GPU 할당해서 사용하는법
24 Dec 2021
gpu를 할당해서 사용하기 위한 간단한 command입니다.
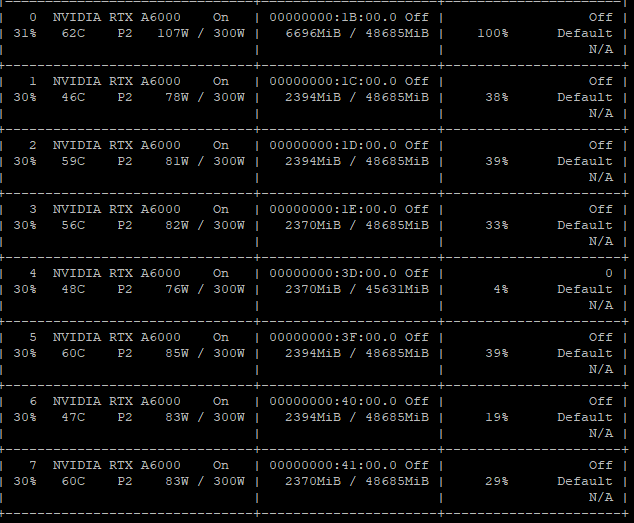
GPU 사용 정보 확인
$ nvidia-smi
각각 gpu의 정보를 나타냅니다. 2개 혹은 그 이상의 gpu를 사용할 시에, 첫번째꺼 부터 사용량이 올라가고, 점차 나머지 것들도 사용하게 되는 것을 확인할 수 있습니다.
Python에서 사용하는 GPU info 출력
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('device:', device)
print('Current cuda device:', torch.cuda.current_device())
print('Count of using GPUs:', torch.cuda.device_count())
현재 어떤 gpu들을 사용하고 있고, 몇개를 사용하고 있는지 출력합니다.
Command line에서 GPU할당
CUDA_VISIBLE_DEVICES라는 envirable variable를 변경하여 cuda가 볼 수 있는 GPU를 사용하고자 하는 다른 GPU로 제한하는 command입니다. cuda는 visible한 gpu를 사용하는데, 인위적으로 visible devices를 변경함으로서, cuda가 명시한 GPU만을 사용하도록 하는 방법입니다.
CUDA_VISIBLE_DEVICES= 0,1,2 python train.py -e 30 -b 32 -d True
CUDA_VISIBLE_DEVICES 를 사용하여 gpu를 할당하여 사용할 수 있습니다.
CUDA_VISIBLE_DEVICES= 0,1,2 python train.py -e 30 -b 32 -d True&
‘&’를 붙여서 실행하면 백그라운드에서 돌아가게 됩니다.
ps
74082 ttys000 0:00.08 /bin/zsh --login -i
75905 ttys001 0:00.03 -zsh
ps 를 사용하시면 현재 돌아가고 있는 프로세스들을 확인할 수 있습니다. foreground process를 종료시킬때는 ctrl+c 를 사용하시면 되고, background process를 종료시킬때는 kill pid값 을 사용하면 됩니다.
Multi-GPU를 이용하여 parallel하게 학습시키는 방법
간단한 모델이 다음과 같다고 해봅시다.
class Model(nn.Module):
# 우리의 모델
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
nn.DataParallel 를 이용하여 모델을 warppingg한 후에 .to(device) 를 이용하여 모델을 gpu에 넣을 수 있습니다.
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)