Handling Large dataset in python(2)
02 Jan 2022
Handling Large dataset in python(1)에서 왜 Numpy, pandas가 빠르게 동작하는지를 살펴보았다. 이 포스트에서는 pickle package가 무엇이고, 진짜 dataframe을 읽을 때 빠른지에 대한 분석과 사용하는 이유에 대한 내용을 다룹니다.
Serialize & Deserialize
pickle package의 원리에 대해 이해하기 위해서는 serialize와 deserialize에 대해 이해를 해야합니다. 보통serialization process는 어떠한 data structure를 linear form으로 covert하여 네트워크를 통해 전송하거나, 저장되는 것을 가능하게 하는 process를 의미합니다. python에서의 serialization은 복잡한 object structure에 대해 stream of bytes의 형태로 transform하여 disk에 저장하거나 network를 통해 전송되는 것을 가능하게 해줍니다. 이러한 process를 marshalling이라고 부르기도 합니다. Reverser process를 deserialization 혹은 unmarshalling이라고 합니다.
Serialization은 많은 경우에 활용할 수 있으며, 대표적인 예로는 neural network의 모델을 저장할 수 있고, 또 특정 epoch에서의 state를 저장하여 나중에 training을 재개하게 할 수도 있습니다. Serialization을 support하는 package는 대표적으로 다음 세가지가 있습니다.
marshaljsonpickle
marshal 은 기본적으로 위의 세가지 package 중에 가장 오래 됬고, compile된 파이썬 모듈이나, .pyc file들을 읽고 쓰는데 주로 사용합니다. json 은 세가지 모듈중 가장 최신에 나온 모듈이고, standard json file들에 사용할 수 있습니다. 이 포스트에서 주로 다룰 pickle은 앞선 두가지 모듈보다 빠를 뿐만 아니라 custom-defined object들과도 잘 작동합니다.
How to use pickle
- pickle.dump(obj, file, protocol=None, , fix_imports=True, buffer_callback=None)
- pickle.dumps(obj, protocol=None, , fix_imports=True, buffer_callback=None)
위의 두가지 method는 pickling process에 사용하는 method로써, 주어진 obj에 대해 serialize합니다. dump() 와 dumps() 의 차이는 첫번째 method는 serialization result를 포함하는 file을 생성하고, serialization result를 byte object를 반환합니다.
- pickle.load(file, *, fix_imports=True, encoding=”ASCII”, errors=”strict”, buffers=None)
- pickle.loads(bytes_object, *, fix_imports=True, encoding=”ASCII”, errors=”strict”, buffers=None)
3,4번째 method들은 unpickling process에 사용하는 method로써, 주어진 file 혹은 bytes object을 deserialize합니다. 다음은 예시 코드입니다.
import pickle
class example:
a_number=35,
a_string='hi'
a_list = [1,2,3]
obj = example()
pickled_obj = pickle.dumps(obj) # piclking the object
print(f'This is pickled object:{pickled_obj}')
unpickled_obj = pickle.loads(pickled_obj)
print(f'This is unpickled object:{unpickled_obj.a_string}')ㅇ
pickle.loads() 를 통해 새로운 instance를 반환받게 되면, 기존의 obj에 대해 deep copy한 것과 같은 결과를 갖게 된다.
This is pickled object:b'\x80\x03c__main__\nexample\nq\x00)\x81q\x01.'
This is unpickled object:hi
pickling process를 거친 obj혹은 bytes열은 python에서만 사용할 수 있다. 하지만 python의 버전에 따라 support하는 pickle protocol이 달라진다. 즉, python3.8까지 support하는 protocol version5에서의 pickled obj을 python 3.0을 support하는 protocol 3의 pickle 모듈의 load로 unpickle할 수 없다는 것을 의미한다.
많은 object type을 pickling할 수 있지만, pickable하지 않은 타입도 있다. 대표적인 unpickable한 타입들은 database connections, opened network sockets, running threads을 포함한 object들이다. dill 이라는 모듈은 pickle의 확장버전으로 이를 사용하면 function with yield, nested function에 대해서도 pickling이 가능하다.
pickle data format은 그 자체로 이미 compact binary representation이지만, bzip2, gzip 을 이용하여 한번더 압축가능하다.
import pickle
import gzip
data = {
'a': [1, 2.0, 3, 4+6j],
'b': ("character string", b"byte string"),
'c': {None, True, False}
}
# save and compress.
with gzip.open('testPickleFile.pickle', 'wb') as f:
pickle.dump(data, f)
# load and uncompress.
with gzip.open('testPickleFile.pickle','rb') as f:
data = pickle.load(f)
Is pickle really fast?
pickle이 정말 빠른지 검색을 해보면 해볼수록 혼란스러웠다. 과거(10~8년전)의 Post들에서는 do not pickle 이라는 제목의 post가 정말 많을 정도로, pickle은 json보다 느리고, unreadable하고, unsecure한 단점만 많은 package였다. 하지만 (비교적 5년전) 최근의 post 에서는 pickle이 dataframe을 읽는데 가장 빠른 package중 하나이며, 정말 크기가 큰 file을 읽고 저장하는게 아니라면 pickle을 사용하는것을 권장하고 있다.
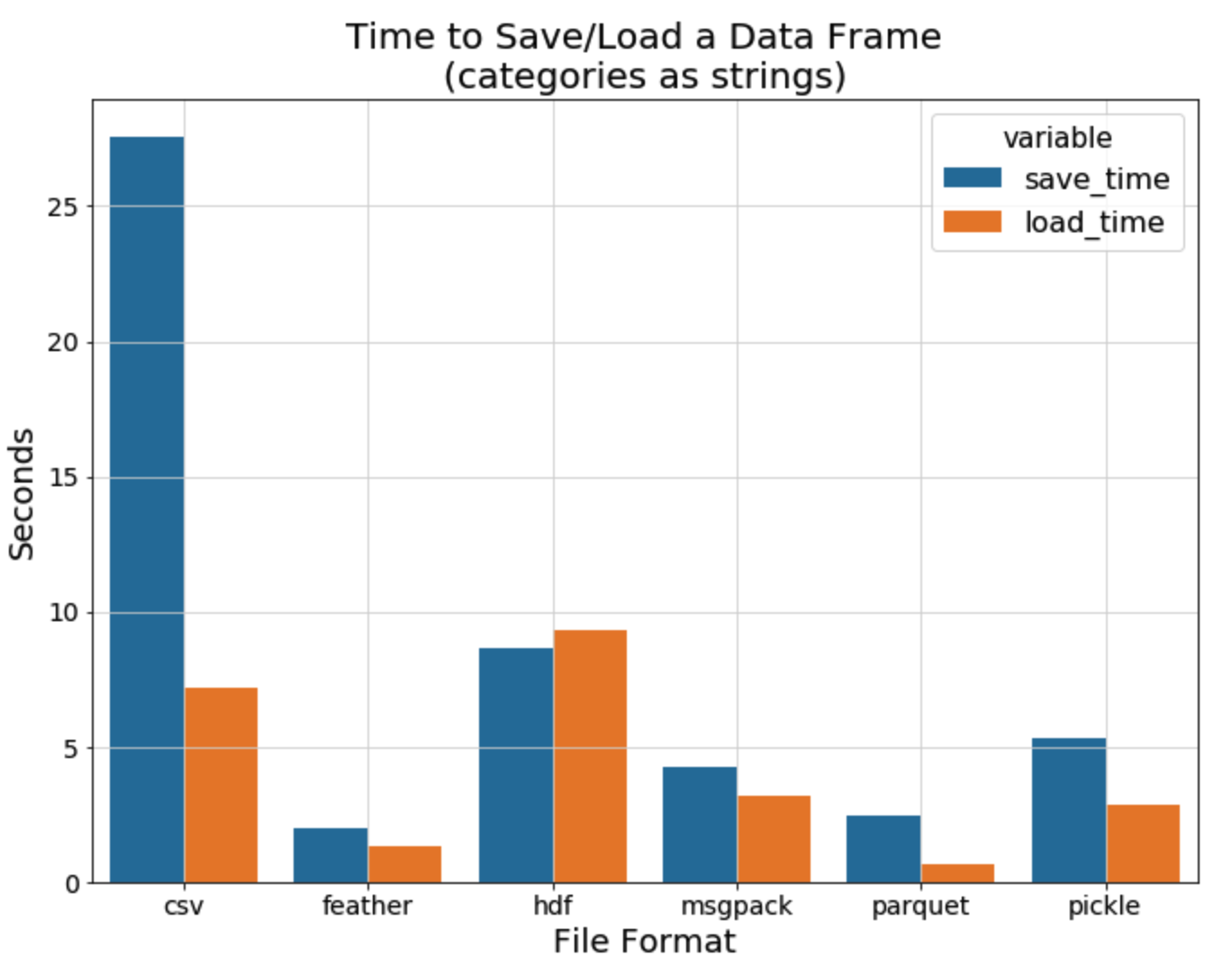 최근에 나온 post들 중에 그래프 하나. 믿진 말자!
최근에 나온 post들 중에 그래프 하나. 믿진 말자!
사실 실험환경, 벤치마크하려는 데이터, compressed 유무에 따라서 사람들마다 측정하게 달라졌기 때문에, 정확히 어떤게 답이 라고는 말은 못하지만, 최근 동향상 pickle은 dataframe을 Load하고 save하는데 있어서 가장 빠른 package중 하나인 것은 사실인 것 같다. 만약 pickle의 성능에 의문이 든다면 자신의 dataset으로 간단하게 검증해보면 좋을 것같다.
Why pickle?
pickle을 사용하는 이유는 load,save하는데 빨라서 사용하는것이 가장 큰 이유지만, 또 다른 이유도 있다. process들은 memory를 share하지 않고, 자신들만의 memory영역을 할당 받는다. 갑자기 process 얘기를 한 이유는 다음과 같다.pickle을 이용하면 process간 데이터를 serialization을 통해 주고 받을 수 있다. 즉, multiprocessing을 할때 pickle을 사용하면 processing한 데이터를 주고 받으며 작업을 이어 나갈 수 있다는 것이다. data augmentation할 경우에도 많은 반복적인 연산이 필요하기 때문에 multiprocessing이 필요하다. 또는 내가 작성한 Matrix Factorization 코드에서 전처리 할때도, process끼리 현재 작업 상황에 정보를 pickle을 이용하여 공유하며 더 빠르게 작업을 할 수 있다는 말이다. (나중에 multiprocessing에 대한 글을 작성하게 되면 어떻게 바꿨는지 작성해보겠다.) 또한, pytorch 자체의 torch.save, torch.load method들이 pickle을 사용하여 구현되어 있고, save할때는 serialization, load할때는 deserialization을 통해 동작한다.
+) Parquet, HDF5, Pickle
pandas dataframes을 save/load하는데 주로 사용하는 Parquet, HDF5, Pickle에 대해 장단점을 분석해보면 다음과 같다.
- Paquet
- pros
- binary stroge format 중 많은 곳에서 호환되고, 가장 빠른 format 중 하나이다.
- Snappy codec과 같은 방법을 사용하여 매우 빠른 compression method를 지원한다.
- Apache Spark, Hadoop와 같은 대용량 데이터 처리에 지원된다.
- cos
- 전체 데이터셋이 메모리에 올라와 있어야 한다. 작은 subset만을 읽을 수 없다. 이 문제에 대해 partitioning을 이용하면 해결 될 수 있지만, 그 해당 partition만 읽을 수 있게 된다. 다른 말로는 Indexing을 지원하지 않는다.
- parquet file들은 immutable하다. append, update, delete가 불가능하다. BigData에서는 이 제한이 장점으로도 작용하는 경우가 있다고 한다.
- pros
- HDF5 (HDF5에 대한 자세한 내용은 다음 링크를 참고.)
- pros
- data slicing을 지원한다. 전체 dataset에 대해 일부분을 읽을 수 있다.
- 다른 binary format보다 빠른 편이다.
- parquet보다는 느리지만 compression을 지원한다.
- appending row를 지원한다. 즉 mutable하다.
- cons
- data들이 corruption할 위험성이 있다.
- pros
- Pickle
- cons
- 매우 매우 빠르다.
- pros
- disk에 많은 공간이 필요하다.
- 오랜 기간 지속적으로 저장하게 되면 compatibility problem이 생길 수 있다. 위에서 설명한 protocol version에 따른 호환성 문제를 야기 시킬수 있다는 말이다.
- cons