Handling Large dataset in python(1)
02 Jan 2022
100k 데이터로 학습을 시키다가, 20M 데이터로 학습을 시키려니 생각보다 load,save하는데에 시간이 많이 걸려서 학습하는데 문제가 되었다. 대회에서는 baseline code에 pickle 패키지로 data load를 모두 구현해되어 제공되서, 손댈 필요가 없었지만, 파이프라인을 직접 다 짜보면서 공부의 필요성을 느껴 포스터를 작성하게 되었다.
이번 Handling Large dataset in python에서 다룰내용은 다음과 같다.
- numpy, pandas가 데이터를 처리하는데 있어서 왜 빠른지, 내부구현은 어떻게 되어있는지 알아보자.
- pickle package는 무엇이고, 어떻게 사용하고, 진짜 빠른지, 그리고 왜 사용하는지 알아보자.
설명하기에 앞서, (vanila) for loop와 vectorization의 속도가 얼마나 차이 나는지 확인해보자.
import numpy as np
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a, b)
toc = time.time()
print("Vectorised version: " + str(1000*(toc-tic)) + "ms")
c = 0
tic = time.time()
for i in range(1000000):
c += a[i] * b[i]
toc = time.time()
print("For loop: " + str(1000*(toc-tic)) + "ms")
Vectorised version: 2.011537551879883ms
For loop: 539.8685932159424ms
1M정도의 값에서도 250배가 차이난다. 데이터의 크기가 점점 더 커질수록 위 방법들에 대한 차이는 훨씬 큰 폭으로 증가할 것이다.
Vectorizing with Pandas and Numpy
for loop에서 시간복잡도는 O(for loop이 iterate되는 횟수 * 각 loop에서 행해지는 연산의 시간) 이라고 할수 있다. 하지만 같은 연산에 대해 numpy, pandas의 vectorization을 사용하면 1000배는 더 빠르게 같은 연산을 할 수 있다. vectorization이 무엇인지 살펴보자.
Vectorization
많은 CPU들의 ‘vector’, 또는 ‘SIMD’ instruction set은 네개 이상의 data pieces에 대해 같은 연산을 동시에 한다. Modern x86 chips는 ‘SSE’라는 명령어, ARM chip 또한 ‘NEON’이라고 불리는 vector instruction set이 있다. Vectorization은 loop을 rewriting하는 과정으로, N크기를 갖는 array에 대해 single element 마다 연산을 하여 O(N)걸리는 것이 아닌, 4개 element들을 동시에 연산하여 O(N/4)의 시간으로 연산하는 것을 의미한다. (숫자 4는 대부분의 modern hardware가 4개를 보통 support하여 예시로 들었다.)
배열 두개를 더하는 연산에 대해 for loop, unrolling for loop, vectorizing을 비교하면 다음과 같다.
-
for loop
for (i = 0; i < 1024; i++) { C[i] = A[i]*B[i]; } -
unrolling for loop
for (int i=0; i<16; i+=4) { C[i] = A[i] + B[i]; C[i+1] = A[i+1] + B[i+1]; C[i+2] = A[i+2] + B[i+2]; C[i+3] = A[i+3] + B[i+3]; } -
vectorization
for (int i=0; i<16; i+=4) addFourThingsAtOnceAndStoreResult(&C[i], &A[i], &B[i]);위의 vectorization 연산이 잘 이해 안되면, 다음과 같이 slice연산으로 비슷하게 표현할 수 있을것 같다.
for (i = 0; i < 1024; i+=4) { C[i:i+3] = A[i:i+3]*B[i:i+3]; }
다시 말하면, Vectorization은 기본적으로 for loop을 사용하지 않고, array 또는 series에 대해 연산을 한번에 하는것이다. Pandas에서 column단위 별로 연산하거나, dataframe 전체에 대해 transform을 적용할 때 모두 vectorization 연산을 하는 것이다. Numpy에서 하나의 numpy.ndarray에 들어가 있는 모든 값들은 같은 타입이고, 연산을 하게 되면 C에서의 for loop을 이용해 vectorization 연산을 하고 나서 python으로 돌아오게된다. pandas에서의 iterrows(), apply() method는 for loop의 변형일 뿐, vectorization 연산은 아니다.
How to iterate over rows in a DataFrame in Pandas
만약 dataframe에 대해 연산을 할때 다음 우선순위를 기반으로 연산방법을 정해야한다.
- Vectorization
- Cython routines
- List Comprehensions (vanilla
forloop) DataFrame.apply(): i) Reductions that can be performed in Cython, ii) Iteration in Python spaceDataFrame.itertuples()anditeritems()DataFrame.iterrows()
아래 그림은 위의 연산들에 대해 runtime을 column 두개를 더한다고 했을때를 기준으로 비교해본 결과이다.
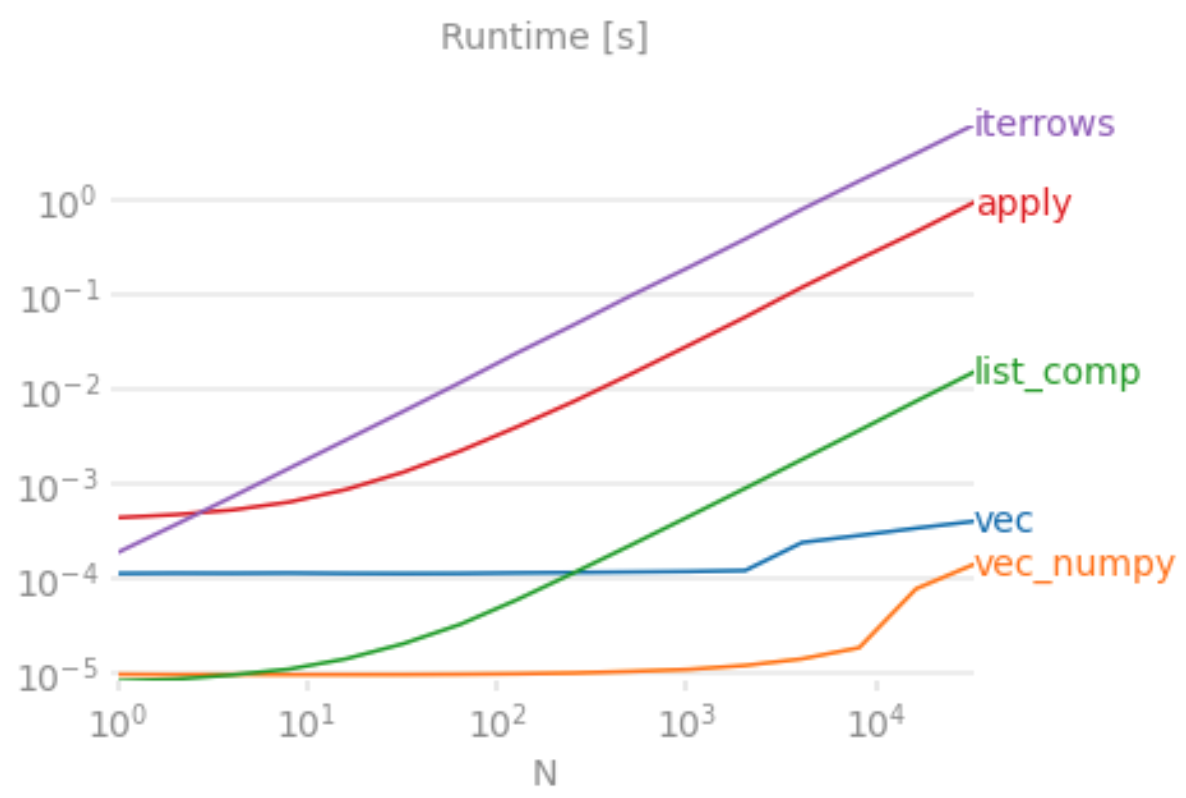
import perfplot
import pandas as pd
def vec(df):
return df['A'] + df['B']
def vec_numpy(df):
return df['A'].to_numpy() + df['B'].to_numpy()
def list_comp(df):
return [x + y for x, y in zip(df['A'], df['B'])]
def apply(df):
return df.apply(lambda row: row['A'] + row['B'], axis=1)
def iterrows(df):
result = []
for index, row in df.iterrows():
result.append(row['A'] + row['B'])
return result
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
kernels = [vec, vec_numpy, list_comp, apply, iterrows]
perfplot.show(
setup=lambda n: pd.concat([df] * n, ignore_index=True),
kernels=kernels,
labels=[str(k.__name__) for k in kernels],
n_range=[2**k for k in range(16)],
xlabel='N',
logx=True,
logy=True)
pyhon이 동적 타이핑 언어이기 때문에, for loop돌때, 매 순간 타입을 지정해줄때도 시간이 더 걸릴 수 있다. 또 numpy에서는 모든 값의 타입이 같기 때문에, memory에 할당할때도, 더 효율적으로 할당되기 때문에 더 빠르게 load될 수 있다. 하지만 pandas와 numpy가 빠른 이유는 vectorization이 주요한 요인이다.
사실 최근에 코드를 짤때, iterrows()와 같이 dataframe을 loop을 돌면서 전처리 하는 코드를 짰다. 이번에 공부하면서 최대한 vectorization 연산을 하는 method를 활용해서 다시 작성하였다. jupyter notebook에서 돌렸을때 작업 속도가 체감될 정도로 차이가 났다.