CS224N|Lecture 8 Machine Translation, Seq2Seq and Attention
21 Nov 2021
Machine Translation의 발전과정과 그 과정에 있었던 Statistical Machine Translation(SMT)를 배우고, SMT의 alignment에 대한 원리를 배웁니다. 그다음 Vanilla RNN을 사용한 NMT와 그것의 문제점, 그 문제점을 해결하는 Attention에 대해 배웁니다. Attention에 대해서 SMT에서의 alignment와 비교하며 배우는게 정말 흥미로웠습니다!.
 lecture 8에서는 새로운 task인 Machine Translation(파파고!), 새로운 neural architecture인 sequence to sequence, 새로운 neural technique인 attention을 배웠다.
lecture 8에서는 새로운 task인 Machine Translation(파파고!), 새로운 neural architecture인 sequence to sequence, 새로운 neural technique인 attention을 배웠다.
 간단하게 MT task가 무엇이고, 그에 대한 역사에 대해서 먼저 살펴보자.
Machine Translation task는 어떤 문장을 source language에서 target language로 translate하는 task 입니다. 위의 문장은 루소의 사회계약론 첫장의 첫줄이라고 한다.
1950년도 초기에 MT 연구가 시작되었고, 그 당시 시스템은 rule based 였다.
간단하게 MT task가 무엇이고, 그에 대한 역사에 대해서 먼저 살펴보자.
Machine Translation task는 어떤 문장을 source language에서 target language로 translate하는 task 입니다. 위의 문장은 루소의 사회계약론 첫장의 첫줄이라고 한다.
1950년도 초기에 MT 연구가 시작되었고, 그 당시 시스템은 rule based 였다.
 1990s - 2010s 에서는 statistical Machine Translation(SMT)을 사용했다.
argmaxyP(y∣x) : 주어진 문장 x에 대해 최적의 y를 찾는 문제이다. 베이지안 rule을 이용해서 이 식을 두개의 component로 나눌 수 있다. P(x∣y) : parallel data로부터 어떻게 단어를 번역해야 하는지에 대한 모델이고, P(y) : 다음 단어를 예측하는 모델 또는 다음 sequence of words의 probability를 의미한다고 할수 있다.
1990s - 2010s 에서는 statistical Machine Translation(SMT)을 사용했다.
argmaxyP(y∣x) : 주어진 문장 x에 대해 최적의 y를 찾는 문제이다. 베이지안 rule을 이용해서 이 식을 두개의 component로 나눌 수 있다. P(x∣y) : parallel data로부터 어떻게 단어를 번역해야 하는지에 대한 모델이고, P(y) : 다음 단어를 예측하는 모델 또는 다음 sequence of words의 probability를 의미한다고 할수 있다.
 그렇다면 translation model인 P(x∣y)는 어떻게 학습할까? large amount of parallel data( 같은 문장에 대해 영어와 프랑스어로 human-translate된 pair)가 필요하다.
그렇다면 translation model인 P(x∣y)는 어떻게 학습할까? large amount of parallel data( 같은 문장에 대해 영어와 프랑스어로 human-translate된 pair)가 필요하다.
 그렇다면 large corpus으로부터 어떻게 배울까? latent variable a라는 것을 모델에 추가한다. a(alignment)는 source sentence x와 target sentence y에 대해 얼마나 correspond 한지 나타내는 값이다.
그렇다면 large corpus으로부터 어떻게 배울까? latent variable a라는 것을 모델에 추가한다. a(alignment)는 source sentence x와 target sentence y에 대해 얼마나 correspond 한지 나타내는 값이다.
 언어 사이의 typological 차이는 복잡한 alignment를 만든다. 프랑스어에서 여성형 단수를 의미하는 “Le”와 같은 spurious word는 counterpart가 없다. 위의 예시는 one-to-one alignment로써, 정확히 같은 순서로 대응된다.
언어 사이의 typological 차이는 복잡한 alignment를 만든다. 프랑스어에서 여성형 단수를 의미하는 “Le”와 같은 spurious word는 counterpart가 없다. 위의 예시는 one-to-one alignment로써, 정확히 같은 순서로 대응된다.
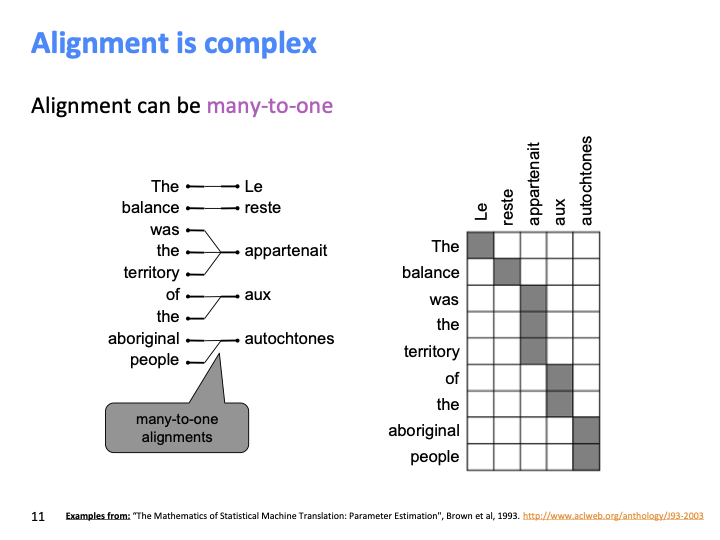 alignment는 many-to-one이 될 수 있다.
alignment는 many-to-one이 될 수 있다.
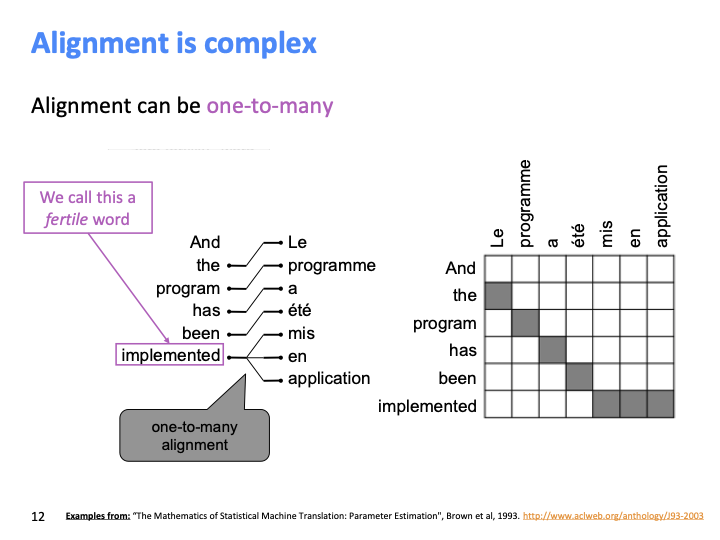 그리고 반대로 one-to-many 또한 가능하고, 이런 단어를 fertile word라고 한다. fertile word는 target sentence에 많은 children이 있다. (트리의 관점)
—
그리고 반대로 one-to-many 또한 가능하고, 이런 단어를 fertile word라고 한다. fertile word는 target sentence에 많은 children이 있다. (트리의 관점)
—
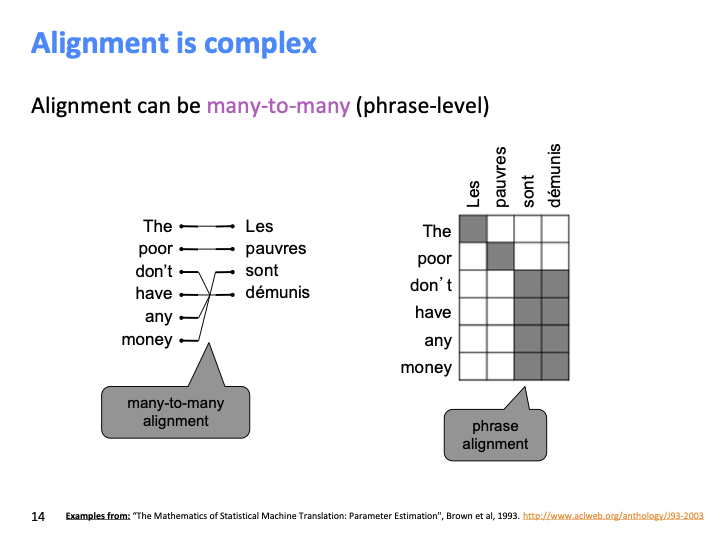 당연하게도 alignment는 many-to-many가 될 수 있다.
—
당연하게도 alignment는 many-to-many가 될 수 있다.
—
 주어진 y에 대한 x,a의 확률을 학습해야 하고, 이 모든 것들이 parallel data로부터 학습된다. SMT의 overview를 살펴보고, 이것을 후반부에 나오는 Neural MT와 비교할 것이다.
a는 latent variable로써, data에 specify되지 않는다. 이것을 학습하기 위해선 Expectation-Maximization과 같이 latent variable을 이용한 parameter distribuition을 학습하는 특별한 학습 알고리즘이 요구된다. (이것에 대해선 다루지 않습니다.)
주어진 y에 대한 x,a의 확률을 학습해야 하고, 이 모든 것들이 parallel data로부터 학습된다. SMT의 overview를 살펴보고, 이것을 후반부에 나오는 Neural MT와 비교할 것이다.
a는 latent variable로써, data에 specify되지 않는다. 이것을 학습하기 위해선 Expectation-Maximization과 같이 latent variable을 이용한 parameter distribuition을 학습하는 특별한 학습 알고리즘이 요구된다. (이것에 대해선 다루지 않습니다.)
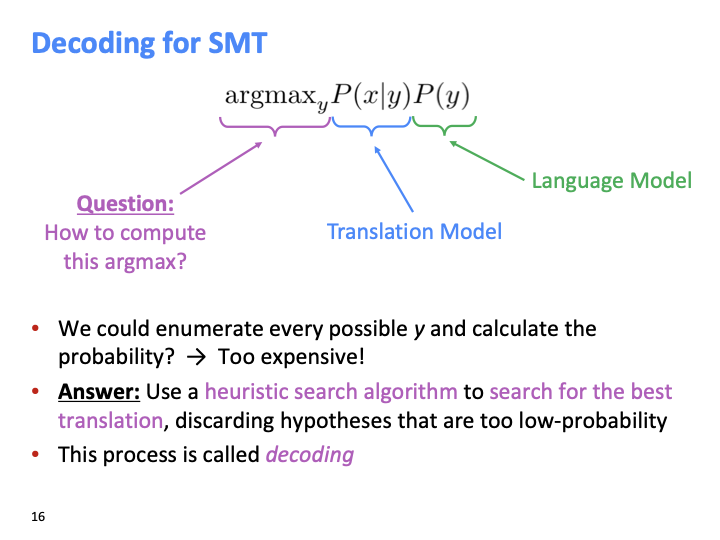 argmax over y를 어떻게 계산할까? 처음 해볼수 있는 것은 브루트포스 알고리즘이고, 이는 비용이 너무 비싸다. 그래서 휴리스틱한 search algorithm으로, 낮은 확률의 가정들을 discard함으로써 가장 좋은 번역을 찾는 방법을 사용해야 한다. 이러한 best sequence를 찾는 process를 decoding이라 한다.
argmax over y를 어떻게 계산할까? 처음 해볼수 있는 것은 브루트포스 알고리즘이고, 이는 비용이 너무 비싸다. 그래서 휴리스틱한 search algorithm으로, 낮은 확률의 가정들을 discard함으로써 가장 좋은 번역을 찾는 방법을 사용해야 한다. 이러한 best sequence를 찾는 process를 decoding이라 한다.
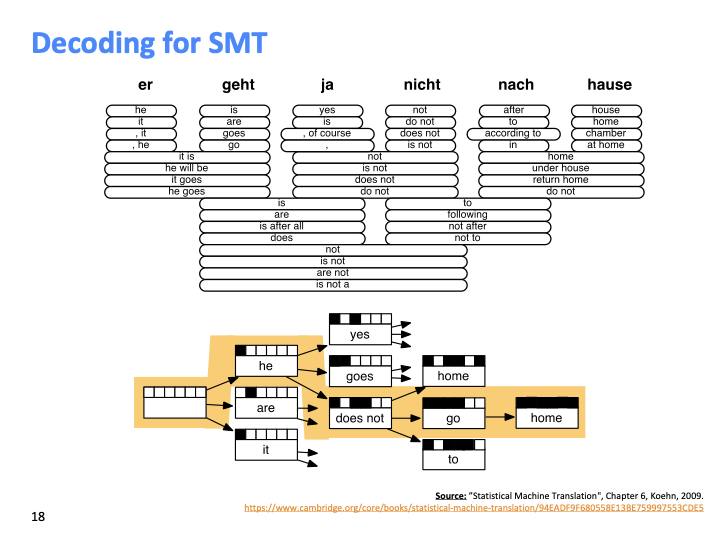 각 단어에 대해 translate될 수 있는 많은 다양한 hypothesis를 고려해 보자. 여기서 낮은 확률의 hypothesis은 버린다. 이것을 tree의 형태로 구성할 수 있고, 저 노란색이 최적의 sequence라고 할 수 있다. 이러한 decoding과정을 후반부의 neural net 관점에서 더 배운다.
각 단어에 대해 translate될 수 있는 많은 다양한 hypothesis를 고려해 보자. 여기서 낮은 확률의 hypothesis은 버린다. 이것을 tree의 형태로 구성할 수 있고, 저 노란색이 최적의 sequence라고 할 수 있다. 이러한 decoding과정을 후반부의 neural net 관점에서 더 배운다.
 SMT는 매우 huge한 research field이고, 가장 좋은 시스템은 매우 복잡하다. 제일 문제가 되는 것은 different language 마다 different resource가 필요하고, 많은 human effort가 필요하다는 것이다. 이제 Neural Machine Translation(NMT)를 보자.
SMT는 매우 huge한 research field이고, 가장 좋은 시스템은 매우 복잡하다. 제일 문제가 되는 것은 different language 마다 different resource가 필요하고, 많은 human effort가 필요하다는 것이다. 이제 Neural Machine Translation(NMT)를 보자.
NMT의 기본적인 구조는 seq2seq으로 두개의 RNN으로 이루어져있다.
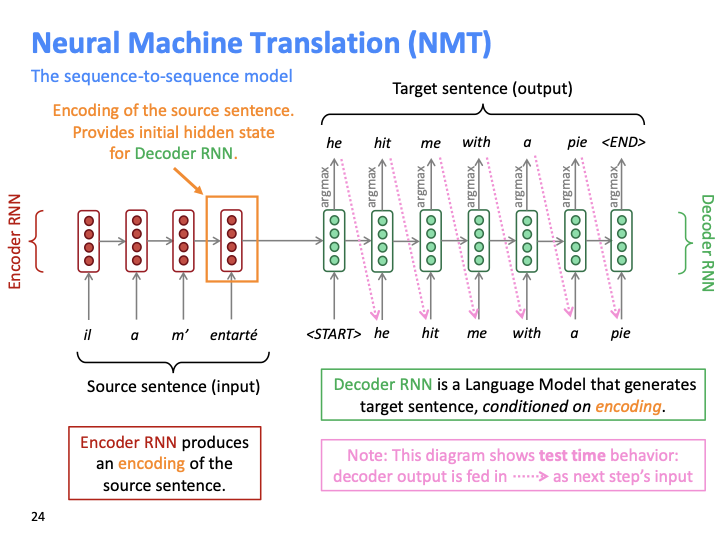 source/target sentence 각각에 대해 word embedding이 필요하고, 위 slide에서는 vanilla RNN으로 묘사했지만 Bidirectional LSTM/GRU 등 모두 가능하다. target sentence에서
source/target sentence 각각에 대해 word embedding이 필요하고, 위 slide에서는 vanilla RNN으로 묘사했지만 Bidirectional LSTM/GRU 등 모두 가능하다. target sentence에서
Sequence-to-sequence is versatile
sequence-to-sequence 구조는 MT 뿐만 아니라 다양한 task에서 활용될 수 있다.
- summarization : long text → short text
- dialogue : previous utterances → next utterance
- parsing : input text → output parse as sequence
- code generation : natural language → python code
 다음 단어를 예측하기 때문에 decoder 자체가 LM이고, encoding된 source sentence에 conditional 합니다. SMT는 에서는 P(y∣x)를 directly learn하지 않고, alignment를 이용한 P(x,a∣y)P(y) 같이 break down하여 학습했습니다. NMT는 P(y∣x) 자체를 직접 학습합니다.
다음 단어를 예측하기 때문에 decoder 자체가 LM이고, encoding된 source sentence에 conditional 합니다. SMT는 에서는 P(y∣x)를 directly learn하지 않고, alignment를 이용한 P(x,a∣y)P(y) 같이 break down하여 학습했습니다. NMT는 P(y∣x) 자체를 직접 학습합니다.
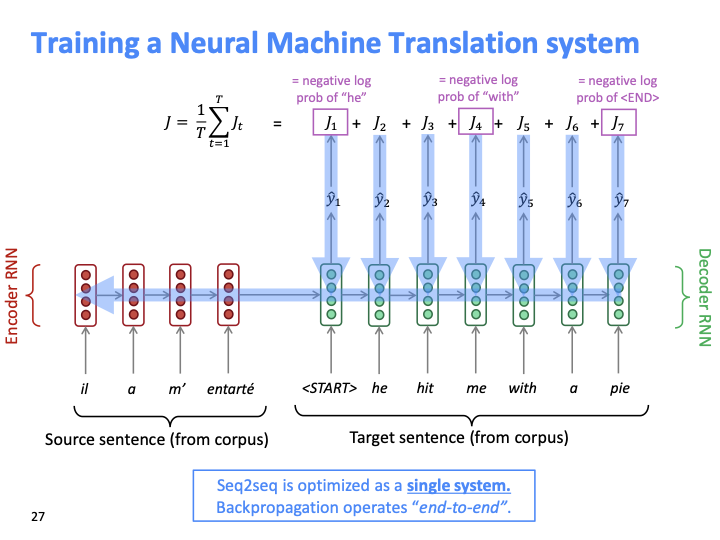 loss는 다음 올바른 단어에 대한 negative log probability입니다. Training 단계에서는 test때와 다르게 output(Ji) 을 다음 step으로 feed하지 않고, corpus에 있는 target sentence를 feed합니다.
loss는 다음 올바른 단어에 대한 negative log probability입니다. Training 단계에서는 test때와 다르게 output(Ji) 을 다음 step으로 feed하지 않고, corpus에 있는 target sentence를 feed합니다.
학생의 질문
- NMT를 end-to-end로 만드는 이유(decoder,encoder를 따로 따로 학습 하지 않고)에 대한 것이 있었다. encoder와 decoder를 분리하여 학습하게 되면 따로 optimize되어 합쳤을때도 optimize된다는 보장이 없다고 했다. end-to-end를 선호하는 이유는 한번에 optimize가 가능하다.
- target, source text 길이에 대해서 어떻게 정하는지 에대한 질문. max_length를 정한뒤, padding을 사용하고 hidden state가 padding으로 부터 학습되지 않게 하면 된다고 했다.
 위에서 살펴본 NMT의 decoder에서 target sentence를 예측할때 argmax를 사용하고, 이 방법을 greedy decoding이라고 합니다. greedy decoding은 어떤 점이 문제인지 조교(수업 Lecturer)가 물어봤다. 전체문장에 대해 argmax를 하는 것이 아니라 지금 step에서 가장 probable한 단어를 predict하는 것이 문제이다. (만약 다음 단어를 잘못 예측하면 뒤로 돌아갈수 도 없다. ㅋㅋ)
Exhaustive search decoding 방법 또한 같은 이유로 전체 vocab에 대해서 가 아닌 partial vocab에 대해 찾는 것이 이기 때문에 좋지 않다.
위에서 살펴본 NMT의 decoder에서 target sentence를 예측할때 argmax를 사용하고, 이 방법을 greedy decoding이라고 합니다. greedy decoding은 어떤 점이 문제인지 조교(수업 Lecturer)가 물어봤다. 전체문장에 대해 argmax를 하는 것이 아니라 지금 step에서 가장 probable한 단어를 predict하는 것이 문제이다. (만약 다음 단어를 잘못 예측하면 뒤로 돌아갈수 도 없다. ㅋㅋ)
Exhaustive search decoding 방법 또한 같은 이유로 전체 vocab에 대해서 가 아닌 partial vocab에 대해 찾는 것이 이기 때문에 좋지 않다.
 Beam search decoding은 beam size 만큼 가장 probable한 partial translation 후보를 저장(keep track)한다. 이 후보들을 hypotheses라 부른다. 그리고 각 hypothesis에 대해서 beam score가 존재하고, 이것은 log probability이다. beam search는 optimal solution을 보장하진 못하지만 위의 search들보다 훨씬 효율적이다.
Beam search decoding은 beam size 만큼 가장 probable한 partial translation 후보를 저장(keep track)한다. 이 후보들을 hypotheses라 부른다. 그리고 각 hypothesis에 대해서 beam score가 존재하고, 이것은 log probability이다. beam search는 optimal solution을 보장하진 못하지만 위의 search들보다 훨씬 효율적이다.
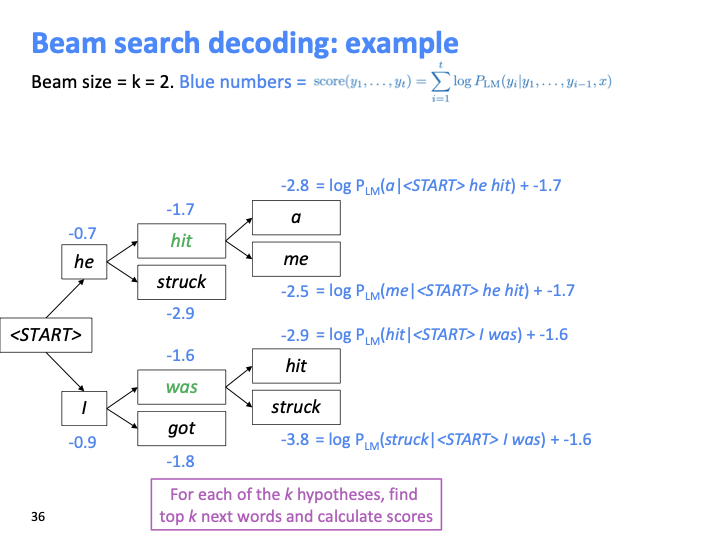 위와 같이 log probability의 합을 누적하여 계산하고, (k=beam size) k2개의 가정에 대해 k개의 가장 높은 beam score의 가정만 keep track한다.
위와 같이 log probability의 합을 누적하여 계산하고, (k=beam size) k2개의 가정에 대해 k개의 가장 높은 beam score의 가정만 keep track한다.
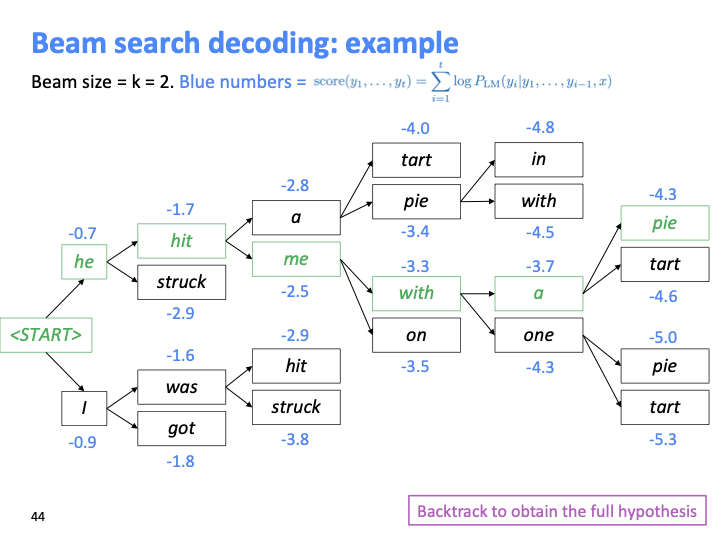 마지막 step에서 가장 높은 hypothesis를 찾으면 back track하여 전체 hypothesis를 얻는다.
마지막 step에서 가장 높은 hypothesis를 찾으면 back track하여 전체 hypothesis를 얻는다.
 greed decoding은
greed decoding은
 beam search를 하는 위의 슬라이드를 보면 각 time step마다 negative log probability 값을 계속 더해나가서 hypothesis가 길면 길수록 beam score가 더 낮아질 수 밖이 없다. 가장 짧은 hypothesis가 best hypothesis로 선택될 문제점이 발생할 수 있습니다. 그래서 이를 해결하기 위해 normalize를 score에 적용한다.
학생 질문 중에 beam search 도중에 normalize를 하지 않는 이유에 대한 것이 있었다. search하는 중에 적용할 수는 있지만, 같은 길이의 hypothesis의 score만 비교하기 때문에 의미가 없습니다.
beam search를 하는 위의 슬라이드를 보면 각 time step마다 negative log probability 값을 계속 더해나가서 hypothesis가 길면 길수록 beam score가 더 낮아질 수 밖이 없다. 가장 짧은 hypothesis가 best hypothesis로 선택될 문제점이 발생할 수 있습니다. 그래서 이를 해결하기 위해 normalize를 score에 적용한다.
학생 질문 중에 beam search 도중에 normalize를 하지 않는 이유에 대한 것이 있었다. search하는 중에 적용할 수는 있지만, 같은 길이의 hypothesis의 score만 비교하기 때문에 의미가 없습니다.
 NMT의 이점은 위와 같습니다. 하지만 단점도 또한 존재합니다.
NMT의 이점은 위와 같습니다. 하지만 단점도 또한 존재합니다.
 첫번째로 어떤 error가 발생했을때, neural net을 살펴보고 어떤 bug가 발생했는지 이해하는 것이 불가능합니다. 다시말하면, debug하기가 매우 어렵습니다. 이에 반해 SMT는 더 interpretable합니다.
두번째 어떤 단어가 특정 방식으로 해석되게 할수 없습니다. Rule을 impose하는 것이 불가능 합니다.
첫번째로 어떤 error가 발생했을때, neural net을 살펴보고 어떤 bug가 발생했는지 이해하는 것이 불가능합니다. 다시말하면, debug하기가 매우 어렵습니다. 이에 반해 SMT는 더 interpretable합니다.
두번째 어떤 단어가 특정 방식으로 해석되게 할수 없습니다. Rule을 impose하는 것이 불가능 합니다.
 MT의 evaluation score에 관한 슬라이드 입니다. BLEU는 machine-written translation과 human written translation 사이의 similarity score를 계산합니다. 하지만 좋은 translation임에도 human translation과 덜 겹친다면 나쁜 점수를 얻을 수 있습니다.
MT의 evaluation score에 관한 슬라이드 입니다. BLEU는 machine-written translation과 human written translation 사이의 similarity score를 계산합니다. 하지만 좋은 translation임에도 human translation과 덜 겹친다면 나쁜 점수를 얻을 수 있습니다.
- NMT는 매해 갈수록 매우 큰 발전되는 반면 전통적으로 MT에 쓰였던 syntaxed-based SMT, Phrase-based SMT는 거의 발전되지 않았습니다.
- 2016년에는 NMT 방법이 standard method로써 자리 잡았습니다.
- SMT 시스템은 수백명의 엔지니어에 의해 수십년동안 연구된 반면, NMT는 작은 그룹의 개발자에 의해 몇 개월안에 학습되었습니다.
 하지만 MT에는 아직 문제점이 많습니다.
3번째 maintaining context over longer text는 active research area로, NMT가 너무 비싼 비용을 들이지 않고 larger pieces of context에 condition on할 수있는지도 이와 관련되어 있습니다.
추가적으로 Pronoun(or zero pronoun) resolution error, Failure to accurately capture sentence meaning, Morphological agreement error 등의 문제점도 있습니다.
다음의 슬라이드에서는 MT가 해결하지 못한 예시들을 보여줄것입니다.
하지만 MT에는 아직 문제점이 많습니다.
3번째 maintaining context over longer text는 active research area로, NMT가 너무 비싼 비용을 들이지 않고 larger pieces of context에 condition on할 수있는지도 이와 관련되어 있습니다.
추가적으로 Pronoun(or zero pronoun) resolution error, Failure to accurately capture sentence meaning, Morphological agreement error 등의 문제점도 있습니다.
다음의 슬라이드에서는 MT가 해결하지 못한 예시들을 보여줄것입니다.
 MT는 매우 Limited translation으로, common sense에 대한 어떠한 개념도 없습니다.
MT는 매우 Limited translation으로, common sense에 대한 어떠한 개념도 없습니다.
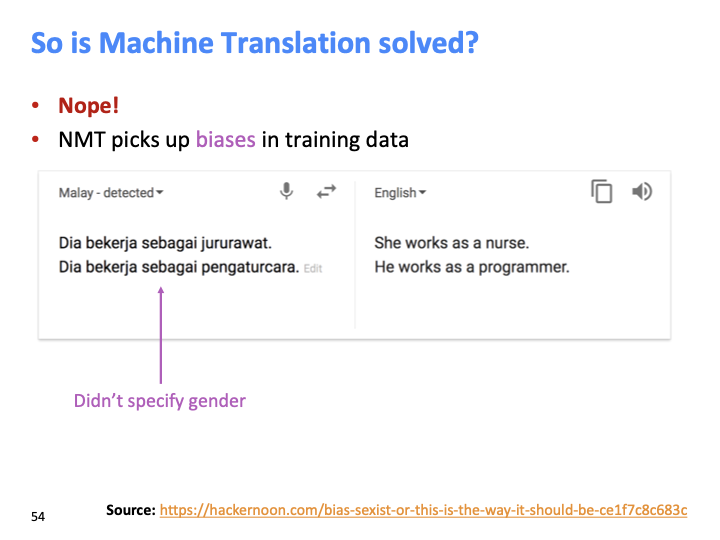 그리고 위와 같이 training data에 biases가 존재할 수 있습니다.
그리고 위와 같이 training data에 biases가 존재할 수 있습니다.
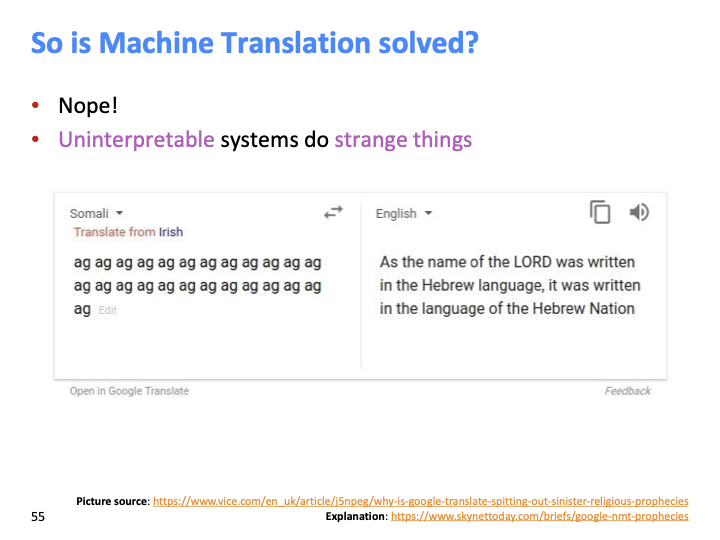 해석 불가능 한것들에 대해 위와 같이 이상한 행동을 합니다. (지금은 해결된듯 합니다.)
somali = 소말리어인데, low resource의 언어에 대해서 가장 좋은 resource는 성경(bible)입니다. 그래서 대부분의 low resource 언어들은 성경을 토대로 학습되기 때문에, 위와 같은 결과가 나옵니다. NMT는 Nonsensible한 resource는 noise로 취급하고, English Language model에서 random text를 generate합니다.
해석 불가능 한것들에 대해 위와 같이 이상한 행동을 합니다. (지금은 해결된듯 합니다.)
somali = 소말리어인데, low resource의 언어에 대해서 가장 좋은 resource는 성경(bible)입니다. 그래서 대부분의 low resource 언어들은 성경을 토대로 학습되기 때문에, 위와 같은 결과가 나옵니다. NMT는 Nonsensible한 resource는 noise로 취급하고, English Language model에서 random text를 generate합니다.
 NMT는 NLP 딥러닝 분야에서 flagship과 같은 task입니다. ATTENTION 이라는 새로운 신경망 구조에 의해 NMT가 계속해서 발전되기 시작했습니다.
NMT는 NLP 딥러닝 분야에서 flagship과 같은 task입니다. ATTENTION 이라는 새로운 신경망 구조에 의해 NMT가 계속해서 발전되기 시작했습니다.
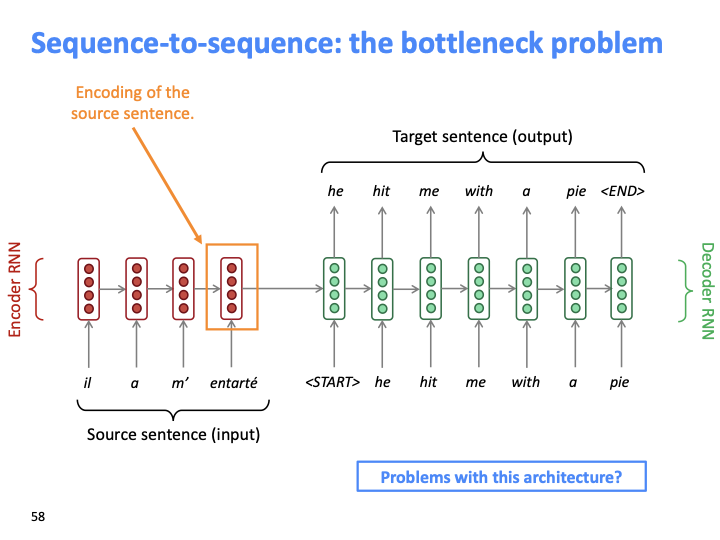 앞서 본 seq-to-seq의 문제점은 encoder의 마지막 벡터(orange box로 쳐있는 )가 전체 source sentence를 represent하고 있습니다. 다시 말하면 마지막 single vector가 일종의 informational bottle neck처럼 작동하고 있습니다. 모든 source sentence의 내용이 이 벡터에 capture되길 forcing하고 있는 구조가 문제점 입니다.
앞서 본 seq-to-seq의 문제점은 encoder의 마지막 벡터(orange box로 쳐있는 )가 전체 source sentence를 represent하고 있습니다. 다시 말하면 마지막 single vector가 일종의 informational bottle neck처럼 작동하고 있습니다. 모든 source sentence의 내용이 이 벡터에 capture되길 forcing하고 있는 구조가 문제점 입니다.
 attention은 이 bottleneck 문제점을 해결할 solution을 제공합니다. 아이디어는 각 step의 decoder에서 source sentence의 특정 부분에 집중하기 위해 encoder에 direct connection을 사용하는것 입니다.
attention은 이 bottleneck 문제점을 해결할 solution을 제공합니다. 아이디어는 각 step의 decoder에서 source sentence의 특정 부분에 집중하기 위해 encoder에 direct connection을 사용하는것 입니다.
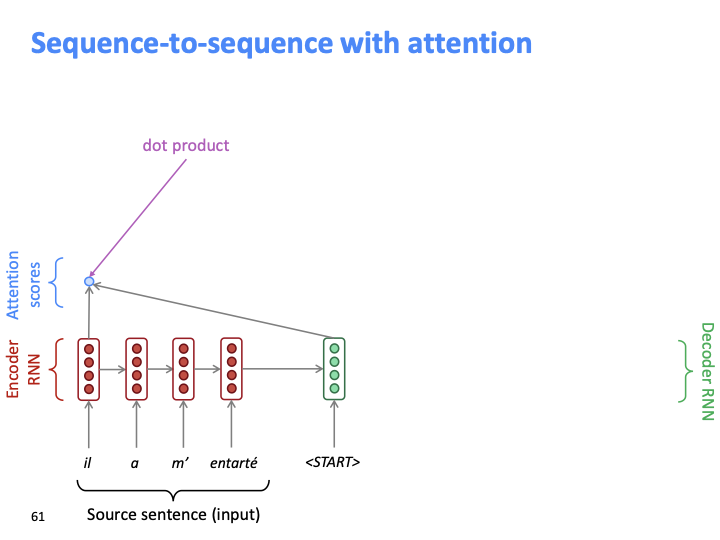 Decoeder의 첫번째 hidden state와 encoder의 첫번째 hidden state를 dot product하는 것으로 attention score를 얻습니다.
Decoeder의 첫번째 hidden state와 encoder의 첫번째 hidden state를 dot product하는 것으로 attention score를 얻습니다.
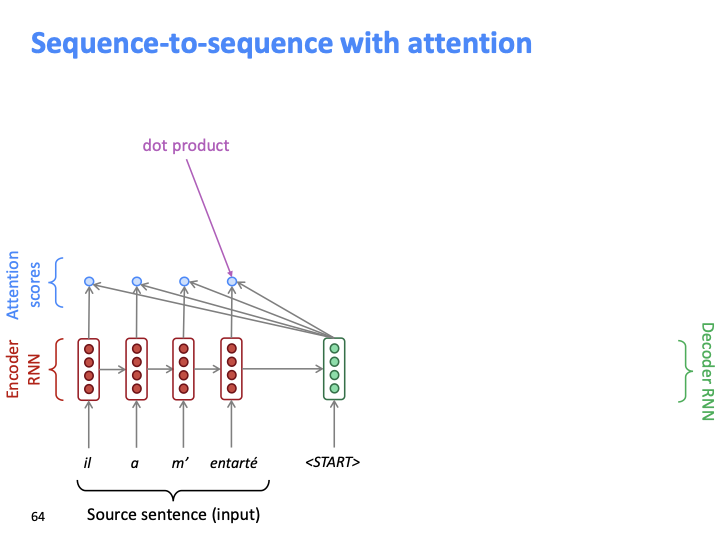 각 source word(hidden state)마다 하나의 attention score를 얻습니다.
각 source word(hidden state)마다 하나의 attention score를 얻습니다.
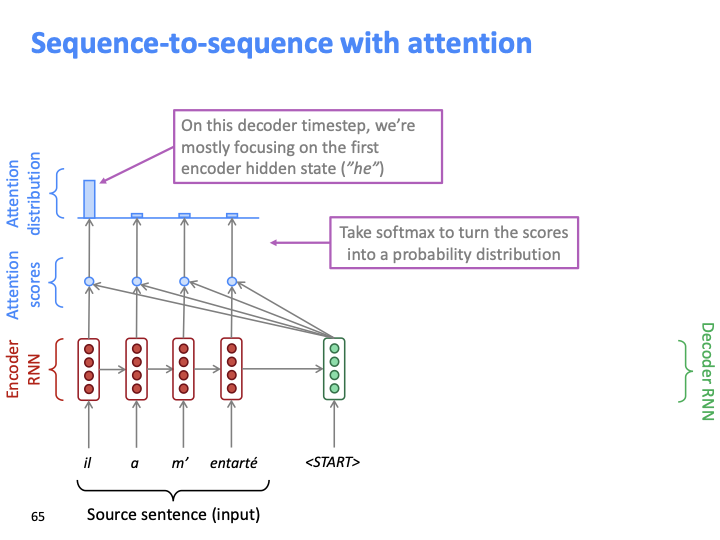 Decoder의 첫번째 hidden state에 대해 source word들의 attention score가 모두 게산되면, 이를 softmax에 통과시켜 probability distribution을 얻습니다. 그 분포를 bar chart로 나타낸 것이 위의 diagram입니다.
Decoder의 첫번째 hidden state에 대해 source word들의 attention score가 모두 게산되면, 이를 softmax에 통과시켜 probability distribution을 얻습니다. 그 분포를 bar chart로 나타낸 것이 위의 diagram입니다.
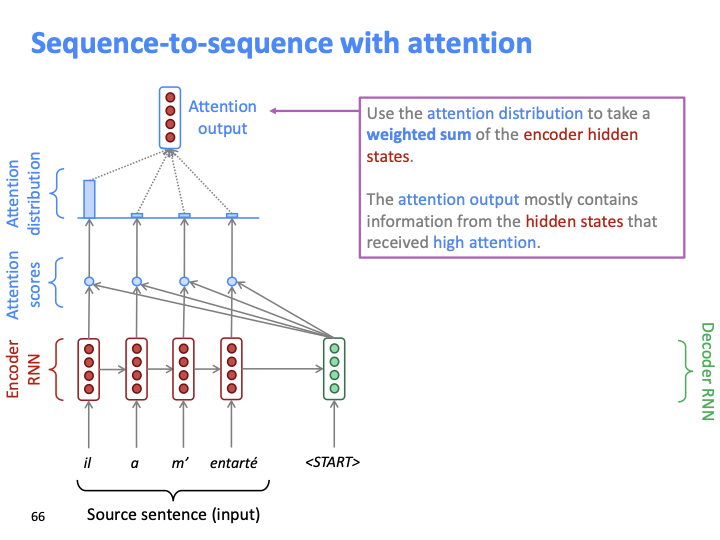 Encoder hidden state의 weighted sum을 attention distribution으로 사용합니다. 이 분포로 attention output을 만듭니다. 위의 attention output은 가장 높은 attention score를 얻은 hidden state의 대부분의 정보를 포함합니다.
Encoder hidden state의 weighted sum을 attention distribution으로 사용합니다. 이 분포로 attention output을 만듭니다. 위의 attention output은 가장 높은 attention score를 얻은 hidden state의 대부분의 정보를 포함합니다.
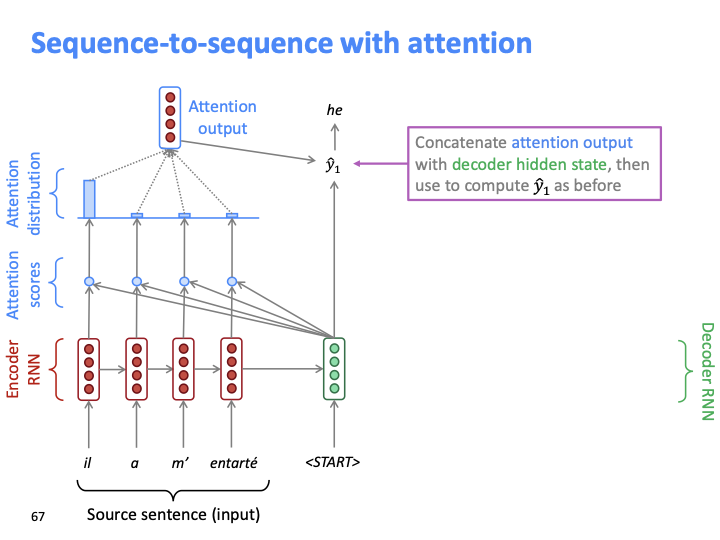 attention output과 decoder hidden state을 concatenate하여 다음 단어(y1)을 예측합니다. 이전 seq-to-seq에서는 decoder hidden state를 만으로 다음단어를 예측했던것에 비해, pair인 (attention output, decoder hidden state)를 사용하여 예측합니다.
attention output과 decoder hidden state을 concatenate하여 다음 단어(y1)을 예측합니다. 이전 seq-to-seq에서는 decoder hidden state를 만으로 다음단어를 예측했던것에 비해, pair인 (attention output, decoder hidden state)를 사용하여 예측합니다.
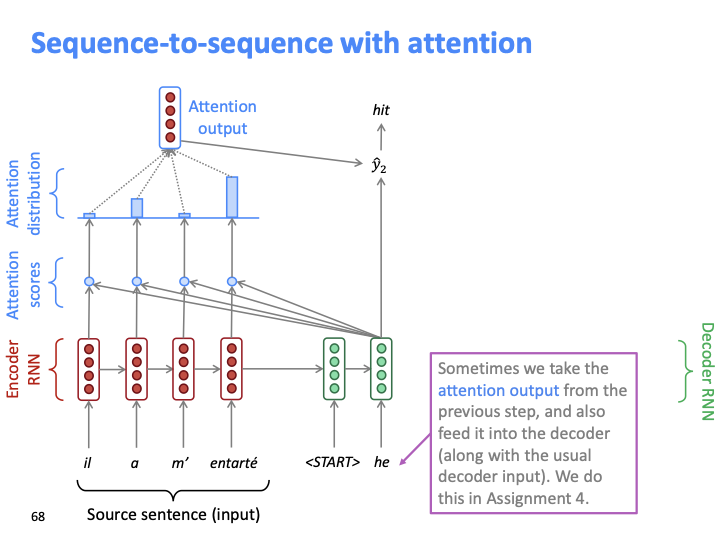 그 다음 단계도 같은 과정을 반복합니다. 이전의 슬라이드들 에서 SMT의 alignment를 배운 이유가 여기서 나옵니다!. attention output을 일종의 alignment를 볼수있고, 어떠한 의미에선 soft alignment로 볼 수 있습니다. SMT의 alignment를 보면 hard binary 값이었습니다. (align 되거나 안되거나) 반면 attention애는 much flexible of alignment(target 단어는 각 source target에 대한 확률분포를 갖습니다) 가 적용된 것을 볼 수 있습니다.
그리고 이전 step의 attention output은 다음 step에서 유용할 수 있기 때문에 decoder로 다시 feed됩니다.
그 다음 단계도 같은 과정을 반복합니다. 이전의 슬라이드들 에서 SMT의 alignment를 배운 이유가 여기서 나옵니다!. attention output을 일종의 alignment를 볼수있고, 어떠한 의미에선 soft alignment로 볼 수 있습니다. SMT의 alignment를 보면 hard binary 값이었습니다. (align 되거나 안되거나) 반면 attention애는 much flexible of alignment(target 단어는 각 source target에 대한 확률분포를 갖습니다) 가 적용된 것을 볼 수 있습니다.
그리고 이전 step의 attention output은 다음 step에서 유용할 수 있기 때문에 decoder로 다시 feed됩니다.
 위의 attention에 대한 diagram에서 설명한 것과 동일한 equation입니다. 여기서 attention output을 의미하는 α는 encoder의 hidden state와 동일한 vector size를 갖습니다.
위의 attention에 대한 diagram에서 설명한 것과 동일한 equation입니다. 여기서 attention output을 의미하는 α는 encoder의 hidden state와 동일한 vector size를 갖습니다.
 Attention이 좋은 이유는 위와 같습니다.
Attention이 좋은 이유는 위와 같습니다.
- SMT에서 처럼 단순히 binary가 아닌 실제 alignment의 개념을 적용한 attention은 특정 부분에 focus하게 해줍니다.
- Attention의 decoder에선는 encoder와 source sentence를 directly look하기 때문에 bottle neck 문제점을 해결할 수 있습니다.
- 각 step에서의 encoder와 decoder사이의 direct connection은 short cut으로써 동작하기 때문에 vanishing problem을 해결해줍니다.
- SMT에서는 의도적으로 alignment에 대해 따로 학습해야 했지만, Attention에서는 alignment를 not explicitly하게 학습합니다. 어떤 의미론 unsupervised way로 학습된다고 볼수 있습니다. 그리고 SMT보다 더 flexibility가 있기 때문에 앞서 말한것 처럼 soft version of alignment입니다.
 MT뿐만 아니라 많은 다른 task에서도 attention은 사용 가능합니다. value에 모든 information이 있고, query는 value에 어떻게 pay attention할지 정할 vector를 의미한다고 볼수 있습니다. 이를 query attend to value라고도 표현합니다.
MT뿐만 아니라 많은 다른 task에서도 attention은 사용 가능합니다. value에 모든 information이 있고, query는 value에 어떻게 pay attention할지 정할 vector를 의미한다고 볼수 있습니다. 이를 query attend to value라고도 표현합니다.
 각 step의 encoder source sentence에 대한 weighted sum은 selective summary라고 볼 수 있습니다. attention distribution에서 각 value(source sentence)에 얼마나 attend해야 하는지 choice를 담은 summary이기 때문입니다. 이는 LSTM과 어떤 부분에서 유사합니다. LSTM gate들은 각기 다른 element에서 얼마나 정보를 유지(가져올지)할지 정합니다.
각 step의 encoder source sentence에 대한 weighted sum은 selective summary라고 볼 수 있습니다. attention distribution에서 각 value(source sentence)에 얼마나 attend해야 하는지 choice를 담은 summary이기 때문입니다. 이는 LSTM과 어떤 부분에서 유사합니다. LSTM gate들은 각기 다른 element에서 얼마나 정보를 유지(가져올지)할지 정합니다.
Attention은 fixed-size of representation of arbitrary set of representation을 얻는 방법입니다. 앞선 슬라이드에서 query attends to the value라고 했습니다. arbitrary set of representation은 value에 해당한고 볼 수 있습니다. fixed size of representation은 single vector ( = attention output) of using query라고 볼수 있습니다.
 위에서 배운 attention에서 attention score를 얻는 방법을 달리한 몇가지 변형이 있습니다. (다음 slide!)
위에서 배운 attention에서 attention score를 얻는 방법을 달리한 몇가지 변형이 있습니다. (다음 slide!)

- Basic dot-product attention은 위에서 저희가 배운 attention입니다. size of query vector(=attention output)과 value vector(=encoder hidden state vector)의 size가 같아야합니다.
- Multiplicative attention : 이것의 idea는 bilinear function을 query와 value에 적용하는 것 입니다. 여기서 W는 learnable parameter로 이루어져 있습니다.
- Additive attention: 여기서 d3는 attention output의 차원을 의미하고, length of V 그리고 height of W1,W2 에 대한 hyper parameter 입니다.
 다음은 오늘 lecture의 요약 입니다!.
다음은 오늘 lecture의 요약 입니다!.