2021년 회고
31 Dec 2021
올해초부터 12월 31일 오늘까지 방향성 있게 성장했던 한해였던것 같다.
2021년 2월에 구글ML부트캠프 수료한뒤에 computer science 지식이 전무한채로 스타트업 intern 면접을 봤었다. 2차까지 갔던 면접에서 받은 질문들이 지금의 방향성을 잡아줬다고 생각한다.

가령 왜 numpy를 쓰고 어떤이유로 빠르게 작동하는지, 왜 gpu는 cpu보다 빠르게 학습하는지 같은 근본적인 질문부터 실제로 멀티프로세스를 돌려봐야 생각해볼 수 있는 질문들을 받았다. 면접 준비한다고 해서 허겁지겁 1,2주 달달 외운 질문들에 대해선 다 대답했지만 깊이의 차이가 있었다.
그러고서 복학전부터 계획했던 컴공 부전공을 하면서 부족했던 곳들을 점점 채웠다. 운영체제,컴파일러,컴퓨터 네트워크, 컴퓨터 구조론 등등을 모두 수강했다. 운영체제 수업시간땐 매 수업 남아서 거의 한시간동안 교수님한테 물어보고 싶은 것들 다 물어봤었다. 가령 리눅스 command중에 sleep은 왜 쓰는지, shell이 무엇이고 왜 먼저 메모리에 로드되서 작동하는지와 같은 짜잘한 질문들 까지 모두다… 현재 실력으로 완벽히 안다고는 못하지만 예전에 (면접에서) 받았던 질문들에 대해선 훨씬 더 잘 대답할 수 있을것같다.
올해 3월부터 CTP라는 학교 알고리즘에 가입했다. 학기초에 clova ai rush에 참가하느냐 동아리 활동을 열심히 못했지만, 여름방학부터 기말전까지 나름 활발히 활동 했다고 생각한다. 11월에 열린 IUPC 대회에서 진익님이랑 성욱님이랑 팀으로 참가해서 은상(3rd)도 수상했고, acmipc 인터넷 예선전도 나갔었다.
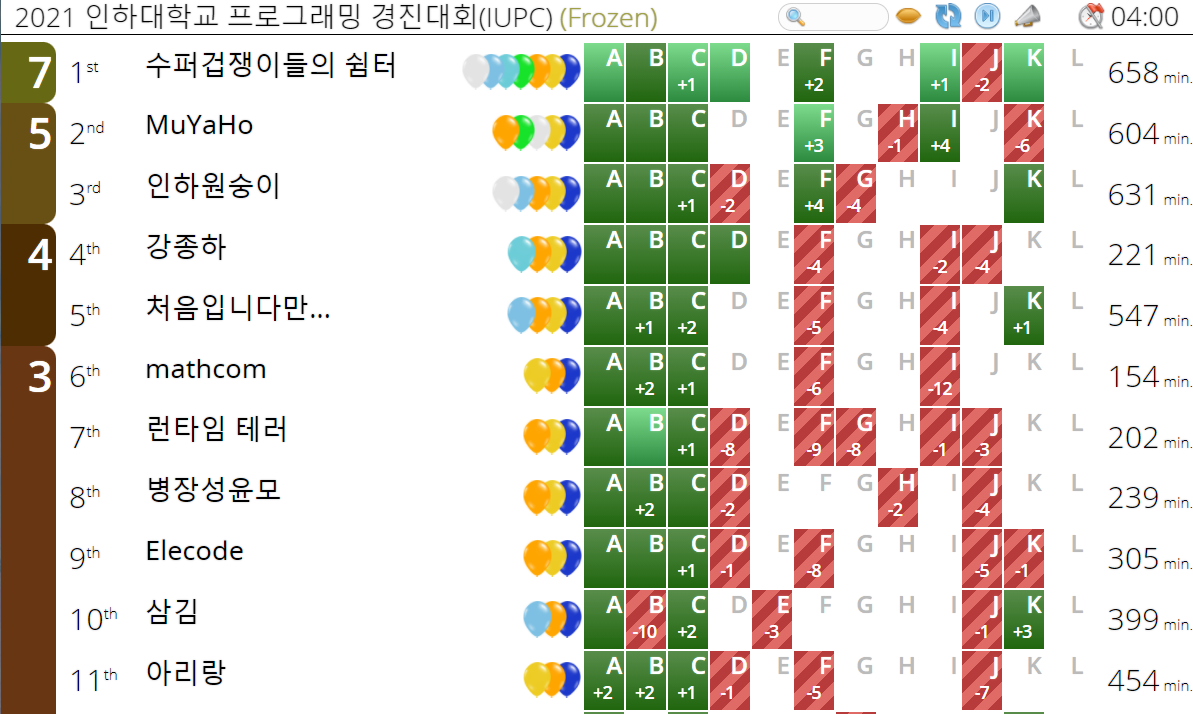 우리팀 이름은 인하원숭이입니다...!
우리팀 이름은 인하원숭이입니다...!
대회에서 처음 만난 사람들이었지만, 같이 문제푸는게 혼자 풀때보다 더 재밌었다. 나름 큰 프로젝트나 규모가 큰 대회도 나가봤었는데, 팀으로 알고리즘 대회나가는 것도 또 다른 매력이 있는것 같다. 기말전에 동아리에서 열린 동아리내 대회에서 1등을 해서, 맥북용 키보드에선 상위티어 키보드인 키크론 k8을 받기도 했다!. (키보드 led 패턴이 무려 15개..!)
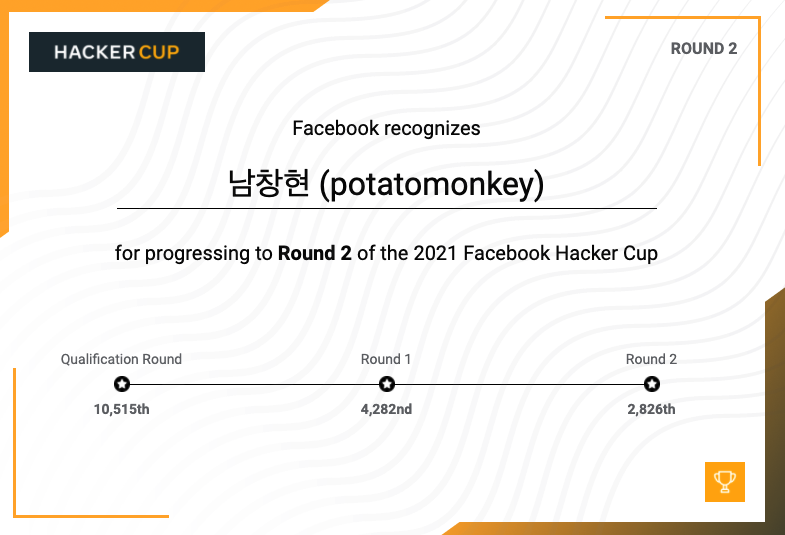 그냥 한번 나가봤다! Round3는 Round2에서 500등안에 들어야 한다고 한다..
그냥 한번 나가봤다! Round3는 Round2에서 500등안에 들어야 한다고 한다..
대학교 입학해서 1,2학년때 학술 동아리 몇몇 군데에 참여해봤는데, ctp처럼 운영진들이 정말 잘 알려주는곳은 없었다. 개인적으로 운영진들이 하시는 수업이 다른데 가면 돈주고 들어야 할만큼 퀄리티 높았다고 생각한다. 그런점을 본받아,동아리 운영진으로 참여하기로 했다. 없는 시간 쪼개서 실력키워서 조금이라도 사람들에게 알려주고 싶다. 올해 안에 백준 500문제 풀기, 코포 민트가 목표였는데 둘다 못했다. 좀 더 열심히 해야할것같다. 그리고 ps나 알고리즘 공부하는 것에 대해 어떤 사람들은 요즘은 중요하지 않다는 사람들도 있다. 이 주제에 대해 나름의 생각이 있는데, ps나 알고리즘은 실제 업무와 정말 100퍼센트 연관되지는 않지만, 어떻게 시스템을 최적화 시킬지 고민하는 프로세스와 일맥상통한다고 생각한다. 단순히 for loop한번 돌릴때 어떤 자료구조를 사용할지, 어떤 구조가 더 효율적인 시간복잡도를 갖을 지와 같은 것들은 개발자라면 항상 해야하는 생각이기 때문이다. 일단 바로 눈앞의 겨울방학때 200문제 넘게 푸는게 목표이다. 1월 15일날 경인대회 shake에 나가기도하고, 운영진으로 활동하려면 그래도 어느 수준까진 실력을 길러야 할것같다.
올해 그래도 내 커리어의 방향성을 잡아준 일 중에 4월초부터 7월초까지 참여했던 ai rush 도 빼먹을 수 없다. 사실 이 대회에 참여하기 전에는 어떤 domain을 파봐야할지 고민이 많았다. computer vision도 재밌고, model을 실제 서비스에 배포하는 파이프라인을 설계하는 MLops도 재밌어서 이것저것 다해보고 있었다. (사실 내 삶의 태도가 기본적으로 안해보곤 모른다는 그러한게 있다.)
그러다가 이 대회를 발견했다. 전체에서 150명뽑고, 본선으로 갈 75명 뽑는다는 것을 봤을때 정말 빡셀것 같아서 걱정이 많이됬다. 그래도 코테는 정말 쉬웠고, 2019년말부터 ml관련해서 해봤던 경험들 덕분에 합격해서 1라운드에 참가했다. 1라운드에서 과제가 6개가 있었는데, 내가 참여한 과제는 시계열데이터로 버스 도착 시간 예측하는 문제였다. 시계열 데이터 관련해서 RNN 기반 attention 모델을 사용했고, 위도 경도 고려해서 데이터 전처리해서 학습을 시켰다. 제출했을때는 2등이었는데 마지막엔 8등으로 끝났다. 2라운드도 그랬지만 한창 대회가 진행되던 기간이 중간고사 1주 전, 기말고사 1주 전이었다. 학습 돌려놓고 밖에 나가서 공부했다. 계속 집에 있다간 전처리나 fine tuning을 계속하는 무한의 굴레에 빠질것 같았다. 그러고서 다행히 75명에 들어 본선에 들어 갔다.
 코테는 정말 쉬웠습니다! 관심있다면 다들 참가하세요!
코테는 정말 쉬웠습니다! 관심있다면 다들 참가하세요!
내가 참여한 과제는 키워드 분류하는 과제였다. 이때 처음 NLP라는 분야에 매력을 느꼈다. 블로그의 제목, 본문, 글 작성자가 정한 키워드 들을 토대로 해당 포스트가 어떤 키워드들에 들어갈지 multi-labeling, extreme classification하는 과제였다. 주어진 단어 corpus에서 분류에 도움이 되지 않을 것이라고 생각하여 내 기준으로 stopword들을(ㅋㅋㅋ,ㅎㅎㅎ와 같은 의성어나 조사, 관형사, 수사같은 것들) 데이터에서 제거하여 gensim으로 word2vec을 다시 만들었다. 그러고나서 attention이나 bi-lstm이나 여러 모델을 시도 해봤다. 결론적으로 (해당과제에서) 7등으로 끝났다. 수상권에도 못들은것과 동시에 5등에 들었으면 2년간 코테면제 기회를 날려서 너무 아쉬웠다. 하지만 한편으로는 내가 부족했던 부분과 어떤 domain을 파야할지 결정할 계기가 되었다. 일단 docker image파일을 올리거나 받는걸 아예 몰랐다. 네이버에서 제공하는 gpu sever인 nsml은 docker기반으로 돌아가는데, BERT와 같은 pretrained model을 올려놓고 사용해보려면 docker의 기본적인 command와 기본적인 원리는 이해해야 했다. 그리고 pretrained model들에 대해서도 튜토리얼만 돌려봤지, 실제 데이터를 bert에 넣으려면 어떻게 전처리해야 하는지와 같은 경험도 전무 했다. Token/segment/position embedding을 어떻게 처리해야 하는지 감이 안왔다. 이것 외에도 정말 부족하다고 느낌점이 많았지만 더 중요한 것은 nlp가 앞으로 내 커리어를 맡길만큼 재밌는 분야라는 것을 느꼈다는 것이다. 이 대회가 끝난 직후에 어떤 논문들과 수업을 들어야하는지 서치했고, 현재는 CS224N을 다 수강했고, 하나씩 정리해서 블로그에 올리고 있고, 또 논문들도 하나씩 읽어보고 있다.
추가로, 내가 참여한 과제를 맡은 팀이 naver에 Airs라는 추천시스템 팀이었는데, 단어 토큰들을 nlp 모델로 feature를 뽑아내서 추천모델에 넣는 일들도 하고 있었다. 담당자에게 진로 관련 질문도 해도 된다해서, 내가 물어봤던것은 ml engineer가 어느정도의 웹 프로그래밍 지식을 알고 있어야 하는지 궁금했다. 결국엔 모델도 서버에서 데이터를 받아 웹에 서빙을 할텐데, 어느 수준까지 알아야되는지 궁금했었다. 질문에 대해 받은 답은 웹에 대해 기본적인 것만 알면 된다고 하셨다. 실제 필드에서 모델링만 담당 하시는분은 웹을 전혀 모르시는 경우도 있다고 하셨지만, 담당자 분은 개발한 모델에 대해 간단한 데모버전으로 웹에 올려서 발표하신적도 있다고 하셨다.

그리고 마지막으로 12월 20일부터 참여한 KIST 인공지능 연구단에서 추천시스템 인턴으로 참여한 일이다. 본론부터 얘기하자면, 무려 RTXA6000 8대나 연결된 서버를 할당 받아서 돌려보고 싶은 모델들은 다 돌려보면서 연구하고있다. 현재는 Matrix Factorization 관련한 가장 기본적인 모델과 Neural Collaborative Filtering 모델을 구현해서 돌려봤다. 대략 2주 동안 간단하지만 모델 두개나 구현하여 돌려봐서 뿌듯하다. 사실 추천시스템이라는 분야는 네이버 airs(앞에서 말햇던)팀 때문에 관심이 있었지만, 어떻게 공부해야할지 감이 안왔던 분야이다. 단순히 GNN기반 추천시스템이 요즘 sota모델인 정도만 알았다. 인턴으로 공부 하면서 이해한 바로는 추천시스템 또한 다른 분야들 처럼 target value에 대해 학습시키는것은 똑같으나, 다른 종류의 metric들을 기반으로 더 잘 추천 해주는 모델을 만드는것이 목적이다.
모델을 구현하면서 부딪힌 문제점이 있는데, 데이터 로딩, 전처리 과정에서 비효율적으로 loop을 돌고, 최적화 되지 않은 채로 학습을 하면 크기가 100k정도의 작은 데이터 셋의 경우 문제가 되지 않지만, 데이터가 20M일 겅우 학습이 정말 느렸다. 현재는 pickle, parquet package 사용하거나 전처리 하는 부분에서 멀티 프로세스 이용해서 넘기면 더 빨라지지 않을까 고민하고 있다. 모델 구현에서 최적화가 얼마나 중요한지 몸소 겪으며 공부하고 있다. 앞으로의 계획은 주어진 dataset에 대해 구현 해볼 수 있는 모든 모델을 적용시켜보는 것이다. ALS Optimizer도 구현해보고, GNN 기반 모델도 구현해보고 싶다. 언제 또 이런 환경에서 공부를 해볼까 싶다! (내년 여름,겨울방학?! ㅋㅋ)
 kist에서 지금까지 구현한 모델들
kist에서 지금까지 구현한 모델들
정말 마지막으로, 중간고사 끝나고 같은과 친구랑 코세라 mlops강의 스터디를 진행했었다. 위에서 말했다 시피 다 해보는 성격이라 일단 부딪히면서 깨닫는 스타일이다. 각자의 사정으로 인해 조기 중단 되었지만, model의 코드는 전체 ml pipe line code에서 5퍼센트 밖이 되지않고, 실제 서비스까지 연결되는 pipeline의 각 요소에 어떤게 있는지 배웠다.
내가 되고 싶은 ML엔지니어는, 실제 서비스에서 효율적이고 최적화된 파이프라인과 모델링을 구현하는 엔지니어다. 모델에 대해 단순히 특정 metric만 충족하면 끝나는게 아니라, 데이셋의 규모에 최적화된 모델을 구현하는 실력을 갖추고 싶다.