Multi-GPU in Pytorch(1)
24 Jan 2022
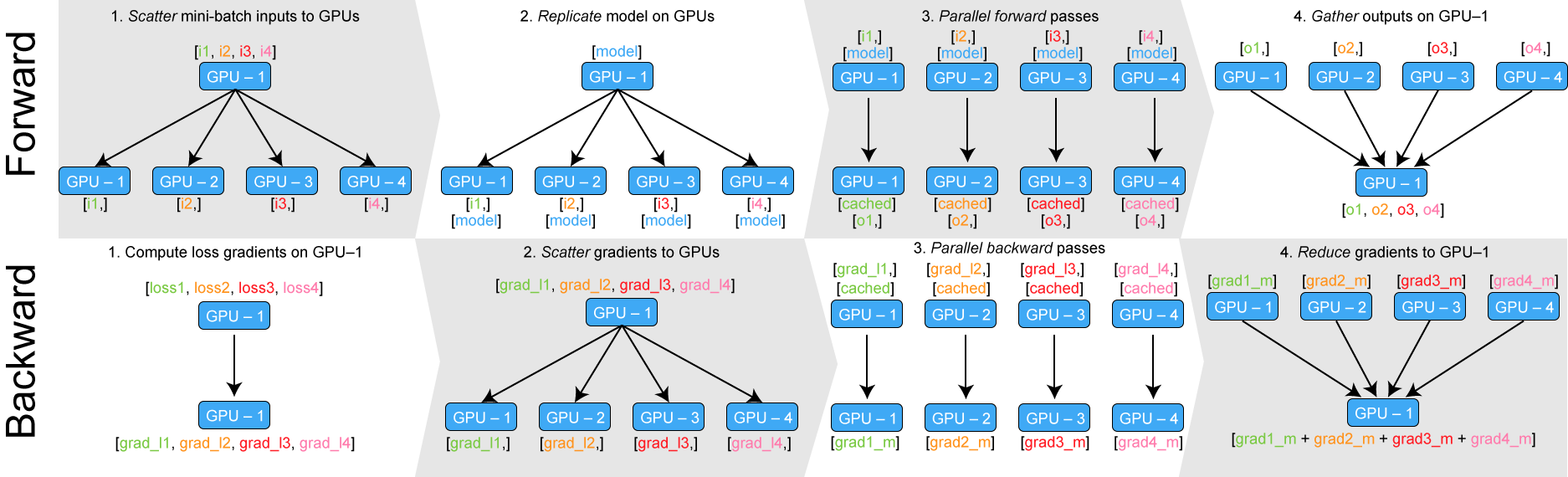
Multi-GPU을 사용하는 가장 쉬운 방법은 GPU개수 만큼의 batch를 여러 gpu로 나눠 할당한후, gradient를 계산하고, 그 gradient를 하나의 gpu로 누적하여 back-propagation하는 것이다. 이를 위해선 다음 4단계를 거쳐야 한다.
-
replicate
딥러닝을 여러개의 GPU에서 사용하려면, 모델을 각 GPU에 복사해서 할당해야한다.
-
scatter
iteration때 마다, batch를 GPU 개수만큼 나눈다. Data Parallel에서 scatter 함수를 사용해서 이 작업을 수행한다.
-
parallel_apply
입력을 나누고 나서, 각 GPU에서 forward 과정을 진행한다.
-
gather
각 입력에 대해 모델이 출력을 내보내면, 출력들을 하나의 GPU로 모은다. tensor를 하나의 gpu로 모으는 과정을 gather라고 한다.
Back propagation은 각 GPU에서 수행하며 그 결과로 각 GPU에 있던 모델의 gradient를 구할 수 있다. 만약 4개의 GPU를 사용한다면 4개의 GPU에 각각 모델이 있고, 각 모델은 계산된 gradient를 갖고 있다.
모델을 업데이트하기 위해 각 GPU에 있는 gradient를 또 하나의 GPU로 모아서 업데이트를 한다. 만약 Adam과 같은 optimizer를 사용하고 있다면 gradient로 바로 모델을 업데이트하지 않고 추가 연산을 한다. 이러한 Data Parallel 기능은 코드 한 줄로 구현 가능하다.
import torch.nn as nn
model = nn.DataParallel(model)
Gather가 하나의 gpu로 각 모델의 출력을 모아주기 때문에 하나의 gpu의 메모리 사용량이 많을 수 밖에 없다.
def data_parallel(module, input, device_ids, output_device):
replicas = nn.parallel.replicate(module, device_ids)
inputs = nn.parallel.scatter(input, device_ids)
replicas = replicas[:len(inputs)]
outputs = nn.parallel.parallel_apply(replicas, inputs)
return nn.parallel.gather(outputs, output_device)
일반적으로 DataParallel을 사용한다면 다음과 같이 코드가 돌아간다.
import torch
import torch.nn as nn
model = BERT(args)
model = torch.nn.DataParallel(model)
model.cuda()
...
for i, (inputs, labels) in enumerate(trainloader):
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
하나의 GPU가 상대적으로 많은 메모리를 사용하면 batch size를 많이 키울 수 없다. 딥러닝에서 batch size는 학습 성능에 영향을 주는 경우가 많기 때문에 메모리 사용 불균형은 꼭 해결해야할 문제이다.
메모리 불균형 문제
메모리 불균형 문제를 제일 간단히 해결하는 방법은 단순히 출력을 다른 GPU로 모으는 것이다. 디폴트로 설정되어있는 GPU의 경우 gradient 또한 해당 GPU로 모이기 때문에 다른 GPU에 비해 메모리 사용량이 상당히 많다. 따라서 출력을 다른 GPU로 모으면 메모리 사용량의 차이를 줄일 수 있다.
다음과 같이 출력을 모으고 싶은 GPU 번호를 설정하면 된다.
import os
import torch.nn as nn
os.environ["CUDA_VISIBLE_DEVICES"] = '0, 1, 2, 3'
model = nn.DataParallel(model, output_device=1)
output_device를 설정하면, GPU 사용량이 달라진 것을 확인할 수 있다. 하지만 여전히 메모리 불균형 문제가 있다.
Custom으로 DataParallel 사용하기
DataParallel을 그대로 사용하면서 메모리 불균형의 문제를 해결할 수 있는 방법에 대한 힌트는 PyTorch-Encoding이라는 패키지에 있다.
(패키지 링크: https://github.com/zhanghang1989/PyTorch-Encoding).
하나의 GPU의 메모리 사용량이 늘어나는 것은 모델들의 출력을 하나의 GPU로 모은 것 때문이다. 하나의 GPU로 모은 이유는 모델의 출력을 사용해서 loss function을 계산해야 하기 때문이다.
모델은 DataParallel을 통해 병렬로 연산할 수 있게 만들었지만, loss function이 그대로이기 때문에 하나의 GPU에서 loss를 계산해야한다. 따라서 loss function 또한 병렬로 연산하도록 만든다면 메모리 불균형 문제를 어느정도 해결할 수 있다.
PyTorch-Encoding 중에서도 다음 파이썬 코드에 loss function을 parallel하게 만드는 코드가 들어있다.
PyTorch-Encoding/parallel.py at master · zhanghang1989/PyTorch-Encoding
Loss function을 병렬 연산 가능하게 만드는 방법은 모델을 병렬 연산으로 만드는 방법과 동일하다. PyTorch에서 loss function 또한 하나의 모듈이다.
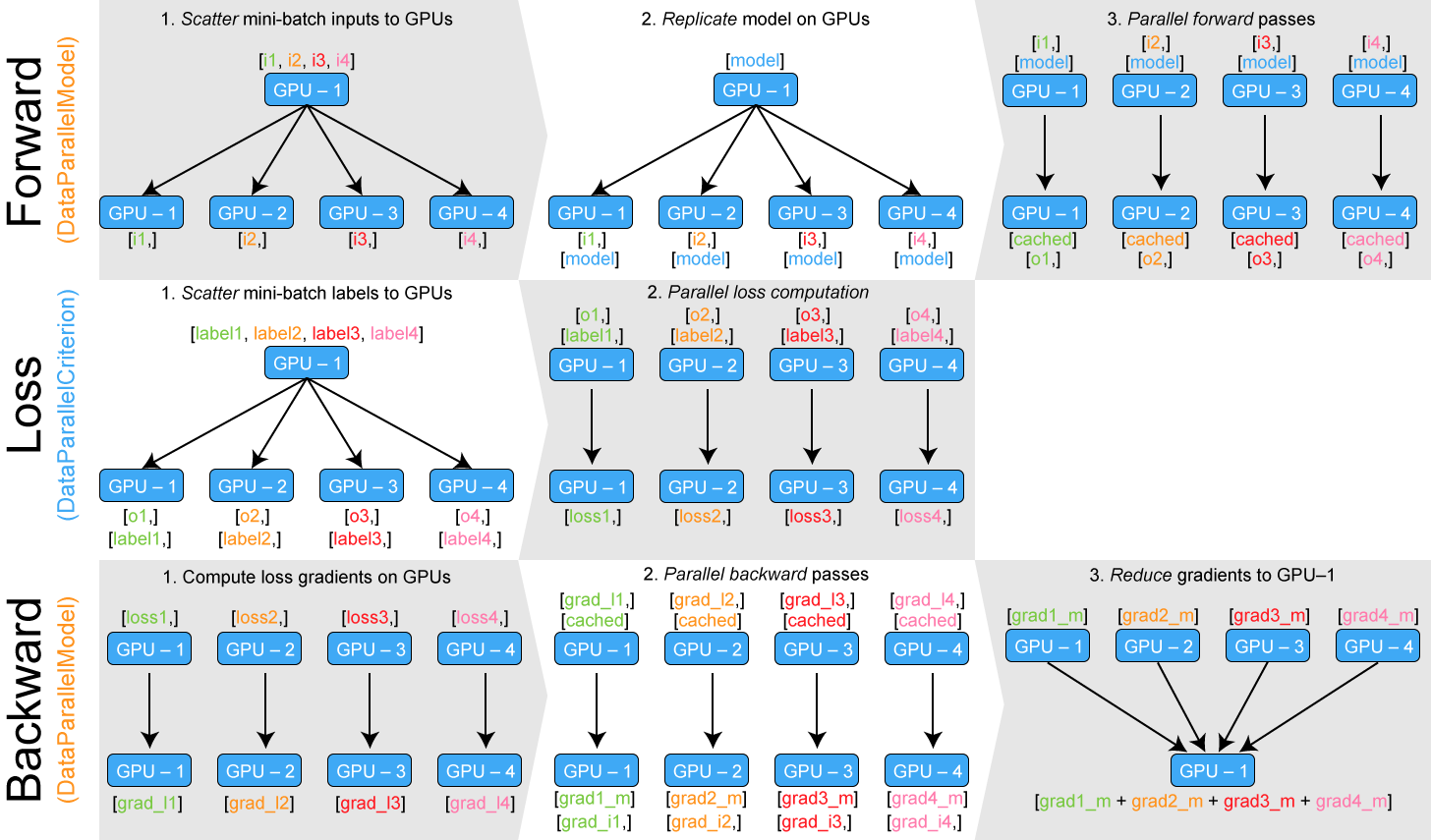
이 모듈을 각 GPU에 replicate 한다. 그리고 데이터의 target에 해당하는 tensor를 각 GPU로 scatter 한다. 그러면 loss를 계산하기 위한 모델의 출력, target, loss function 모두 각 GPU에서 연산할 수 있도록 바뀐 상태이다. 따라서 각 GPU에서 loss 값을 계산할 수 있다. 각 GPU에서는 계산한 loss로 바로 backward 연산을 할 수 있다.
from torch.nn.parallel.data_parallel import DataParallel
class DataParallelCriterion(DataParallel):
def forward(self, inputs, *targets, **kwargs):
targets, kwargs = self.scatter(targets, kwargs, self.device_ids)
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
targets = tuple(targets_per_gpu[0] for targets_per_gpu in targets)
outputs = _criterion_parallel_apply(replicas, inputs, targets, kwargs)
return Reduce.apply(*outputs) / len(outputs), targets
Loss function을 parallel하게 만드는 과정은 다음과 같다. target을 각 gpu에 scatter한 다음에 replicate한 모듈에서 각각을 게산한다. 계산한 output과 reduce apply를 통해 각 GPU에서 backward 연산을 하도록 만든다.
from parallel import DataParallelModel, DataParallelCriterion
parallel_model = DataParallelModel(model) # Encapsulate the model
parallel_loss = DataParallelCriterion(loss_function) # Encapsulate the loss function
predictions = parallel_model(inputs) # Parallel forward pass
# "predictions" is a tuple of n_gpu tensors
loss = parallel_loss(predictions, labels) # Compute loss function in parallel
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = parallel_model(inputs) # Parallel forward pass with new parameters