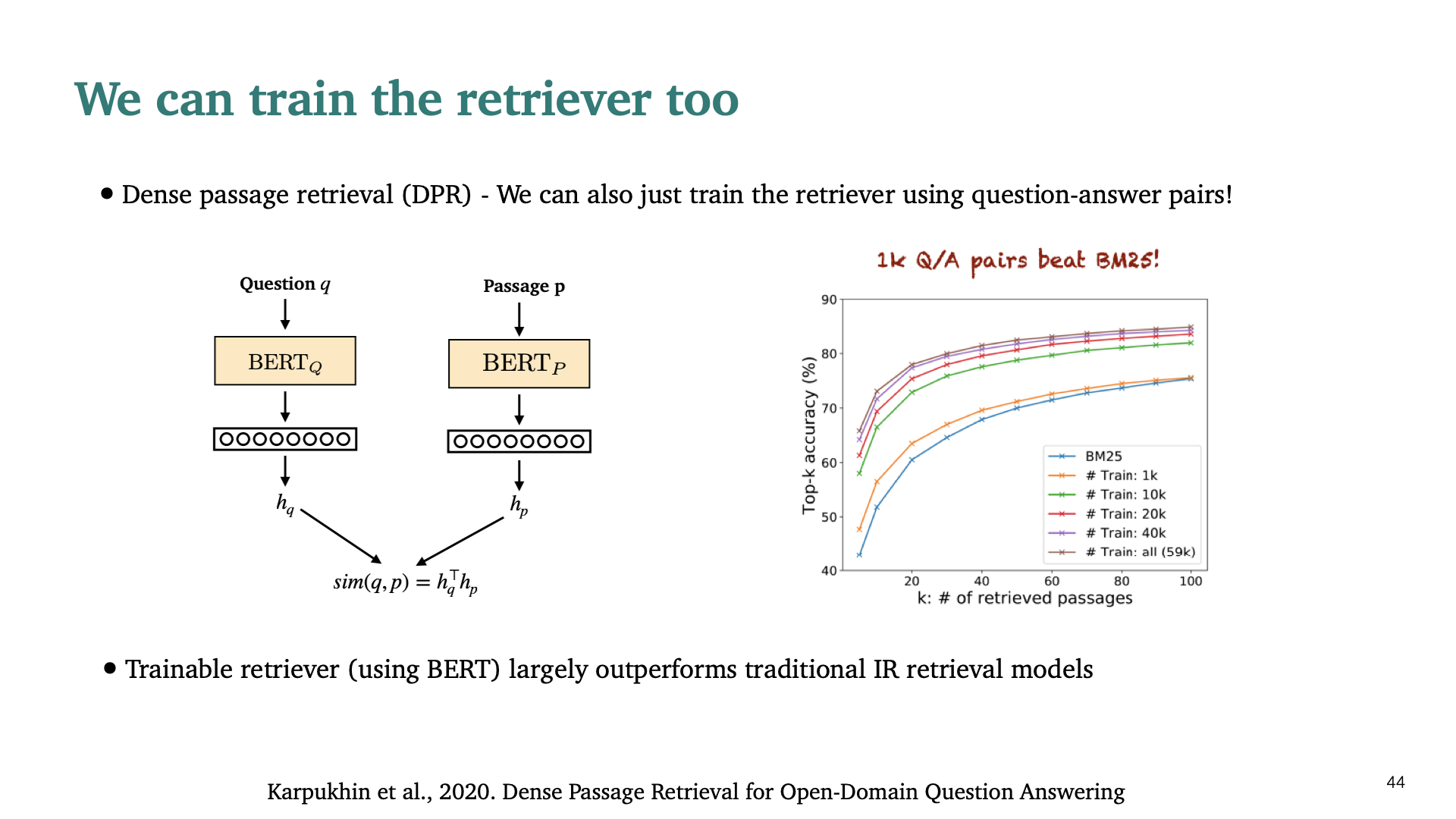
작년에 발표한 논문으로 Dense Passage retrieval 이라는 논문이다. 훨씬 던 간단한 접근법을 사용한다. Question, Answer에 대한 두개의 BERT만을 사용하여 retrieval을 학습할 수 있다는 것이다. 이 모델은 꽤 좋은 성능을 보인다.
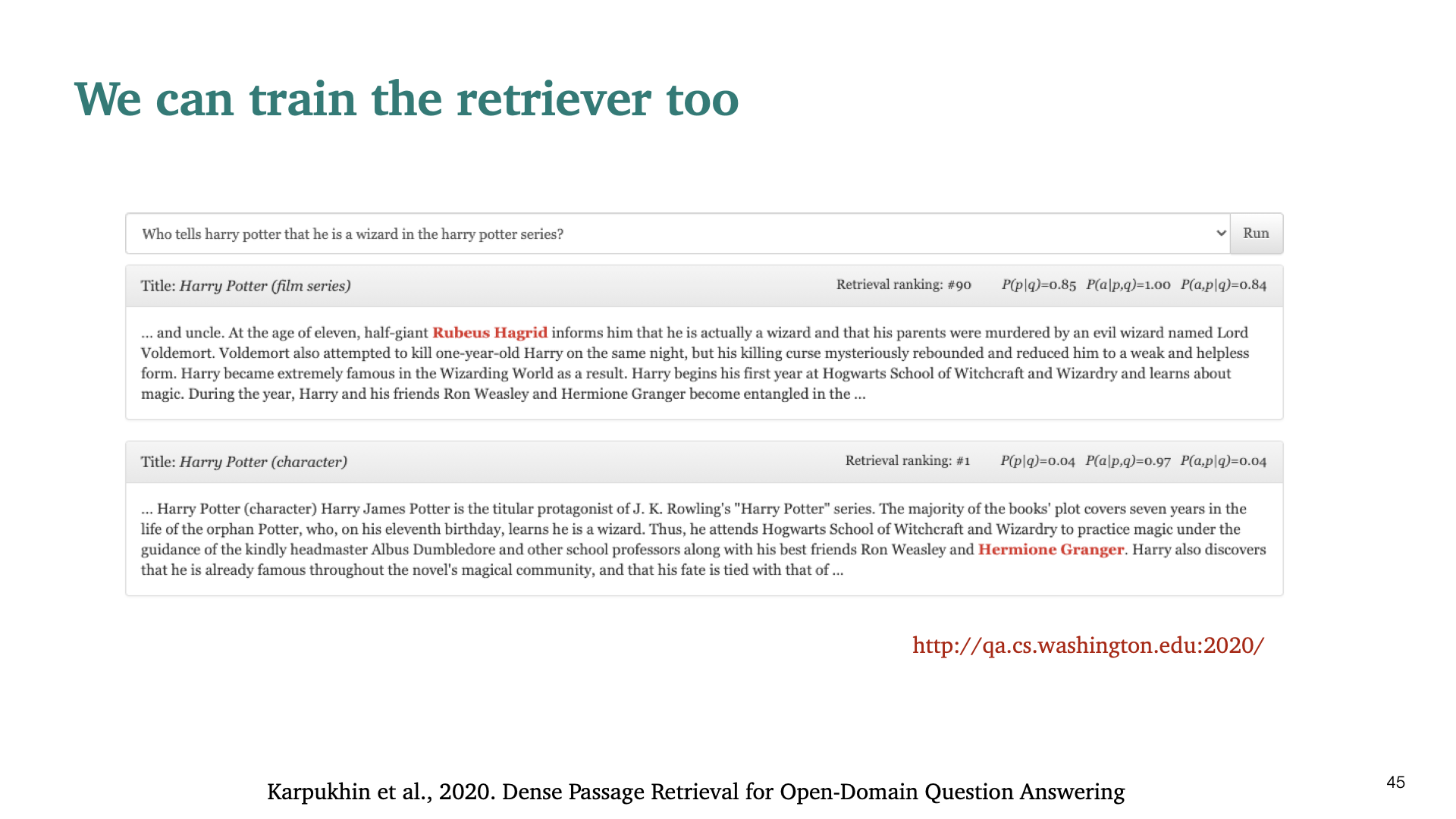
해당 slide에 demo버전이 구현되어 있다.
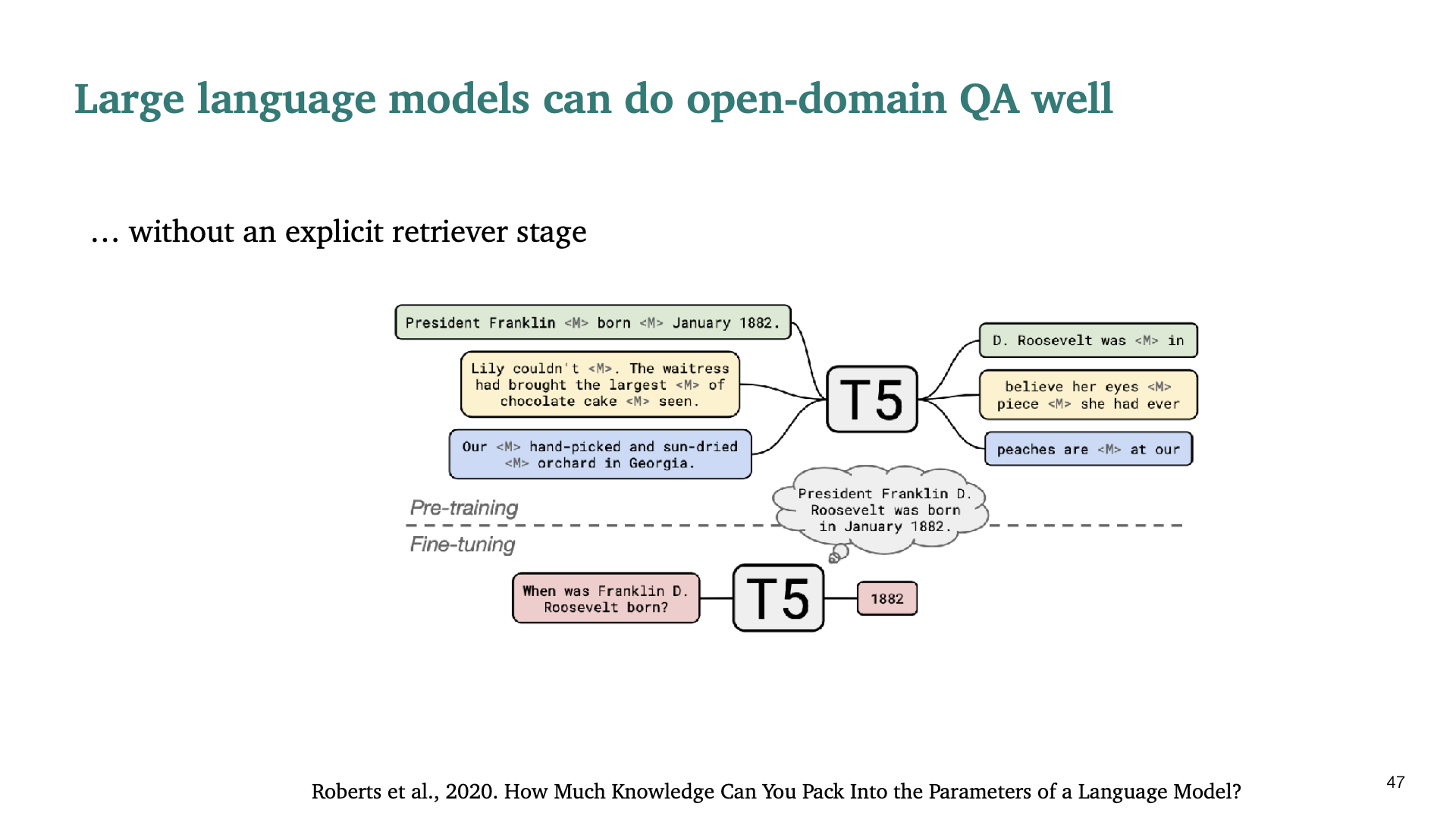
Retriever stage없이도 매우 큰 model을 사용하면 open-domain QA가 가능하다고 말한다. Coastal QA system이라고 불린다.
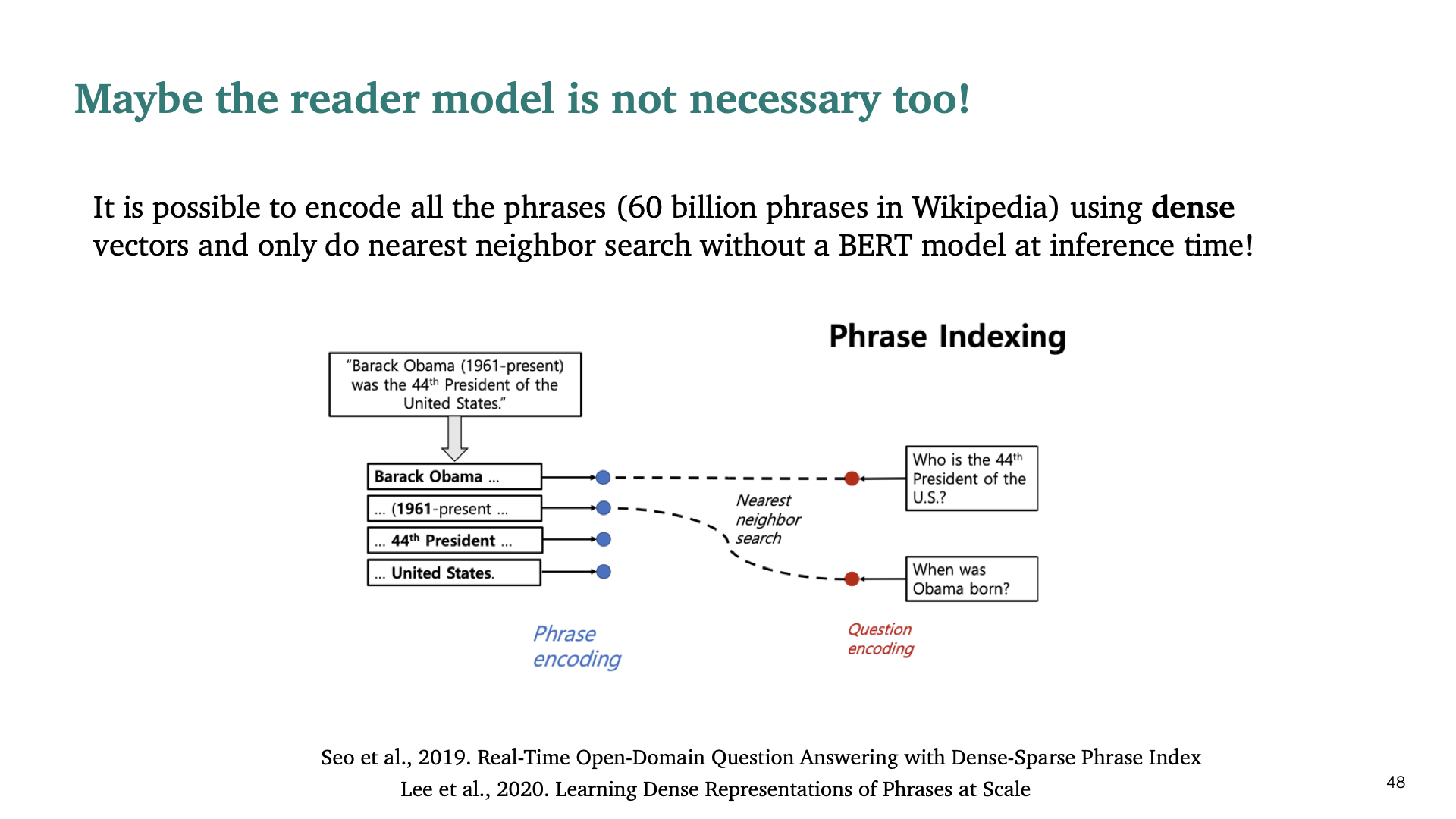
Open-domain Question Answering task에 대해서 reader 모델 자체도 필요없을 수 있다는 논문이다. 위 논문도 BiDAF를 만든 서민준 교수님이 발표한 논문이다. Dense vector로 모든 phrase를 encode한후에 BERT model을 이용하여 nearest neighbor search를 하는 것이다. 단순히 inference time에만 모델을 사용하면 되지만, 매우 expensive하다. 하지만 학습되어 있다면 매우 빠르게 실행시킬 수 있고, CPU에서도 동작 가능하다.