(Winter 2021)|Lecture 10 Transformers and Pretraining
26 Jan 2022
Transformer를 기반으로 하는 pretrained model에 대해 배운다. 기존의 Transformer는 Encoder - Decoder로 이뤄진 모델이다. GPT-1,2 모델은 pretrained Decoder만을 사용한다. 이때 GPT2는 truncating distribution of LM이라는 방법을 사용하여 pretrain한다. BERT는 pretrained Encoder를 사용한다. 이때, BERT는 Masked Language Modeling을 사용하여 pretrain한다. BERT의 variant로써, RoBERTa, spanBERT 또한 간단하게 배운다. T5 모델은 Encoder - Decoder 구조를 사용하는데, span-corruption이라는 방법을 사용해 BERT와 다르게 여러길이의 token을 예측하는데 사용한다. 마지막으로는 GPT3를 배우는데, in-context learning에 대해 간단하게 언급한다.
Lecture Plan
- A brief note on subword modeling
- Motivating model pretraining from word embeddings
- Model pretraining three ways
- Decoders
- Encoders
- Encoder-Decoders
- Interlude: what do we think pretraining is teaching?
- Very large models and in-context learning

어느정도의 큰 크기의 fixed vocab이 있다고 가정했다. Word2Vec과 같은 것을 학습시켜 이러한 fixed vocab을 만들었다. trainig time에 보지 못한 novel word들에 대해서는 single UNK token으로 맵핑시켰다. 예를들어, taaaaasty와 같은 variations에 대해 모델은 very tasty라고 인식하지 못하고 UNK token으로 맵핑시킨다. misspellings에 대해서도 같은 동작을 한다.
그래서 결론은 individual sequence of character에 대해 각 단어를 uniquely하게 인식하여 parameterize하는 본래의 방식은 잘못되었다는 것이다.

이러한 finite vocabulary는 영어 뿐만 아니라 많은 언어에서 less sense하다. 대부분의 언어는 complex Morphology(structure of words)로 표현된다. Complex Morphology를 갖고 있다는 의미는 긴 문장이 있을때, 더 복잡한 단어들과 하나의 단어가 덜 나타난다는 것을 의미한다. 즉, UNK로 맵핑되는 단어들이 많아진다는 것을 의미한다.
Swahili(스와힐리어)는 수백개의 conjugation(동사 활용형)을 갖고 있다. sentence에 대해 각 conjugation은 중요한 정보를 담고 있다. 스와힐링어는 그 conjugation들이 verb의 prefix, suffix에 대응되고, 이러한 것을 inflectional morphology라고 한다. 즉, 저 table에 있는 수많은 모든 단어를 parameterize하는 방법은 정답이 아니라는 것이다.

Subword modeling은 기본적으로 2가지 option의 중간을 선택한 모델이다. 첫번째 option은 모든 것을 individual word으로 보는 방법이다. 두번째 option은 단어가 아닌 character로 보는 것이다. (이때, neural network는 sequence of character를 입력으로 받고, 어떻게 단어를 구성하는 어떤 의미인지 학습한다.)
sub word model의 general한 의미는 word level 아래의 internal structure of word를 보는 것이다. Sub word model 중 하나인 Byte-pair encoding도 기존과 동일하게 training data로부터 vocabulary를 학습한다. 이때, greedy algorithm을 이용하여 학습한다. end-of-word symbol을 포함한 character로 학습을 시작한다. 이때 가장 많이 등장하는 adjacent character들을 새로운 sub word로 대체한다. 이 과정을 desired vocab size가 될때 까지 반복한다.
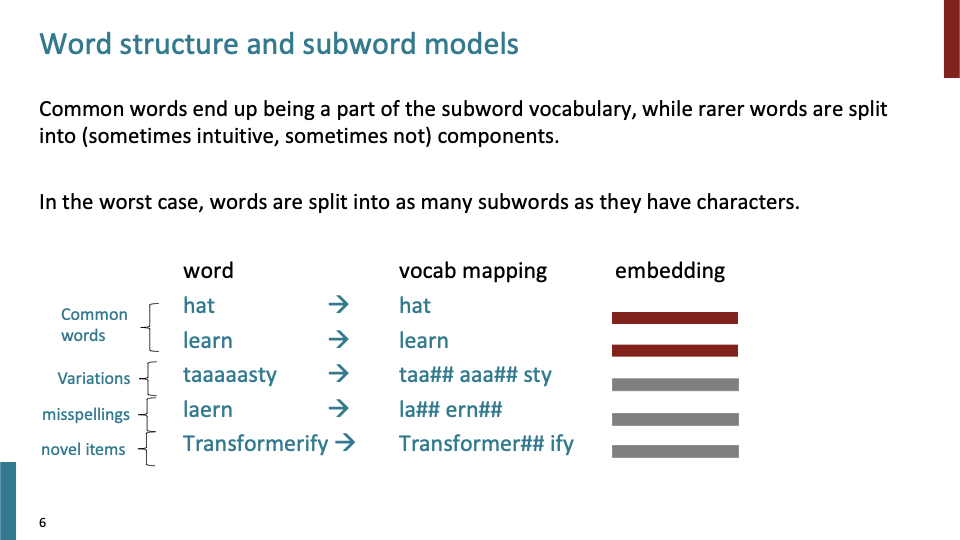
보지 못한 단어 (’taaaaasty’)에 대해, taa aaa sty와 같이 split이 가능하고, 신경망이 이를 학습할 것이다. (영어에선 emphasis를 위해 chain-vowels를 사용한다는 것을)
misspelling 또한 단순히 UNK로 보는 것이 아니라 split되어 모델이 어떤 방식으로든 다룰 수 있게 된다. novel items의 경우에도 subword로 split하여 다룰 수 있다. Transformer + ify가 morphology적으로 말이 된다고 할 수는 없지만, derivational morphology 관점으로 보면 말이 된다.
이제 부터 Pretrained transformer에서 word에 대해 설명할 때, word는 full word 혹은 sub word일 수 있다.
학생 질문 Q) 위의 slide에서 hashtag #가 무엇을 의미하는가?
A) #는 해당 subword가 word의 끝이 아니라는것을 의미한다. #가 없다면 seperated word를 의미한다. sub##word, sub##marine이 그 예시이다.

2번째로, word embedding으로 부터 model pretraining에 대해 알아보자.

word2vec을 사용할때의 문제점은 neighbors를 보지 않는다는 데에 있다. 위 문장에서 record는 다른 의미를 주지만, word2vec에서는 같은 embedding을 사용한다. 지금 부터 할꺼는 사실 word2vec으로부터 학습하는 것과 크게 다르지는 않다. ( word2vec은 each unique word에 특정 vector를 학습시킨 작은 모델이라고 할 수 있다.)
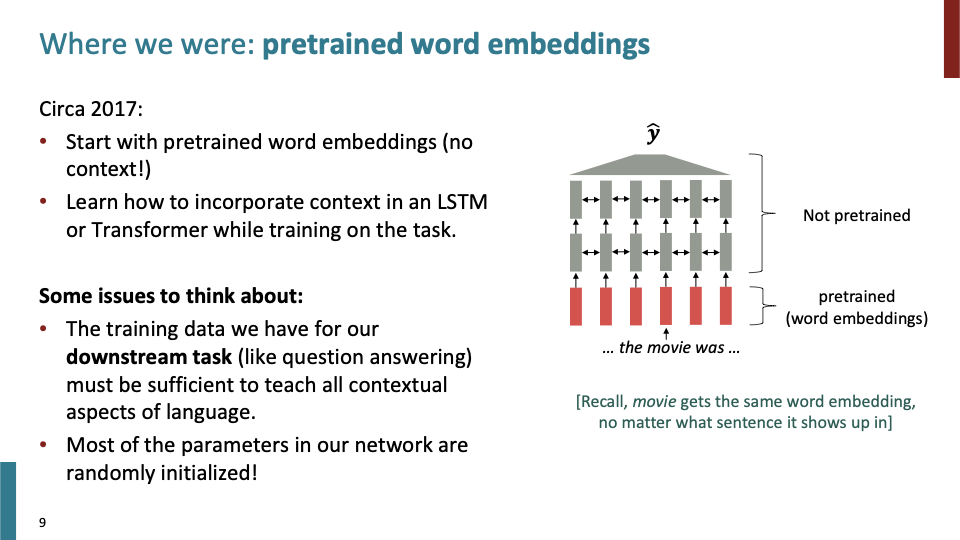
pretrained word embedding에 대해 살펴보자.먼저, context 없이 각 단어에 대한 word2vec embedding으로 시작한다. 그다음 pretrained를 거쳐, LSTM, Transformer를 활용하여 context를 incorporate하는 방법을 학습한다.
여기서 몇가지 생각 해봐야하는 것이 있다. Downstream task에 대해 contextual aspect of language를 학습할만큼 충분한 데이터가 있어야 한다. 또한 대부분의 parameter들은 랜덤하게 initialize되어 있어서, 만약 데이터가 적다면 context를 incorporate하지 못할것이다.
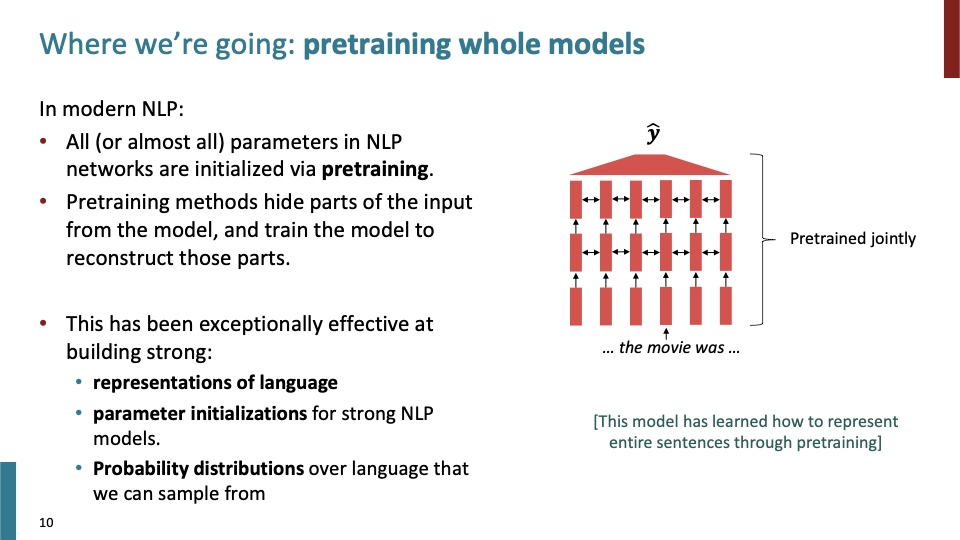
그럼 이제 pretrained Whole model에 대해 살펴보자. 대부분의 NLP network은 pretraining으로 부터 parameter들을 update한다. Pretraining method들은 model로부터 input의 일부분을 숨기고 그 부분들에 대해 model이 reconstruct하도록 학습한다.
그러면 이것과 word2vec을 어떻게 연결하여 설명할까? word2vec에서 center word에 대한 embedding을 학습하는 것을 보면, 그 center word에 주변 단어들에 대해 hide하고, 그 주변 단어들에 대해 predict하는 것에 따라 학습된다. 즉, word2vec 또한 pretraining을 하는 종류로 볼 수 있다.
Whole model pretraining이 word2vec과 다른 점은 특정 word embedding에 대해 학습하는 것이 아니라, parts of sequence를 숨기고 학습한다는 것이다. 뒤에서 더 자세하게 배운다. 위의 신경망 그림 전체가 jointly하게 pretrained되어 있다. (label을 예측하는 마지막 Layer를 제외하고)
Pretraining Whole Model은 Representations of language, parameter initializations, Probability distribution에 대해서 매우 효과적이었다. 이 세가지 방법은 pretrained을 사용하는 대표적인 방법이다.
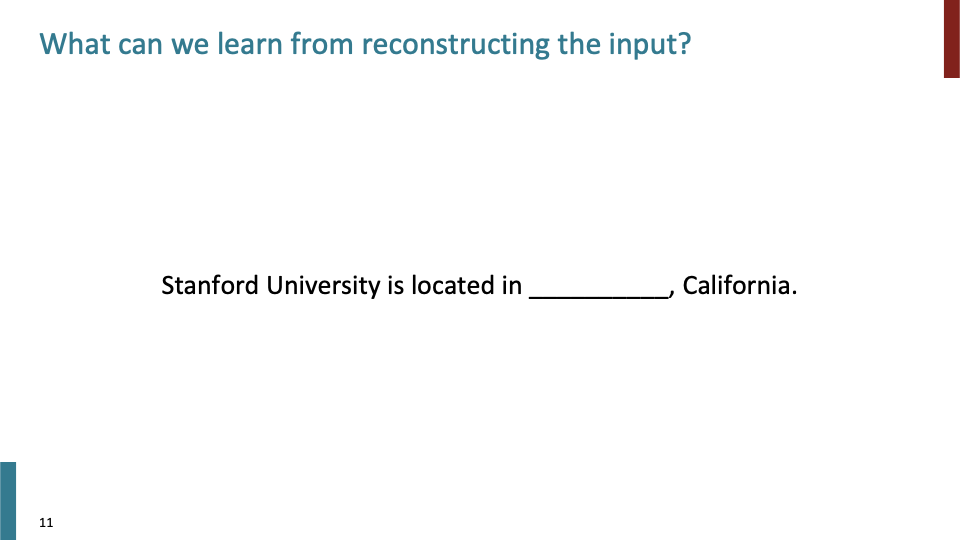
input의 일부분을 제거한뒤, 제거한 부분을 recreate하라는 방식으로 reconstruct한다.

context에서 나타날 수 있는 synthetic thing을 학습한다.

her과 단어가 올 수 있다. 위 예시에선 entity사이의 connection을 학습할 수 있다.

이 예시에선 하나의 single correct answser이 없지만, 이러한 종류의 것들에 대한 distribution을 학습할 수 있다. lexical semantic category of things을 학습한다고 할 수 있다.

이 예제는 sentiment과 관련된것을 학습하게 해준다. 언어에서 sentiment를 어떻게 나타내는지, sentiment analysis와 유사하다.

이 예시는 spatial location에 대해 추론할 수 있는 것을 학습하게 해준다. into, next to, 어디를 left할까와 같은 basic sense of reasoning이다.

위 sequence는 fibonacci 수열인데, 이 또한 모델이 학습할 수 있다.
학생 질문 Q) input training data에 대해 pretraining을 할때 Overfitting되는 Risk에 대한 질문.
A) very Large model을 사용하면, risk of overfitting이 될것이라 생각해볼 수 있다. 일단, pretraining을 하기위해선 정말 큰 dataset이 필요하다. 학습을 하면서 perplexity을 evaluate해볼 수 도 있고, 사실 실제로는 매우 complex interaction을 학습하는 것에 대해 model은 underfitting하다. 그래서 더 큰 모델이 필요하다. 이와 관련해서 BERT를 말할것인데, BERT에서의 interesting result는 데이터에 대해 overfit이 아니라 undefit하다는 것이다. 정리하면, tons of data (English)에 대해 model은 overfit하지 않고, underfit한다. 그래서 더큰 모델이 필요하다.
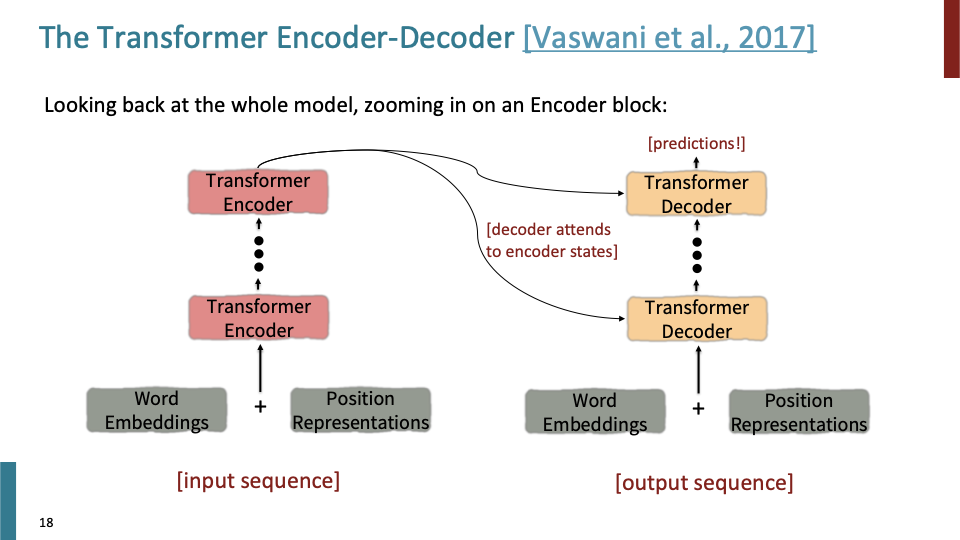
이제, specific pretrained model, specific pretrained method에 대해 알아볼 것이다. Encoder - Decoder에 대해 간단하게 훑고 넘어가겠다.
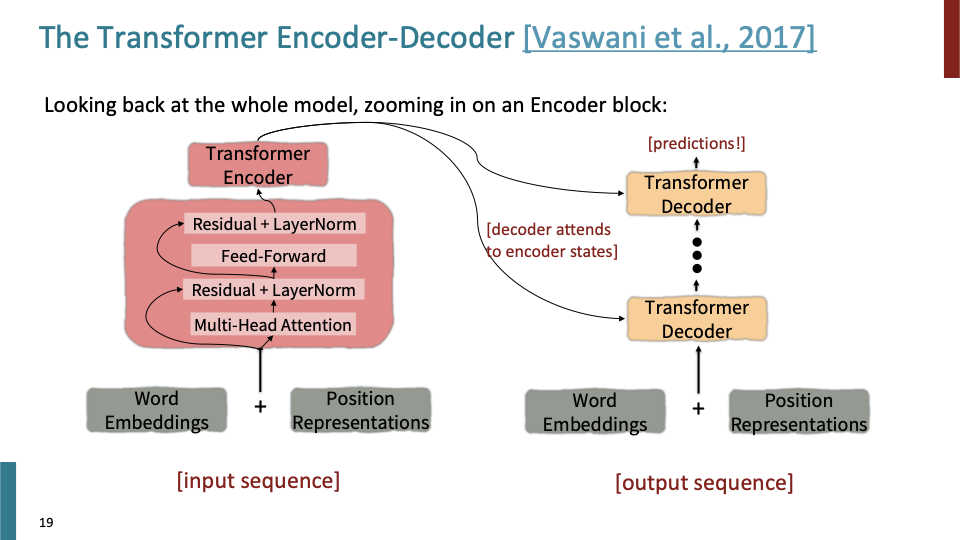
Encoder에 있는 sub-layer(sub module)에 대한 그림이다.
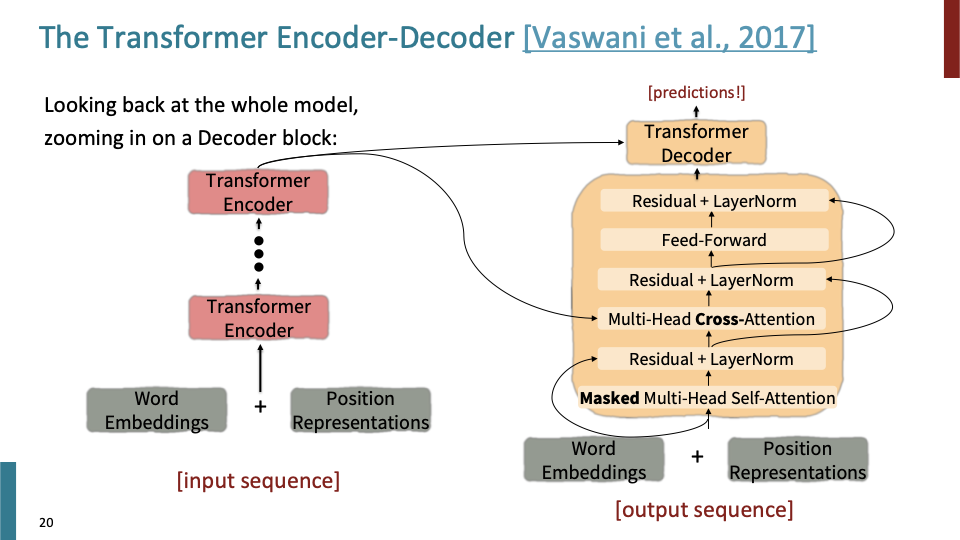
Decoder에 있는 sub-layer(sub module)에 대한 그림이다.
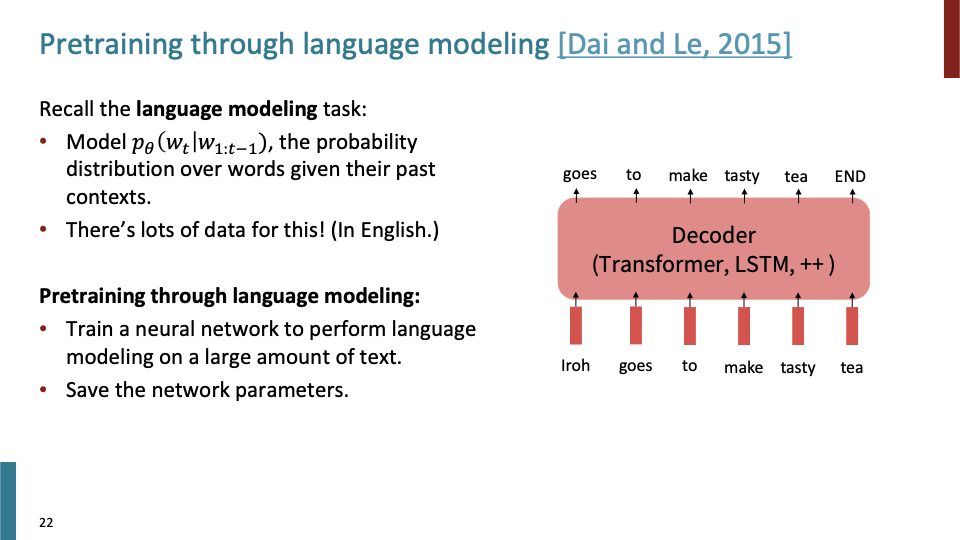
LM을 통한 pretraining을 살펴보자. LM에 간단한 recap을 해보면, 주어진 index $t$에 대해, $t$이전의 단어들이 모두 주어졌을때, past words에 대한 distribution을 계산하게 된다. 사실 LM을 통해 model을 pretraining하는 것은 이전에 LM task하는 것과 다른 것이 없다. 그 pretrained model로 다른 task에 사용할 뿐이다.
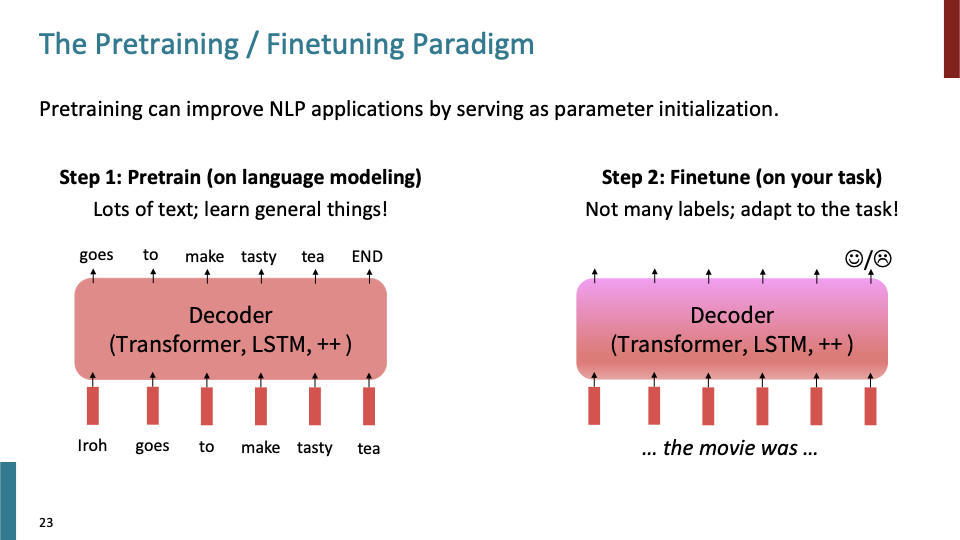
pretrained model에 대해 우리의 data(movie review)로 finetune 시킨다. 이러한 pretrain - finetune paradigm은 매우 successful하다.

training neural nets 관점에서 왜 pretraining, fine tuning이 도움이 될까? 간단하게 말해서 $\hat \theta$가 어디서 시작하는지 (어떻게 initialize)되는지가 정말 중요한다는 것이다. SGD가 동작할때, $\hat \theta$가 근접한 값으로 finetune된다. 다시말하면, 우리가 pretrained한 $\hat \theta$ 에 가깝게 local minima로 loss를 finetune하는 것은 generalize가 잘된다고 말할 수 있다. gradient 또한 $\hat \theta$로 finetune하는 것또한 propagate이 잘된다고 말할 수 있다.

지금까지는 encoder-decoder의 transformer를 살펴보았는데, pretrain을 할때 Encoder만 사용할 수도 있고, Decoder만 사용할 수도 있다.

- Decoder : Languasge Model이다. pretrained LM으로부터 sample을 generate할 수 있다. Encoder와 Decoder의 그림을 비교하여 보면 Decoder는 future word에 대해 condition을 하지 못한다는 것을 알 수 있다.
- Encoder : Bidirectional context를 얻을 수 있지만, 문제는 어떻게 pretraining을 할 것이냐는 것이다. LM task로 pretrain하지 못한다.
- Encoder - Decoder : good parts of decoder, encoder를 사용할 수 있다. 이제, 이것들을 pretrain시키는 가장 좋은 방법에 대해 알아봐야 한다.
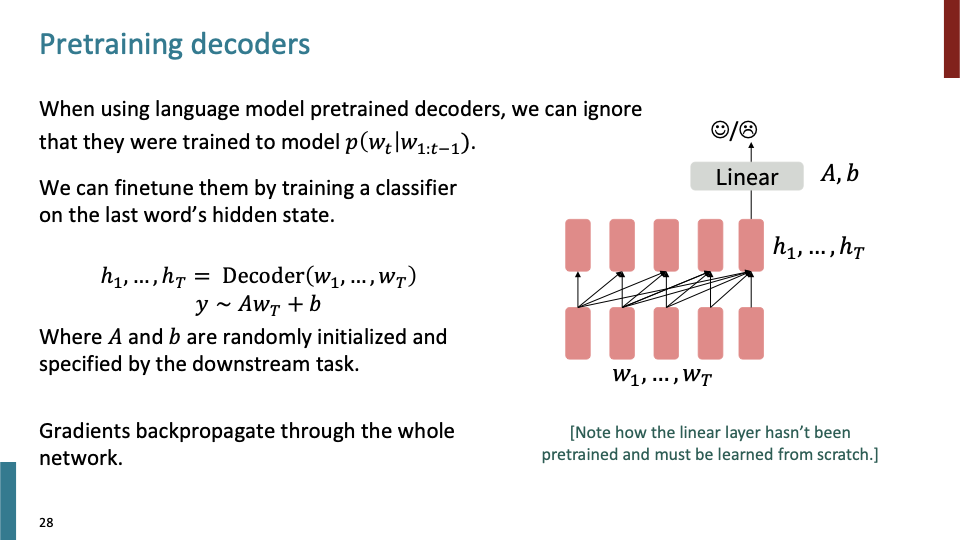
Decoder부터 살펴보자. previous word에 대한 현재의 word의 조건부 확률로 예측하는 LM task로 decoder를 학습하게 된다. (여기서 word는 sub word이다.) sentiment classification을 하는 downstream task에 대한 그림이 위와 같다. 이때 , decoder의 마지막 hidden state만을 사용하게된다.
Language Model, probability distribution으로 사용할 필요 없이, finetuning 할때 사실은 pretrained model을 Initialization of parameter로 사용하는 것이다.

pretrained decoder를 사용하는 두번째 방법이다. 우리가 decoder의 concept에 대해 생각한 LM과 더 natural한 방법이다. Probability distribution이라는 것을 무시할 필요 없이, finetuning 할때도 이를 사용하는 것이다. context가 dialogue를 generate한는 task나, summarization하는 모델에 대해 pretrained decoder의 LM concept을 사용하는 것이다.

pretrained decoder로 만들어진 모델중, 처음으로 성능이 매우 좋았던 model인 Generative Pretrained Transformer이다. 년도가 지나갈수록 model의 크기가 어떻게 변화되는지 주목하면서 살펴보자.
- 12 Layers, 768-dimensional hidden state, 3072-dimensional feed forward hidden layers.
- Byte-pair encodings with 40,000 merges. 이때, 여러 개의 character로 시작했기 때문에 40,000은 vocab size가 아니다. (byte-encoding에서)
- GPT의 full name을 밝힌 적이 없지만, 수업에서 Generative Pretrained Transformer라고 사용하기로 했다.

Huge Language model을 7000개의 책에 대해 pretrained 하였다. 그리고 다양한 task에 대해 fine tune했다. 그 task 중 Natural Language Inference task에 fine tune결과가 위와 같다. 전제에 대해 가정이 참인지, 아닌지에 대해 판단하게 된다. 이때 logical reasoning을 학습하게 된다. pretraining이 매우 유용하기 때문에, 모델의 구조를 바꾸지 않고, input token format을 변경하여 학습한다. [START], [DELIM], [EXTRACT]와 같은 special token을 사용한다.여기서 classifier는 EXTRACT token에 대해서만 적용한다.
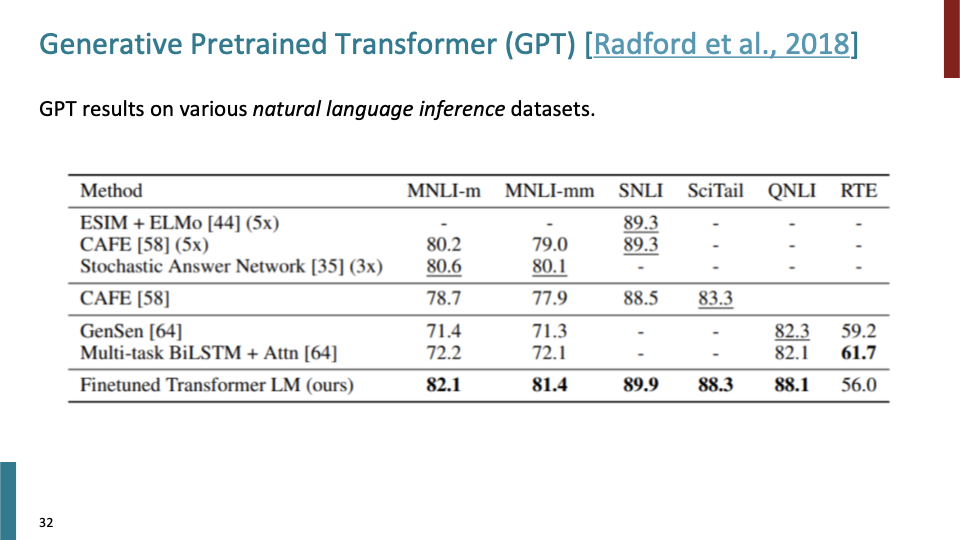
결과는 위와 같이 매우 좋았다. 그리고 pretrain을 사용하면, 다른 모델을 사용하는 것보다 덜 노력(?)해도 된다.

그렇다면 Decoder에 대한 다른 방법은 어떠할까? 위에서 말한 두번째 방법으로, LM concept을 사용하는 것이다. GPT1보다 더 크고, 더 많은 데이터로 학습된 GPT2는 상대적으로 convincing samples of natural language를 만들었다. GPT2에 truncating distribution of LM이라는 것을 사용해서, GPT2가 만들어 내는 sample의 noise를 제거했다.

Encoder의 장점은, 이전에 말했듯이 bidirectional context를 얻는다. future에 있는 word를 보고 better representation을 만들 수 있다. 하지만 큰 문제는 Language Modeling을 사용하여 pretraining을 하지 못한다는 것이다.

그것에 대한 solution으로 BERT에서 소개된 방법이 있다. 이 방법은 masked Language Modeling이라고도 불린다. words의 fraction을 가져와서, [MASK]로 replace한 뒤, 해당 words를 predict하는 것이다. prediction layer에서 해당 masked word를 predict하는 것이다. left-to-right decomposition을 사용하는 것이 아니라 sentence의 어떤 단어를 mask할것이고, 이것을 예측해보라는 것이다. Masked Language Modeling에 대해 더 자세히 알아보자.
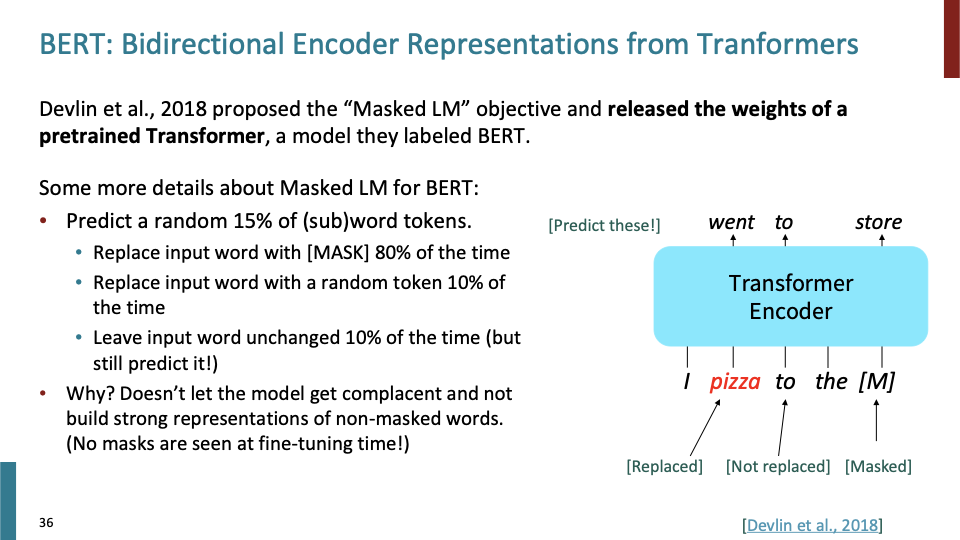
15%의 subword에 대해 예측하게 되는데, 이 subword들이 모두 [MASK] 되는 것은 아니다. 왜냐하면 mask token에 대해서만 predict해야 한다고 생각하고, mask되지 않는 token에 대해서는 predict하지 않아도 된다라고 학습할 수 있기 때문이다. 추가로 설명하자면, non-masked word에 대해서도 strong representation을 학습하기 위해서 이다. 15% sub word에 대해 predict할때, 80% time에 대해 mask token으로 Replace하고, 10% time에 대해서는 input을 random token으로 replace하고, 10% time에 대해서 input word를 바꾸지 않을것이다. 위 슬라이드의 예시를 보면 알 수 있다. replace된 pizza라는 단어에 대해서는 went라는 것을 학습하고, to는 그대로 두고, [mask]에 대해서는 store에 대해 학습한다.
이것이 token randomization과 같은것을 사용해서 mask만을 고려하지 않게 하는 중요한 이유이다. 사실 Mask token을 예측하는 것이 중요한것이 아니라, strong representation을 만드는 것이 중요하다.
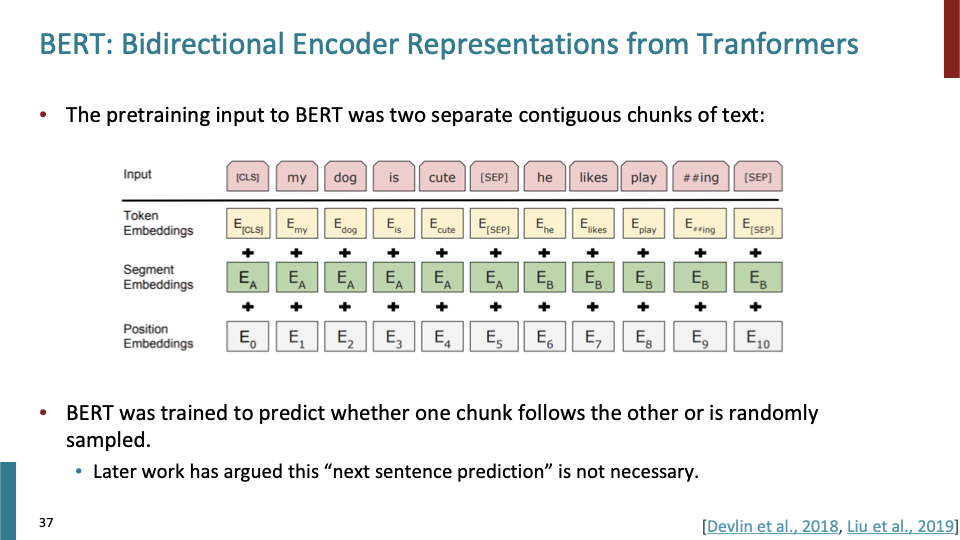
첫번째 문장 전에 [CLS] token이 있고, 두번째 문장 전과 끝에 [SEP] token이 있다. 항상 two contiguous chunks of text가 필요하다. 각 문장은 실제로는 매우 길것이다. 두개의 chunk에 대한 relationship을 시스템을 학습시키기 위해 Two contiguous chunk를 input으로 사용했다. Question Answering과 같은 Down stream task를 위해 더 좋은 pretrain을 하기 위해서 이를 사용했다. second chunk가 first chunk 바로 뒤에 오는 chunk일 수도 있지만, random하게 sample된 chunk일 수도 있다. 결과적으로 system은 두개의 chunk의 relation에 대해 학습하게된다. next sentence prediction이라고도 볼 수 있다.

BERT-base, BERT-large에 따라서 12, 24 layer를 갖는다. 768,1024 dims를 12,16개의 attention head로 split하여 학습한다. 각각은 110M, 340M의 #parameter를 갖는다. 2018년만 해도 매우 많은 parameter를 갖고 있는 모델이었다. 64 TPU chips로 학습되었다. Pretraining은 매우 오래 걸리는 반면, fine tuning은 정말 빠르다.
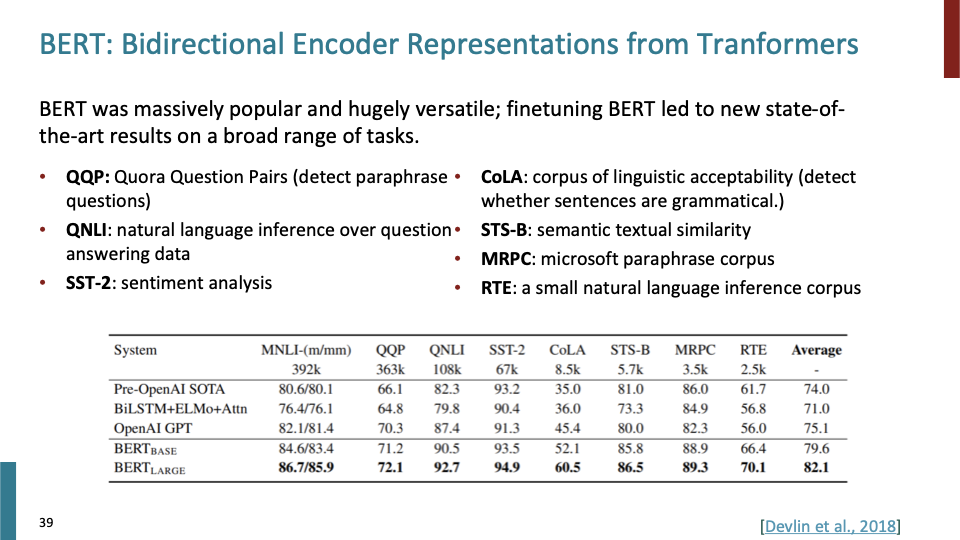
Pretrained model을 사용하여 내가 원하는 것에 fine tune하는 패러다임은 현재 NLP에서 baseline이다. Hugging face에서는 코드 몇줄로 이러한 모델들을 사용할 수 있다. 이제 Evaluation에 대해 살펴보자. 각 task 아래 있는 숫자들은 training example이고, big transformer가 나오기 전과 후의 차이가 매우 큰것을 확인할 수 있다.

결과는 좋은데, 왜 모든 task에 pretrained encoder를 사용하지 않을까? pretrained decoder와 같이 naturally generate하는 것이 아니라, 특정 word를 mask하여 해당 word에 대헤 generate하게 된다. 그래서 pretrained encoder와 decoder 각각이 다른 방식으로 사용된다.
auto-regressive하다는 것은 output이 다음 step의 input으로 사용되는 것을 의미한다.
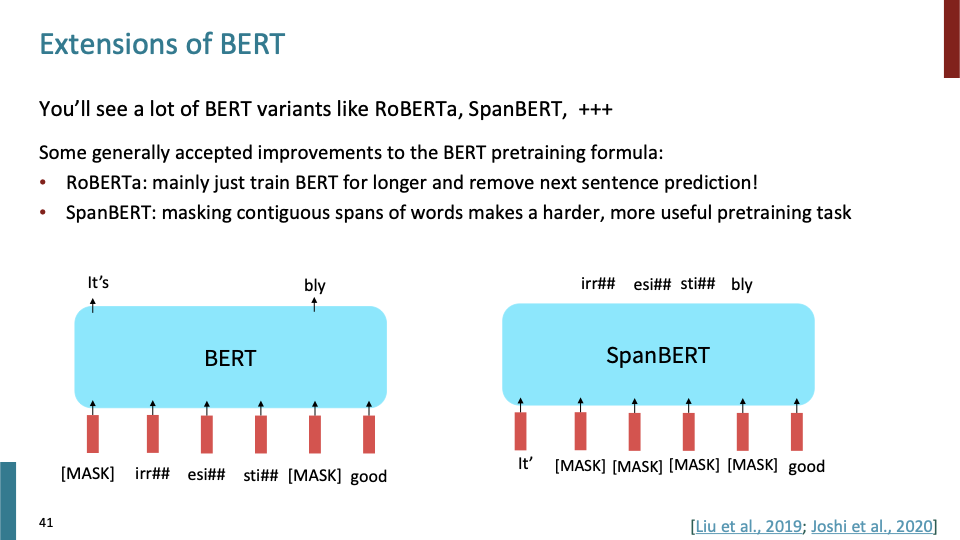
매우 간단하게 extension of BERT에 대해 다뤄보겠다. BERT variant로 RoBERTa와 SpanBERT가 있다. RoBERTa는 train more data, more step으로 BERT를 학습시킨것이다. SpanBERT는 masking contiguous subword를 하여, 더 어렵게 학습하여 유용한 pretraining task를 만든 것이다.
better ways of noising the input, hiding stuff in the input와 같은 방식으로 BERT를 변형하여 학습시킬 수 있다.
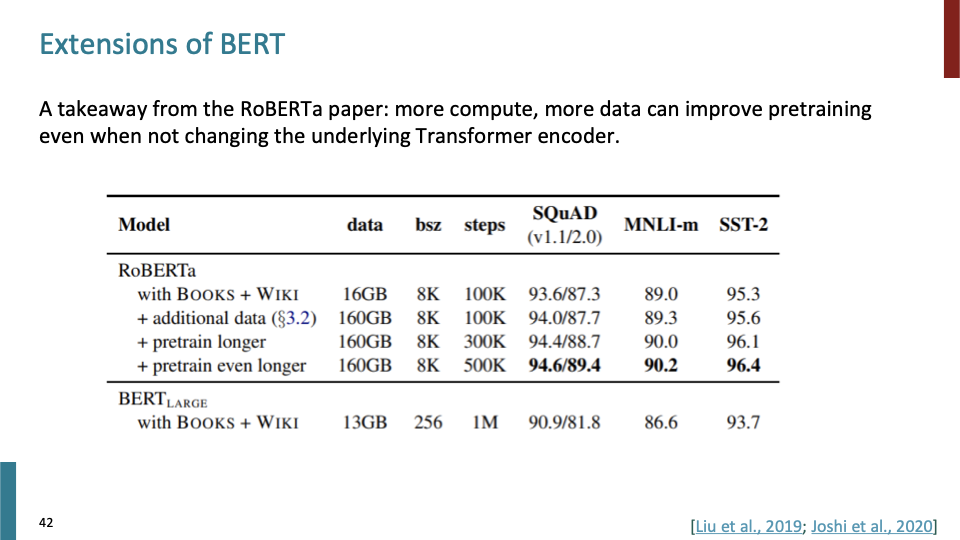
RoBERTa는 BERT가 underfit하다는 것을 보였고, 그것이 결과로 보여진다.

그러면 encoder-decoder 두개 다 사용할 수 있을까?
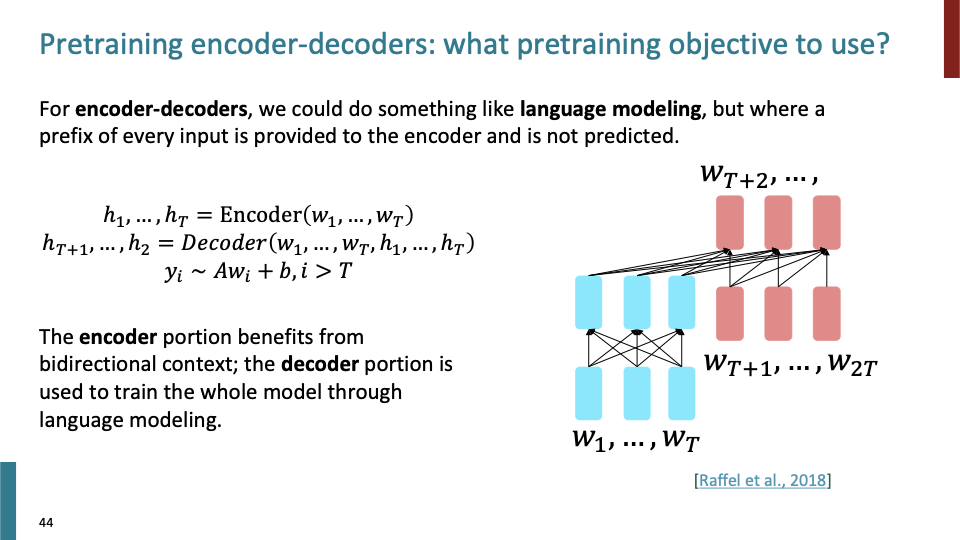
그러면 이것들을 어떻게 pretrain 시킬까? Language Modeling과 유사한 방식으로 pretrain 시킬 수 있다. 1~T에 대해 encoder에 넣고, T+1 ~ 2T에 대해 decoder에 넣어 T+2 이후의 word에 대해 language modeling을 하게 된다.
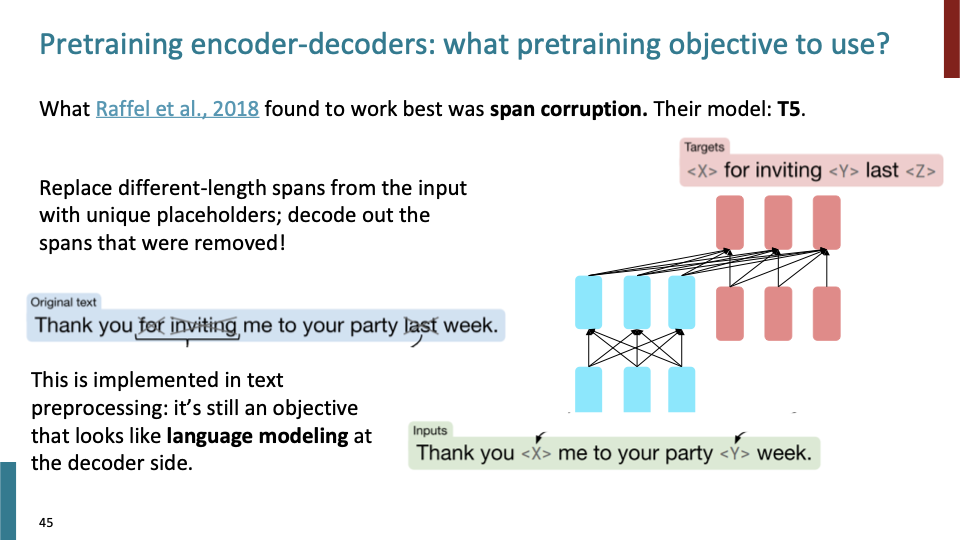
T5 model인데, 다른 objective를 갖고있다. 여러 objective으로 pretraining할 수 있어서, 각 pretrained model이 다르다는것을 고려하자. original text에 대해 different length span을 unique symbol로replace 하게 되는데, BERT와 다른점은 각 span의 length가 모두 다르다는 것이다. BERT는 어떠한 개수의 token을 mask했다고 보여주는 반면, T5에선 단순히 어떠한 span이 missing되어 있다는 것만을 표현한다. decoder는 replaced span들을 generate하게 된다. 이 방법을 span-corruption이라고 부른다.
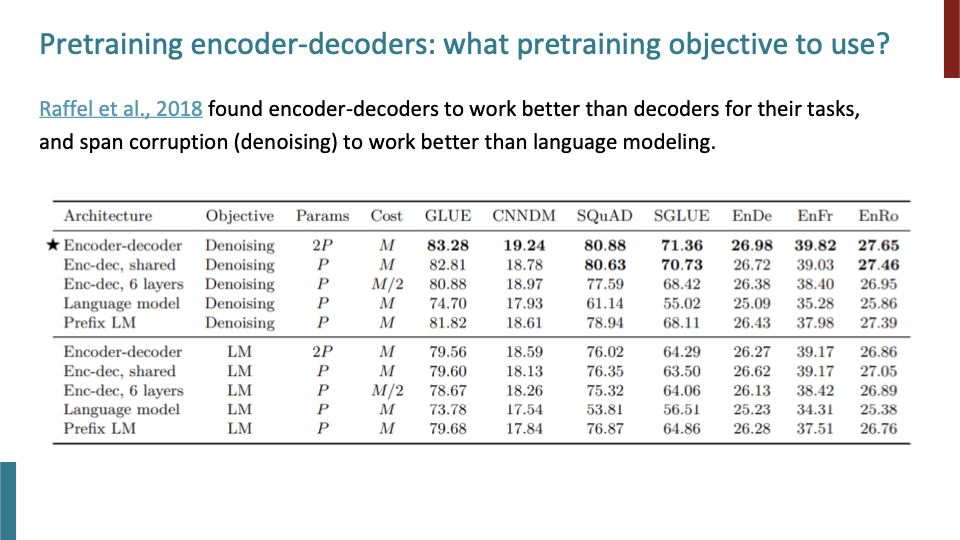
그래서 T5가 다른 encoder-decoder 구조의 모델보다 월등히 성능이 좋았다.
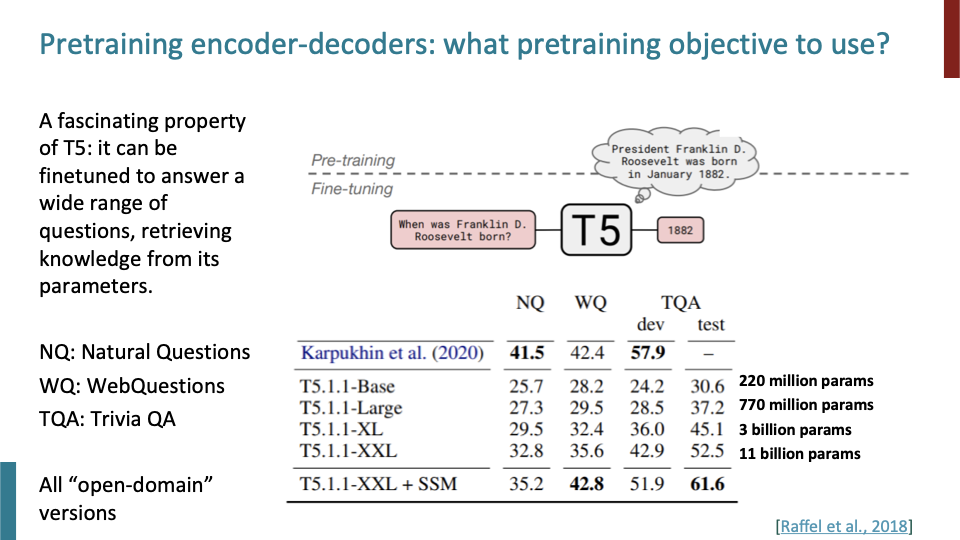
T5에 대해 fascinating한 것은 pretrain한 것을 question에 대해 답하게 끔 finetune할 수 있다는 것이다. test time에서는 새로운 질문을 했을때, 꽤 잘 작동했다.

model은 또한 racism, sexism과 같은 bad biases를 학습할 수 있다.

GPT-3는 gradient step없이 context를 학습한다. Language Modeling으로써 pretrain하는 방법을 사용한다.

단순히 input으로 (영어,프랑스) translation pair를 주었을때, output으로 해당 단어에 맞는 translation을 출력한다.
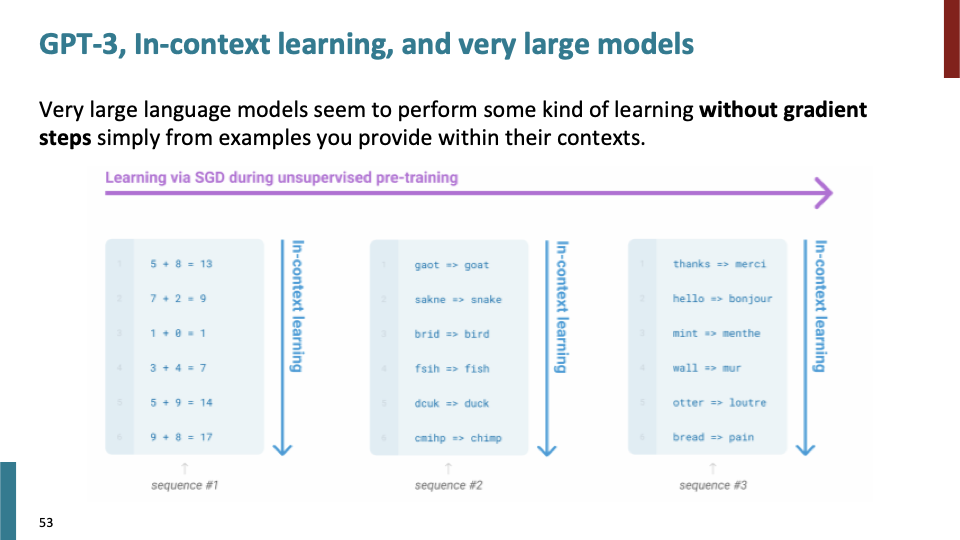
fine tune할 필요없이, prefix만 제공하면 그것에 대한 output을 얻을 수 있다.
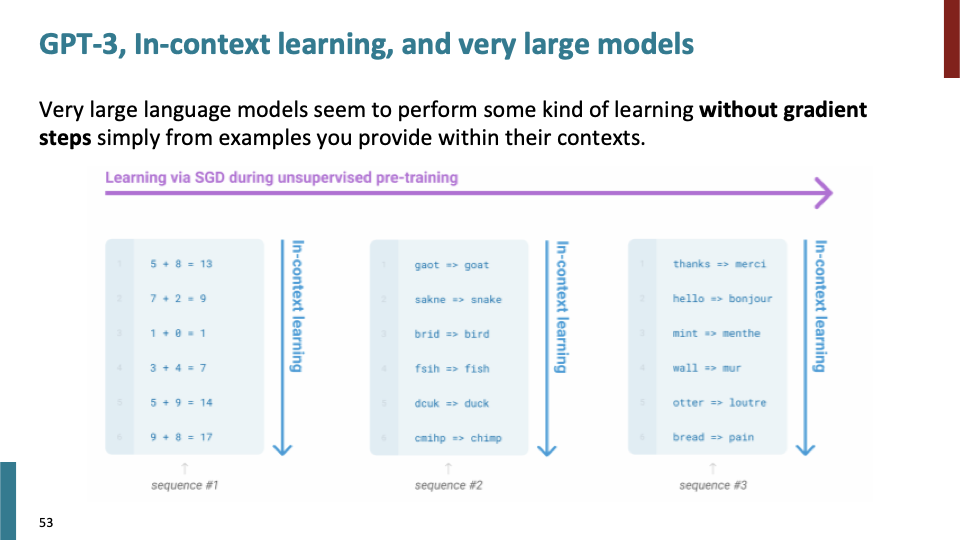
이러한 것을 in-context learning이라고 부른다.

하지만 BERT와 같은 small model이 wide range of setting에 대해 general한 tool로 사용된다.
학생 Q) T5에서 decoder가 X 또는 Y를 예측하는지 어떻게 아는가?
A) Encoder에서 X, Y에 대한 point(=position)을 알 수 있다. Encoder로부터 2개가 missing하고 있다는 것을 학습하기 때문이다.