(Winter 2021)CS224N|Lecture 8 Final Projects. Practical Tips
10 Jan 2022
이전에 들은 강의들을 정리하던 와중에 2021 10월에 찍은 강의들이 올라왔다. 2019년에 비해서 Natural Laguage Generation과 같은 부분도 추가되었고, 정말 많은 변화가 있었기 때문에 최신 강의를 바탕으로 정리할 예정이다. Attention에 대해서 한번 더 정리했고, neural network project를 진행하는 데 있어서 어떤 방식으로 진행 해야 하는지에 대한 내용이었다. 자유도가 높은 상황에서 프로젝트를 하고 있어서, 이 강의의 내용들이 도움이 되었다. 마지막엔 Question Answering task를 왜 다루는지에 대한 내용을 다루고 있다.
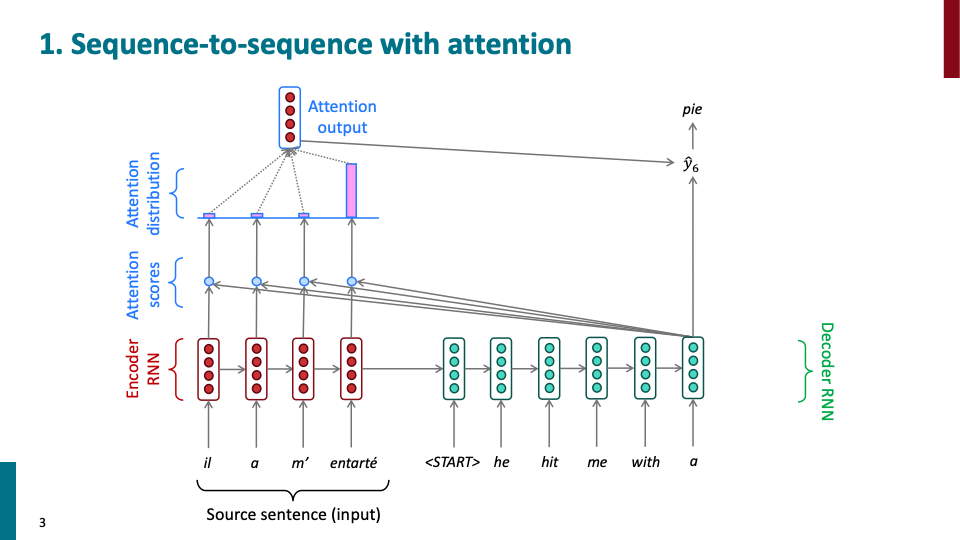
decoder의 hidden state들이 encoder들의 hidden state들을 보게하여, 각각에 대한 cosine similiarity를 계산하여 attention score를 계산한다. 그 score를 기반으로 attention distribution을 계산하고, encdoer의 맵핑 되는 각각의 attention distribution을 weight로 사용하여 encoder hidden state의 weighted average를 구한다. 이 값이 attention ouput으로써, attention vector이다.
Q) 왜 encoder, decoder RNN을 분리해서 사용하고, translation이 진행될때, 이전 decoder의 sequence들에 대해서는 왜 고려하지 않는가 라는 질문이 있었다. A) 일단 attention은 Machine Translation을 위해 나온 모델으로써, source 언어, target언어 각각에 해당하는 sequence model이 있는 것이 합리적이다. 두번째 질문에 대해서는, 그것을 고려한 모델이 self-attention이다. 그리고 이어져서 나온 모델이 바로 transformer!.
사실 attention이 처음 왜 개발되었는지를 고려해보면 self-attention이 왜 나왔는지 의구심이 들 수도 있다. conditional Language Model로써, decoder RNN에서 점점더 긴 문장을 해석할 수 록, encoder의 정보를 잃어 버리는것이 당연하다. 그래서 attention이 그 역할을 해준다. 그리고 decoder안에서의 sequence에 대해 학습하는 것은 LSTM이 그 역할을 해주고 있었다. 하지만 선택적으로 정보를 전달하는 방식인 LSTM보다 attention 방식이 더 성능이 좋고, 더 light weight했다.

위에서 말한 과정을 수식으로 표현한 것이다.

강조할 부분은 attention이 bottleneck problem을 해결했다는 것이다. attention 모델에서는 source hidden state 전체에 대해 접근하므로, 우리가 필요한 정보를 얻게 된다. LSTM과 같은 방식처럼 마지막 hidden state가 아니라. 또한 vanshing problem에 효과적이다. 모든 encoder의 hidden state에 대해 shortcut이 있기 때문이다. 그리고 또한 어느정도의 interpretability를 제공한다. attention distribution을 보면 encoder의 어떤 hidden state에 집중하고 있는지 알 수 있기 때문이다. 또한 attention model에서는 SMT에서의 alignment과 같은 부분 대해 separte 하거나 explicit한 system이 없다. 단순히 seq-to-seq model을 학습 시켰을 뿐이다.

- attention score를 계산
- 이를 이용해 attention distribution을 계산하고,
- 또 이것을 이용해 weighted average를 계산한다.
위 3가지 파트는 attention에 항상 존재하는데, attnetion은 1번 항목에 대해 attention score를 어떻게 계산하는지에 따라 달라진다.

- Basic dot-product attention은 위에서 언급한 cosine similarity를 계산하는 attention score이다. size of query vector(=attention output)과 value vector(=encoder hidden state vector)의 size가 같아야 한다.
- Multiplicative attention : 이것의 idea는 bilinear function을 query와 value에 적용하는 것이다. 여기서 W는 learnable parameter로 이루어져 있다. W가 너무 많은 vector를 갖는 문제가 있었다.
- 그래서 나온것이 Reduced rank multiplicative attention이다. 위에서의 W보다 reduced rank matrix로 이루어져 있는 $U,V$를 통해 계산을 하게 된다.
- Additive attention: 여기서 $d_3$는 attention output의 차원을 의미하고, length of V 그리고 height of W1,W2 에 대한 hyper parameter 입니다.

MT뿐만 아니라 많은 다른 task에서도 attention은 사용 가능하다. value에 모든 information이 있고, query는 value들에 대해 어떻게 pay attention할지 정할 vector로 이루어져 있을때, 이를 query attend to value라고도 표현한다.

각 step의 encoder source sentence에 대한 weighted sum은 selective summary라고 볼 수 있다. attention distribution에서 각 value(source sentence)에 얼마나 attend해야 하는지 choice를 담은 summary이기 때문이다. 이는 LSTM과 어떤 부분에서 유사합니다. LSTM gate들은 각기 다른 element에서 얼마나 정보를 유지(가져올지)할지 정한다.
Attention은 fixed-size of representation of arbitrary set of representation을 얻는 방법이다. 앞선 슬라이드에서 query attends to the value라고 했다. arbitrary set of representation은 value에 해당한고 볼 수 있다. fixed size of representation은 single vector ( = attention output) of using query라고 볼 수 있다.

이 수업을 다듣고 해봐야 할것 중 하나가 large pretrained model을 이용해서, SQuAD task를 해보는것이다. KLUE에도 한국어로 이루어진 같은 성격들의 데이터들이 있다.

최신의 paper들은 big pre-trained model을 활용하여 사용한다.

그래서 2021년도의 대부분 NLP practical project과 기업들이 원하는 방향은 위와 같은 pretrained model을 이용하는것이다.

robutness를 향상시키는 것 또한 의미있다. 다른 언어에서 학습될 경우, 혹은 specific한 question들이 주어졌을때도 원래와 같은 성능을 유지하는지 평가하고 향상시켜 보는것이다. robustnessgym이라는 프로젝트는 NLP model들의 robutness를 평가하는 프로젝트이다. 또는 bias, explainability를 평가해보는 방향도 있다.

GPT-2, GPT-3와 같은 모델은 이미 충분히 크다. 개인이 이러한 모델을 만드는것은 불가능에 가깝고, 어떻게 활용하는 지에 따라 달라진다. 하지만 어떤 사람들은 잘 작동하는 small model에도 관심이 있다. question answering task에 대해 잘 작동하는 작은 모델을 만들 수 있는지에 대한 대회도 있었다.

Linguistic Data Consortium, statmt, univeraldependencies.org, huggingface, paperwithcode와 같은 사이트에 여러 task에 대한 dataset을 구할 수 있다. KLUE에도 모든 task에 대한 기본적인 한국어 dataset이 있고, kaggle dataset을 잘 검색해보면 좋은 dataset이 있다.




위와 같은 process를 거쳐 project를 완성하면된다. 개인 프로젝트를 할때도 위의 항목을 참고하면 될것 같다.

많은 public dataset에서 train,dev,test set으로 이루어진 dataset을 제공한다. 각 dataset에 맞게 사용하면된다. 이렇게 하는 이유는 realistic performance를 측정하기 위해서 이다.

마지막 오분 정도 SQuAD dataset을 이용하는 Question Answering task에 대해 설명했다. Q&A는 사실 reading comprehension이라고 불리는게 낫다고 한다.
구글에 어떤 질문을 검색했을 때, 나오는 답들은 Google Knowledge graph structed data로부터 나오는 것이 아니라, google web의 어떤 부분에서 그대로 긁어온 것이다. 이런 Q&A을 하는데 있어서 기본적으로 2가지 파트가 필요하다. Answer를 포함하는 page를 찾을 수 있는 web search 시스템을 만들고, text에서 answer를 extract할 수 있는 reading comprehension system을 만들어야 한다.
Question answering task의 motivation을 살펴보자. massive list of full text document가 주어져 있을때, 질문이 주어지면 쓰임새가 한정된 relevent document를 return된다. 하지만 우리는 질문에 대한 답을 원한다. mobile, google assistant를 쓸때 더욱 그러하다. 이러한 이유로 reading comprehension (또는 question answering)의 task를 해결하고자 하는 것이다.


SQuAD에 대한 문제 예시와, SQuAD1.1evaluation관한 내용이다.

SQuAD2.0에서는 정답이 없는 질문도 주어진다. 이러한 test를 통해 reliability를 검증할 수 있다.