Multitasking in Python
03 Feb 2022
Multitasking in Python Post에서는 Concurrency, Parallelism에 따른 I/O Bound task, CPU Bound task의 성능을 검증하는 내용을 다룹니다. Concurrency와 관련해서는 Threading과 asyncio, Parallelism과 관련해서는 mutliprocessing을 다룹니다.
Concurrency(동시성), Parallelism(병렬성) in Python
동시성과 병렬성에 대해 간단하게 짚고가면 각 정의는 다음과 같다.
동시성(Concurrency): 컴퓨터가 동시에 여러 가지 다른 작업을 처리하는 것처럼 보이는 것을 의미한다. 가령, multi-thread가 동시성의 대표적인 예이다. 빠른 context switching을 통해 동시에 여러가지 task를 실행하는 것처럼 보이게 한다.
병렬성(Parallelism) : 동시에 여러 다른 작업을 실제로 처리 하는 것을 의미한다. multi-process가 병렬성을 갖고있다. CPU 코어가 여러 개인 컴퓨터는 여러 프로그램을 동시에 실행할 수 있다.
동시성, 병렬성을 활용하면 다양한 프로그램 경로나 다양한 I/O 흐름을 이용할 수 있다. 병렬성과 동시성의 가장 핵심적인 차이는 속도에 있다. (CPU bound problem을 기준으로) 서로 다른 두 프로그램이 병렬적으로 실행되면 실제 전체 작업을 하는데 걸리는 시간이 두배 빨라진다. 동시성을 적용한 프로그램은 겉으로 보이기엔 병렬적으로 실행되는 것처럼 보이지만, 걸리는 시간이 단축되지는 않다.
Concurrency in Python
Python에서는 Concurrency를 구현하는 방법이 크게 두가지가 있다.
- threading - Preemptive multitasking
- asyncio - cooperative multitasking
threading - Preemptive multitasking
Operating system이 아무 시점에서 특정 task로 context switch하기 위해 thread가 선점하게 할 수 있다. 이를 preemptive multitasking이라 한다. threading에서는 해당 task로 switch하기 위해 별도의 코드를 작성하지 않아도 되지만, 어떠한 시점에서도 switch될 수 있기 때문에 예상치 못한 문제가 생길 수 있다.
asyncio - cooperative multitasking (non-preemtive)
asyncio에서는 threading과 다르게, task가 context switch하기 위해 준비가 되었을때, os에게 이를 알린다. 이를 cooperative multitasking 이라 한다. 이러한 스케줄링에 대해 별도의 코드를 작성해야한다. 이렇게 함으로써 해당 task로 언제 switch out 됬는지 알 수 있다.
Parallelism in Python
CPU core개수만큼 process를 병렬적으로 돌릴 수 있다. 만약 core 개수 이상의 process로 multiprocess를 한다면, core 개수의 process만 동작하고 나머지는 queue에서 기다린다.
I/O Bound, CPU Bound
Concurrency, Parallelism 두가지 타입의 프로그램에서 큰 차이를 보일 수 있다.
-
I/O Bound Program
I/O Bound한 문제는 external source로 부터 input/output(I/O)를 기다리게 만들기 때문에, 프로그램을 느리게 만들 수 있다. 단순히 CPU 연산을 하는 것 보 다 느리게 만든다. 예를 들어, 프로그램이 file system, network connection에 대한 일을 자주 할때, 프로그램이 느려질 수 있다.
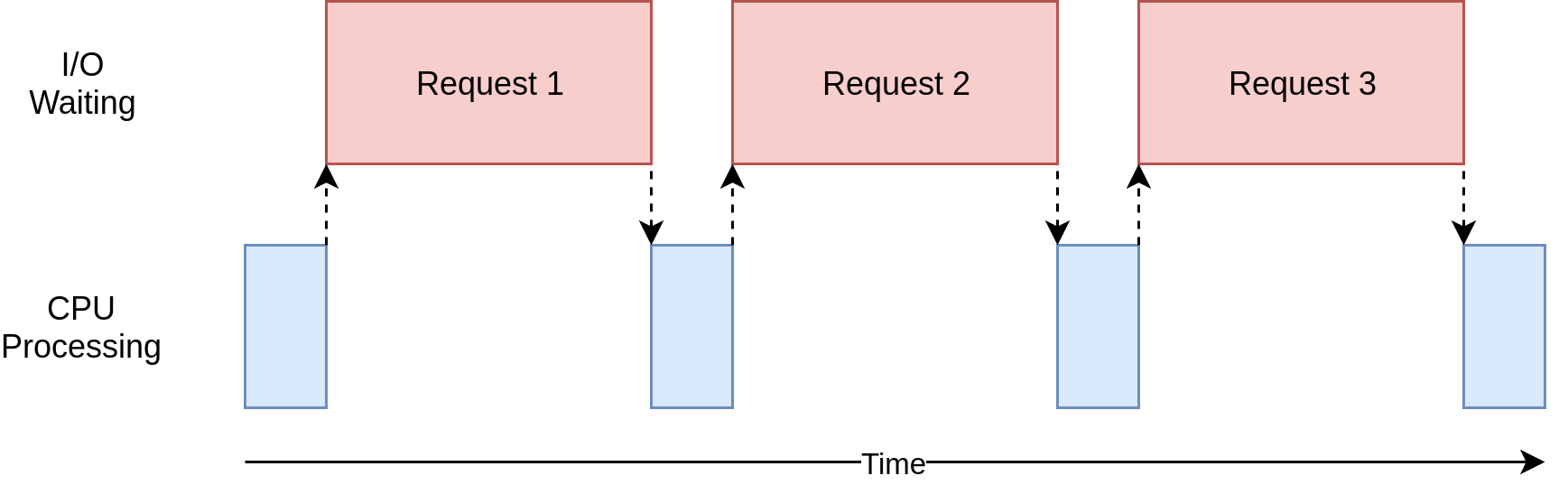
위의 사진과 같은 경우가 I/O Bound한 program이다. 브라우저를 동작시키는 프로세스가 대부분 위와 같이 동작한다. 대부분의 시간을 기다리는데 사용하고, CPU operation에 대해선 그보다 적은 시간을 사용한다. 이러한 devices 혹은 external resource를 기다리는 시간을 줄이는 것이 I/O Bound Program를 빨리하는 방법이다.
-
CPU Bound Program
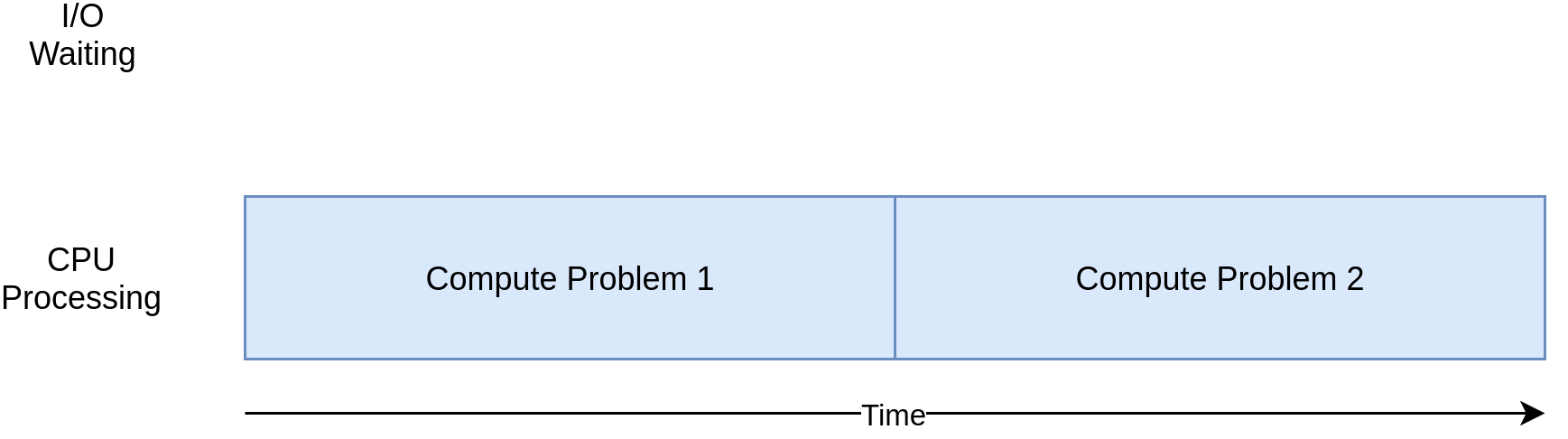
I/O Bound와 반대로, network 또는 file을 접근하는 것 없이, 중요한 cpu 연산을 하는 프로그램을 cpu bound 하다고 한다. 대부분의 시간을 CPU operation을 하는 데에 사용한다. 같은 시간동안 더 많은 연산을 하는 것이 CPU Bound Program를 더 빨리 하는 방법이다.
I/O Bound program에 대해서 동시성, 병렬성에 대한 방법을 차례대로 적용하여 얼마나 시간이 단축되는지 살펴볼 것이다. 또한 CPU Bound program에 대해서도 동시성, 병렬성을 적용하여 시간이 단축되는지 살펴볼 것이다.
How to Speed Up a CPU-Bound Program
Network에서 content를 downloading하는 I/O bound program에 대해 다음과 같은 방법을 이용하여 속도가 얼마나 차이 나는지 살펴볼 것이다.
- Synchronous Version(non-concurrent version)
- threading version
- asyncio Version
- multiprocessing Version
Synchronous Version(non-concurrent version)
download_site 는 url 으로 부터 content를 다운로드 받고, 크기를 출력하는 함수이다. 이때, Session() object을 이용하여 tcp connection을 persist하게 만들어 조금 더 빠르게 다운로드 하였다. (Session에 대한 내용은 다음 post를 참고하면 좋을 것 같다.)
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
def downlaod_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url,session)
if __name__ == '__main__':
sites=["https://www.naver.com"]*100
start_time = time.time()
downlaod_all_sites(sites)
duration = time.time()-start_time
print(f'Download {len(sites)} in {duration} seconds')
위의 tad에 대해 다음과 같이 시간이 걸렸다.
Download 100 in 11.707897901535034 seconds
Synchronous Version은 단순히 순서대로 진행되기 때문에, 다음에 어떤것이 수행될지 쉽게 예측할 수 있다. 하지만 다른 방법에 비해 매우 느리다.
threading version
python에서는 ThreadPoolExecutor라는 개념을 이용하여 threading을 구현한다. multi threading 작업을 시작할 때, 가장 많은 연산을 필요로 하는 작업은 스레드를 시작하는 것이다. ThreadPoolExecutor는 스레드 풀이 필요할 동안 thread를 생성한다. context manager(with)를 사용하여 좀더 가독성 있는 코드를 작성할 수 있다.
Python 3.2 이상에선 ThreadPoolExecutor가 concurrent.futures에 구현되어 있다.
threading을 할때 고려해야 하는 것이 한가지 더 있다. OS가 실행중인 task를 인터럽트하거나, 새로운 task를 실행할때 thread 간에 공유되는 모든 data는 thread-safe 해야 한다. 하지만 requests.Session()은 thread-safe하지 않다. 이를 위해 data를 thread-safe하게 access하는 몇가지 방법이 있다. data의 종류에 따라, 어떻게 그 data를 사용하냐에 따라 전략이 달라진다.
첫번째 방법은 Queue와 같이 thread-safe data structure를 사용하는 것이다. threading.Lock과 같은 low-level을 사용하여 어떤 시점에 대해 하나의 thread만 block of code 또는 bit of memory에 접근하게 하는 방법이다.
Lock, mutex, semaphore의 개념에 대해 간단하게 짚고 가보겠다. lock은 thread synchronization tool로써, 하나의 thread만 해당 코드에 접근할 수 있게 만드는 것이다. 또한 다른 process사이에 공유될 수 없다. mutex는 mutual exclusion lock으로써, lock의 일종이다. lock과 다른 점은 여러 process들 사이에 공유될 수 있다. semaphore는 mutex와 같은 역할을 하지만, n개의 thread가 접근할 수 있게 한다.
두번째 방법은 코드에서 사용한 thread local storage를 사용하는 것이다. threading.local()은 global object처럼 보이게 만들지만, 각 thread에 specific한 object 만들어준다. 만들어진 object이 각 thread에 대한 데이터의 접근을 분리시켜준다. get_session() 이 호출되었을 때, 해당session 이 특정한 thread를 lookup하게 한다. 그래서 각 thread는 single session을 만들어서, 해당 session을 Lifetime동안 사용하게 된다.
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local,"session"):
thread_local.session = requests.Session()
return thread_local.session
def download_stie(url):
session = get_session()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
def downlaod_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_stie,sites)
if __name__ == '__main__':
sites=[
"https://www.naver.com"
]*100
start_time = time.time()
downlaod_all_sites(sites)
duration = time.time()-start_time
print(f'Download {len(sites)} in {duration} seconds')
위의 코드는 다음과 같은 시간이 걸렸다.
Download 100 in 3.0990958213806152 seconds
위의 synchronous version(non-concurrent)한 것보다 훨씬 빠르다.
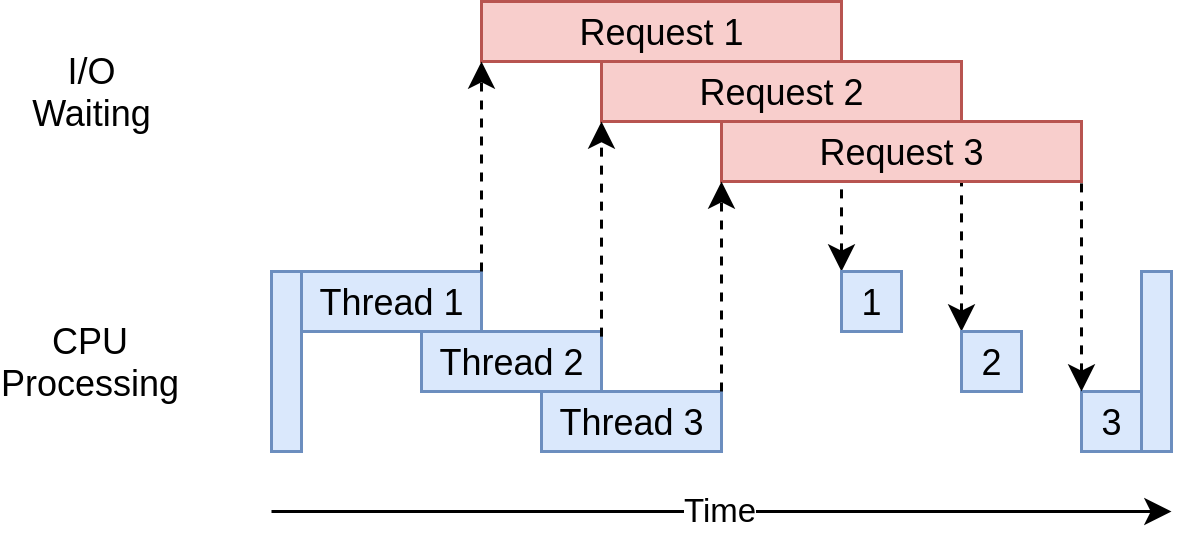
multiple-thread들이 multiple-open request를 하였다. waiting time에 대해 overlap된 것을 확인할 수 있다. threading의 문제점은 위에서 언급했듯이, thread들이 interaction하는 것을 detect하기 어렵다는 것이다. race condition과 같은 예상치 못한 문제점이 일어날 수 있다.
asyncio Version
asyncio Basic
python에서의 asyncio의 general한 concept은 event loop이라고 불리는 python object으로 설명된다. event loop은 각 task를 어떻게, 언제 실행할지 제어한다. 실제로는 event loop은 여러가지 state에 있을 수 있지만, 두가지 state인 ready state와 waiting state에 대해서만 고려한다고 가정하자.
- ready state : ready to be run
- waiting state : waiting for some external thing to finish. (ex network operation)
event loop은 state마다의 list of task를 갖는다. 현재는 2개의 state만을 고려하므로, 두가지 list of task를 갖고 있다. event loop은 다음과 같이 동작한다.
- ready task중 하나를 선택하여 run된다.
- running task가 해당 task를 완료하고 (혹은 할당된 시간을 모두 소지한 후) event loop으로 control을 다시 반납한다.
- event loop은 해당 task를 ready list 또는 waiting list에 넣는다.
- event loop은 waiting list를 순회하며 I/O operation의 완료에 따라 ready state로 변경되는 task가 있는지 확인한다.
- 모든 task가 올바른 List로 sort되었다면, 다시 1번을 수행한다.
asyncio의 중요한 point는 running task가 동작의 완료했을 때만 control을 event loop에 반납한 다는 것이다. 즉, operation 동작 중에 interrupt되지 않는다. 이것이 threading보다 asyncio가 resource sharing에 더 적합한 이유 중 하나이다. asyncio 에서는 thread-safe와 같은 문제를 고려하지 않아도 된다. asyncio 의 동작에 대해 더 궁금하다면 다음 포스트를 참고해도 좋을 것 같다.
async and await
위에서 언급한바와 같이 await을 이용하여 event loop에 control을 반납할 수 있다. 예를 들어, 어떤 function call을 await한다는 것은 function을 실행 마치고 나서, control을 반납하는 것을 의미한다.
async는 await을 사용하여 function을 정의하겠다는 flag로 생각하면 이해하기 쉽다. 다른 방식으로도 사용이 되는데, async with을 사용하여 await하는 object으로부터 context manger를 만드는 것이다. 이 방법 또한 context manager를 flag하는 concept은 동일하다.
import asyncio
import time
import aiohttp
async def downlaod_site(session,url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length,url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks=[]
for url in sites:
task = asyncio.ensure_future(downlaod_site(session,url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites=[
"https://naver.com"
] *100
start_time =time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Download {len(sites)} sites in {duration} seconds")
위의 코드는 다음과 같은 시간이 걸렸다.
Download 100 sites in 1.2984209060668945 seconds
downlaod_all_sites() 함수 부분이 threading에서의 코드와 다른 부분이 있다. 모든 Task가 하나의 thread에서 실행되기 때문에, 각 task들은 session을 공유할 수 있다. context manager 안에서, asyncio.ensure_future()를 이용하여 list of task를 만든다. 모든 task가 생성되었을때, asyncio.gather()을 이용하여 다른 task가 완료될 때까지 session이 alive하게 해준다. asyncio의 장점 중 하나는 threading보다 scaling면에서 월등히 좋다. 각 task는 더 적은 resource를 필요로 하고, thread보다 생성하는 데 더 적은 시간이 걸린다.
__main__() 에 있는 get_event_loop()과 run_until_complete() code가 asyncio가 언제 event loop을 시작하여 어떤 task를 실행시킬지 알려준다. Python 3.7에서는 두개의 함수를 asyncio.run()을 통해 같은 동작을 구현할 수 있다.
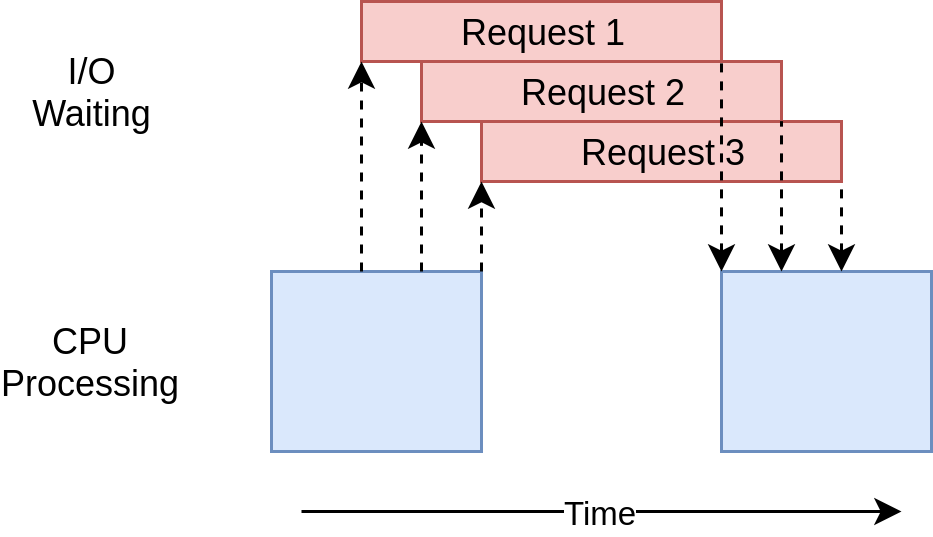
하나의 thread에서 모든 I/O request가 진행되는 diagram이다. async의 문제점에 대해 얘기해 보면, 첫번째로 asyncio의 이점을 모두 사용하기 위해 async version의 special library를 사용해야 한다는 것이다. 예를들어 asyncio version에서는 requests를 사용하지 않고, aiohttp를 사용했다. 또 하나의 문제점은 하나의 task가 cooperate하지 않으면, cooperative multitasking의 이점이 없어진다는 것이다. 하나의 task가 오랫동안 processor를 hold하게 되면 starvation 문제가 일어날 수 도 있다. 코드에서의 조금의 실수가 큰 문제를 일으킬 수도 있다.
multiprocessing version
위의 concurrency 방법에서는 single CPU만을 사용했는데, 이는 CPython의 현재 디자인된 구조와 GIL(Global Interpreter Lock)과 연관이 있다. (본 post에서는 GIL의 개념을 다루지 않을 것이다.)
mutiprocessing standard 라이브러리는 여러개의 CPU로 코드를 돌릴 수 있게 해준다. high-level 관점에서 설명해보자면, 각 cpu당 새로운 Python interpreter instance를 만들어서 프로그램의 부분을 나눠서 실행하게 된다. Python interpreter에서 새로운 thread를 생성하는 것 만큼, 새로운 python interpreter instance를 만드는 것 또한 느리다. 매우 무거운 operation으로, 여러 restriction, limitation이 뒤따른다. 하지만 올바르게 작성되었다면, 성능 면에서 매우 큰 차이를 보인다.
download_all_sites()에서 download_site()를 단순히 반복적으로 호출하지 않고, multiprocessing.Pool object을 만들어 download_site, iterable object인 sites를 map시킨다. Pool은 여러개의 Python interpreter process를 만들고, 각 process는 specified function과 iterable에 있는 item들을 실행한다. main process와 다른 process 사이의 communication은 multiprocessing module을 통하여 다뤄진다.
Pool object에 대해 설명하면, 첫번째로 Pool에서 몇개의 process가 생성되는지 specify하지 않았다. Optional parameter이지만, multiprocessing.Pool()에서는 default parameter로 컴퓨터에 있는 CPU 개수가 들어간다. ( python docs 를 참고해보면 좋을 것 같다.)
processes is the number of worker processes to use. If processes is
Nonethen the number returned bycpu_count()is used. If initializer is not None then each worker process will call initializer(initargs) when it starts.
multiprocessing.Pool 의 parameter로, initializer=set_global_session 로 들어갔다. Pool에 있는 각 process는 own memory space를 갖게 된다. 이때, session object을 share하지 않고 매번 새로운 session을 만든다면 느려질 것이다. global_session을 initialize하여, 각 process이 전역 변수로 선언된 global_session에 접근할 수 있게 하는 것이다.
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f'{name}:Read {len(response.content)} from {url}')
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site,sites)
if __name__ == '__main__':
sites =['https://naver.com']*100
start = time.time()
download_all_sites(sites)
duration = time.time() - start
print(f"Download {len(sites)} in {duration} seconds")
위의 코드는 다음과 같은 시간이 걸렸다.
Download 100 in 3.294051170349121 seconds
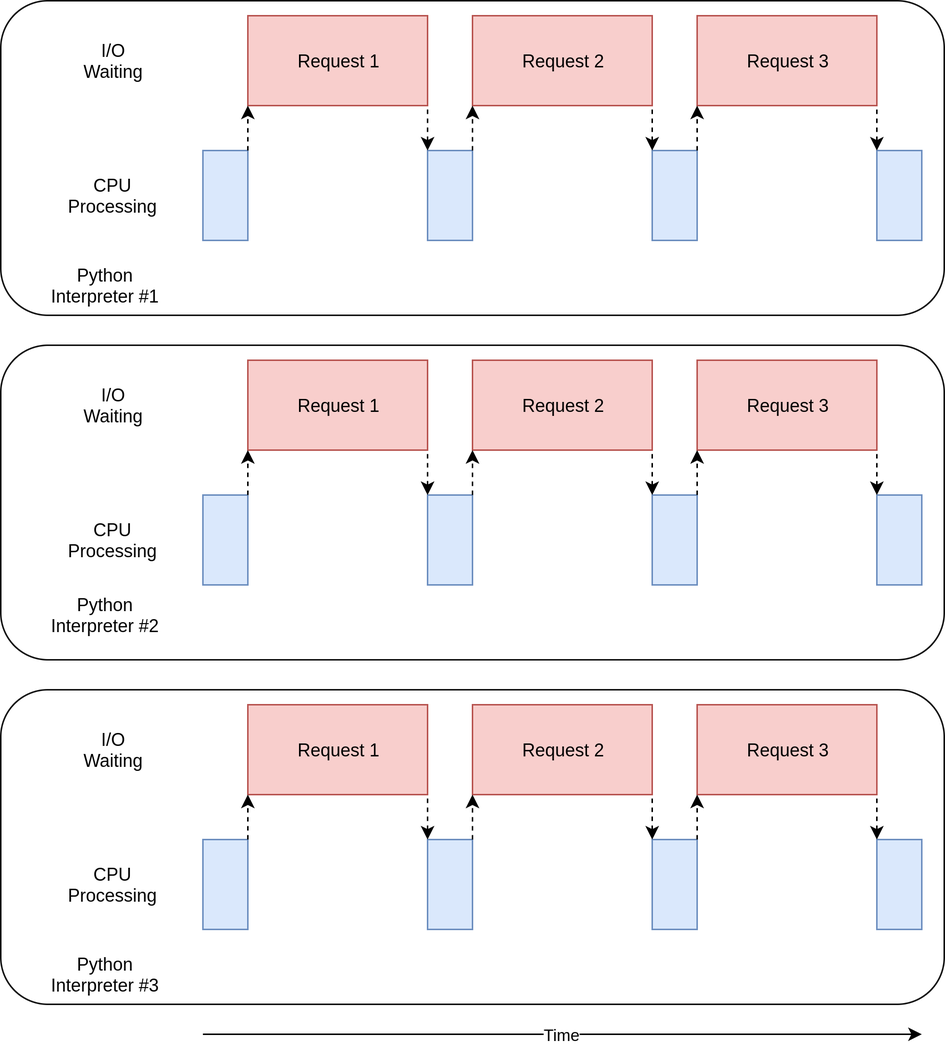
위 사진은 multiprocessing에 대한 diagram이다. Multiprocessing 방법은 io-bound보다 cpu-bound한 problem에서 훨씬 좋은 성능을 보인다.
How to Speed Up a CPU-Bound Program
위의 IO bound problem은 대부분의 시간을 network와 같은 external operation에 사용하였다. CPU bound problem은 대부분의 시간을 I/O operation은 매우 조금하고, 대부분의 시간을 cpu operation에 사용한다. 예를들어 sorting, arithmetic operation과 같은 것들이 있다. CPU bound problem의 예제로 0부터 주어진 숫자까지의 제곱 합을 구하는 연산을 해볼 것이다.
CPU-Bound Synchronous version
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__" :
numbers = [5_000_000 + x for x in range(20)]
start = time.time()
find_sums(numbers)
duration = time.time()-start
print(f'Duration {duration} seconds')
위의 코드는 다음과 같은 시간이 걸렸다.
Duration 7.588207721710205 seconds

위 사진은 Synchronous version의 diagram이다.
CPU-Bound threding version
cpu bound problem을 thread, asyncio 로 작성하면 얼마나 속도 향상이 있을까? 정답은 전혀 없거나 혹은 더 느려진다. I/O bound problem에서는 대부분의 시간이 io operation을 기다리는데 사용했기 때문에, threading과 asyncio가 overlap을 가능하게 해서 속도를 향상시켰다. 하지만 CPU bound problem에선 기다리는 시간이 없다. 또한 thread, asyncio 모두 하나의 process에서 돌아가기 때문에 non-concurrent code (synchronous code)와 다른 것이 없고, thread, asyncio task를 생성하는데 추가적인 시간이 걸릴 뿐이다. 그래서 synchronous version보다 오래 걸린다.
import concurrent.futures
import time
def cpu_bound(number):
return sum(i*i for i in range(number))
def find_sums(numbers):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(cpu_bound,numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start = time.time()
find_sums(numbers)
duration = time.time() - start
print(f'Duration {duration} seconds')
위의 코드는 다음과 같은 시간이 걸렸다.
Duration 8.307791233062744 seconds
CPU-Bound multiprocessing version
import multiprocessing
import time
def cpu_bound(number):
return sum(i*i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound,numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start = time.time()
find_sums(numbers)
duration = time.time() - start
print(f"Duration {duration} seconds")
위의 코드는 다음과 같은 시간이 걸렸다.
Duration 3.1328768730163574 seconds
당연하게도 가장 빠르다. multiprocessing에서 생길 수 있는 문제는 각 processor에 problem을 split하기 어려운 경우엔 사용하기 어렵다는 것이다. 또한 많은 경우 process 사이에서 communication 하는 것을 요구한다. 가령 pickle module을 사용하여 serialization을 통한 communication을 해야할 수도 있다. 이러한 경우 synchronous version 보다 좀 더 복잡성이 생길 수 있다.
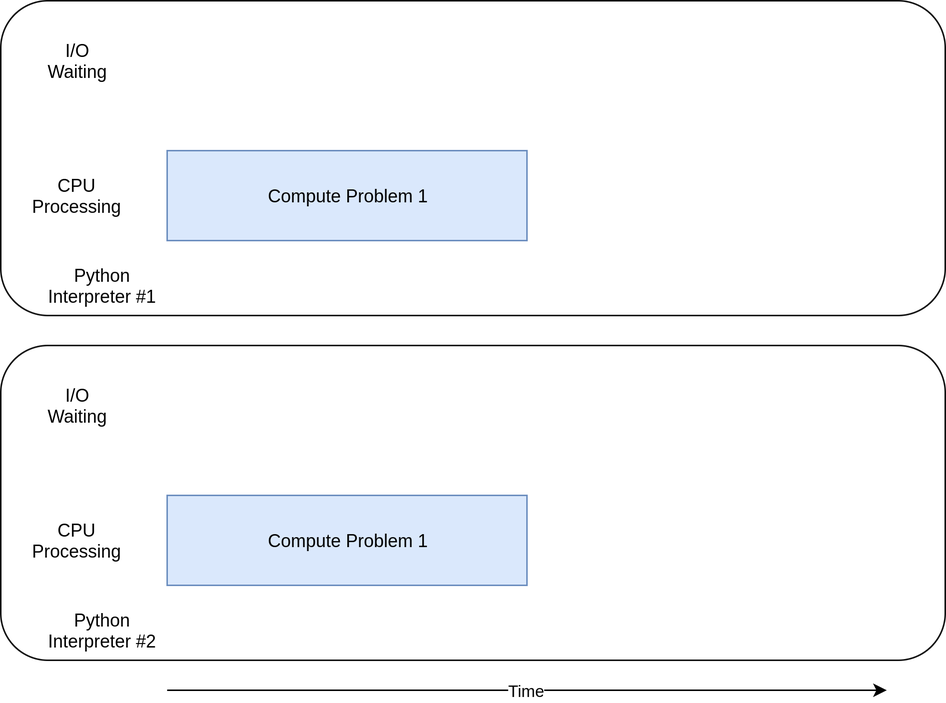
위 사진은 mutliprocessing에 대한 diagram이다.
When to Use Concurrency
Donald Knuth는 다음과 같이 말했다. “Premature optimization is the root of all evil (or at least most of it) in programming.” 즉, Concurrency가 필요한지 먼저 생각해봐야하고, 그 다음 cpu bound한지, io bound한지 봐야한다. CPU bound의 경우, multi processing을 사용하면된다. IO bound의 경우 rule of thumb은 asyncio를 사용할 수 있는 경우 이를 사용하고, threading은 꼭 사용해야하는 경우에만 사용하면 된다. asyncio version의 library를 support하지 않는 경우를 제외하곤 대부분의 경우 asyncio가 가장 좋은 속도를 보여준다.
reference
- real python concurrency (해당 post의 image 출처는 real python link입니다.)
- Session Objects
- What is the difference between lock, mutex and semaphore?
- Python pool map and choosing number of process