CS224N|Lecture 6 Recurrent Neural Networks and Language Models
26 Oct 2021
language modeling과 RNN에 대한 내용입니다. LM task가 어떤 task이고, LM task의 중요성에 대한 내용이 있었고, fixed window NN의 문제점과 그에 대한 해결책인 RNN, 또 RNN의 문제점에 관한 내용이었습니다.

language modeling은 다음에 올 단어를 예측하는 task 입니다. Formal한 정의는 $x^{(1)}, x^{(2)},…,x^{(t)}$가 주어졌을때, $x^{t+1}$를 구하는 task이고, 위의 P와 같은 확률 분포로써 표현할 수 있습니다. (LM 모델의 가장 기초적인 형태로 마르코프 체인기반으로 이루어져 있습니다.) 이때 predefined list of words인 V가 있고, 여기에 모든 단어가 속합니다.

LM task를 piece of text에 확률을 부여하는 시스템이라고 생각해도 됩니다.
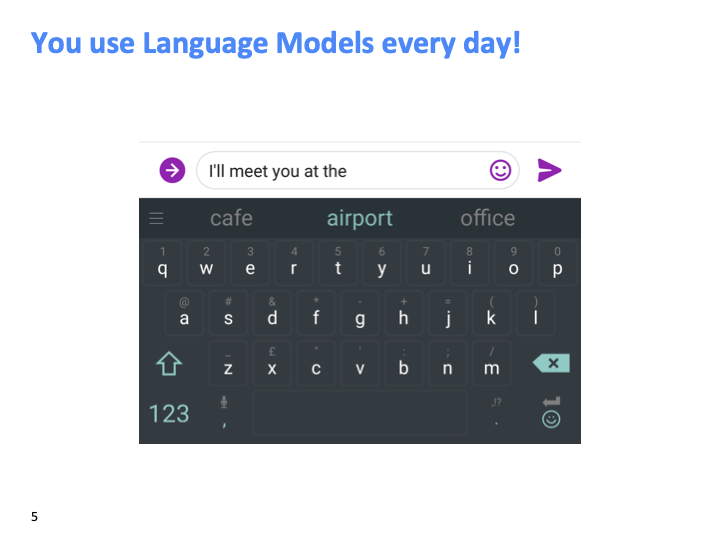
단어를 타입핑할때, 다음에 올 단어를 예측하는 것 또한 LM입니다. 또한 구글에서 검색할때, 다음에 올 단어를 예측하여 query를 완성시킨 후보의 리스트를 보여줍니다.

n-gram은 chunk of n consecutive words를 의미합니다. n-gram language model의 core idea로, 각 다른 n-gram이 얼마나 자주 나오는지에 대한 통계를 모아 다음 단어를 예측합니다.

먼저 $x^{t+1}$는 선행하는 n-1개의 단어들에 만 의존 한다는 마르코프 가정을 세웁니다. 그 가정을 위에서와 같이 조건부 확률로 표현할 수 있습니다. 그렇다면 분자 분모에 해당하는 n-gram, (n-1)gram 확률은 어떻게 얻을까? 각 partial n-gram의 수를 단순히 세어 확률을 근사합니다.

4-gram 의 Language Model에서 다음 단어를 예측할때, 이전 3개의 단어에 대해서만 의존하여 에측합니다.
위 슬라이드에서 제시된 예시들을 봅시다. 빈칸(books, exams 위치) 앞에 있는 단어들의 순서와 context들이 해당 단어가 빈칸에 들어갈 것이라는 것을 알려줍니다. 그렇다면, 주어진 문장의 앞부분의 proctor가 들어있는 context를 제거해야할까요?
여기서 알 수 있는 것은 3-gram을 제외한 단어를 버리는 우리의 가정이 틀렸다는 것 입니다.

n - gram의 sparsity problem에 관한 슬라이드 입니다. 첫번째 문제로, 조건부 확률의 분자가 거의 0에 가깝거나 0일 경우, 다시말하면 해당 문장이 training data에 없다면 w의 확률은 0일 것이다. Parital solution으로 V의 모든 w에 대해 small $\delta$ count를 더하여 최소한의 확률을 갖게 합니다. 이 방법을 smoothing이라고 합니다.
두번째 문제로, 분모가 0인 경우, 해당 문장이 training data에 없다면 확률을 계산할 수 없습니다. Partial solution으로 “student opened their”에서 “open their”에 대해서만 조건을 거는 것 입니다. 이 해결 방법을 backoff라고 합니다. 즉, 4-gram LM에 대해 데이터가 없을때 3-gram LM으로 back-off 합니다.
n - gram의 n이 커지면 sparsity problem이 더 나빠지고, 5보다 큰 값을 갖을 수 없습니다.

n-gram LM을 사용하기 위해서는 corpus로부터의 모든 n-gram을 저장해야 합니다. n 또는 corpus가 증가하면 model size가 증가합니다.

n-gram LM 모델을 이용해 text를 generate하는 방법입니다.
today와 the라는 2개의 단어가 주어져있다고 가정해봅시다.
- condition on these two words.
- ask LM what’s likely to come next
- given probability distribution of words, you can sample from it. (select one)
→ 그 다음 1~3번에 대해 loop을 돈다.

놀랍게도 문법적이지만, incoherent(앞뒤가 맞지 않는다)하다. 앞선 3개의 단어보다 더 많은 단어를 봐야하는데, n을 늘리면 sparisty problem과 storage problem을 이르킨다.
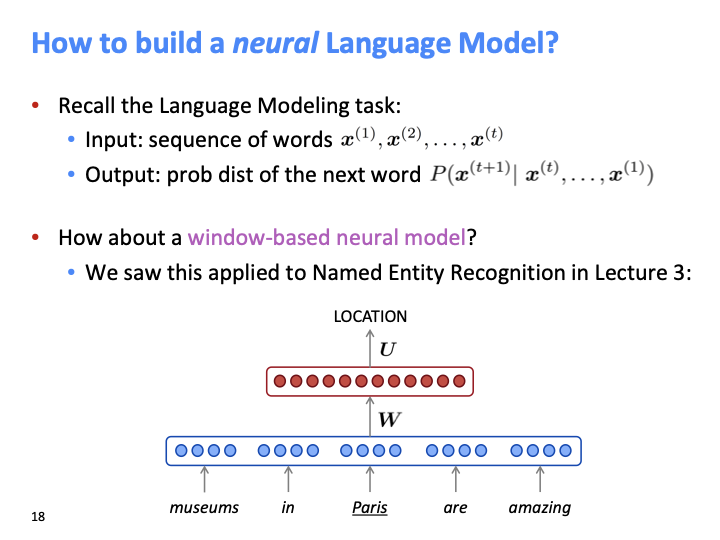
lecture3에서 window-based neural model을 NER task에 적용을 하였습니다. 이 방법을 LM에 사용하면 어떻게 될까?
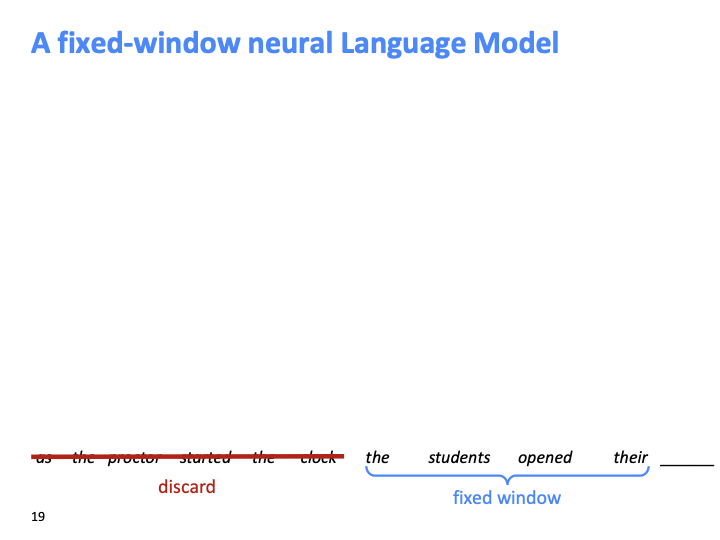
fixed - window 라는 것 자체가 context를 discard해야 한다.
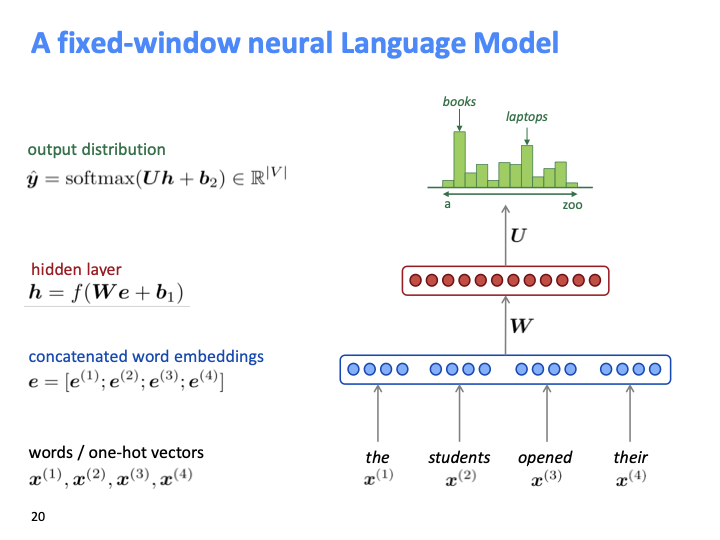
NER과 비슷하게 one hot vector로 만들어서, embedding lookup matrix를 통해 word embedding을 찾습니다. 그리고 NN에 넣어 softmax를 통해 계사하는 방법입니다.
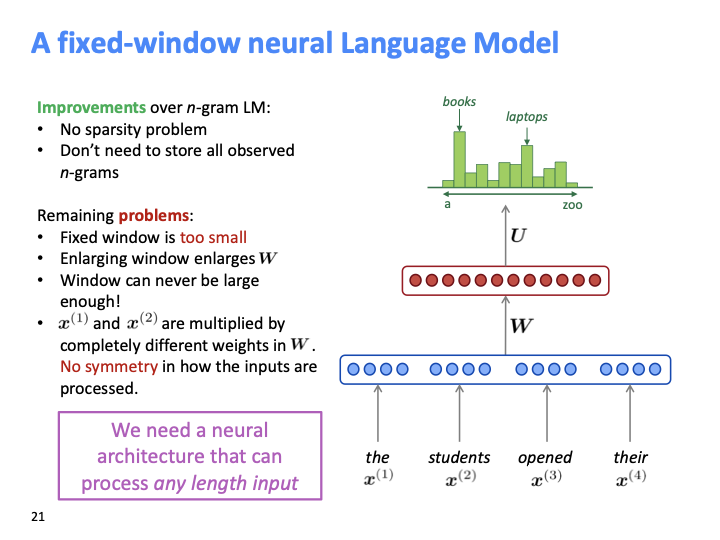
sparsity problem과 stroage problem은 해결되었지만, Fixed window가 너무 작다. window size를 키우면 weight matrix가 커지는 문제점이 발생한다. 또한 입력 값들이 비 대칭적으로 W의 다른 weight와 곱해진다.
모든 길이의 입력에 대해서 처리할 수 있는 neural network architecture가 필요하다.
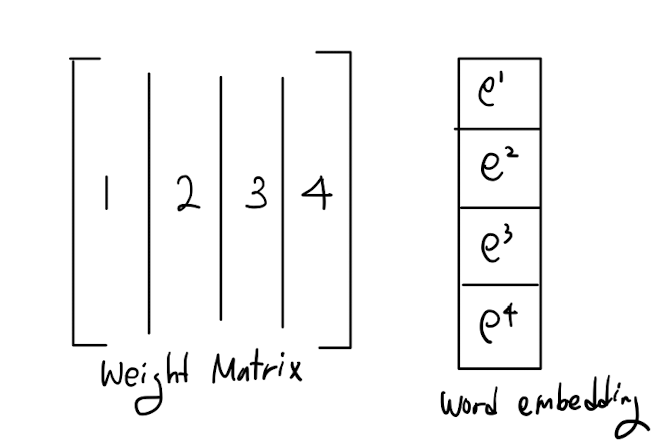
또한 4개의 column이 있는 weight matrix가 있고, 각 word embedding당 하나의 row에 대응되는 4개의 row word vector 있다고 해보자. weight matrix의 각 column은 한개의 word embedding만 곱해진다. 즉 weight matrix들이 learn될때 section들이 공유되지 않는다.
입력으로 들어오는 word embedding에 대해 많은 공통성이 있기 대문에 share되어야 한다. 즉, 각 단어에 대해 seperate learning하는 방식은 비효율적이다.
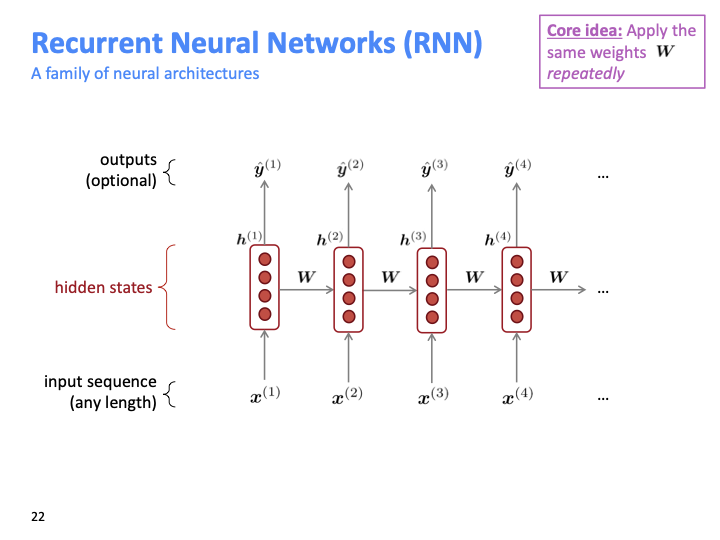
같은 weight를 모든 타임스텝에 대하여 적용하는 것이고, 이것이 모든 길이의 input sequence로 입력을 넣을 수 있게 한다. RNN의 가 hidden state는 timestep에 따라 계산되는 several version of same thing이라고 볼 수 도 있다.
각 hidden state가 previou hidden state과 input에 대해 계산된다. input의 개수와 hidden state가 같다.
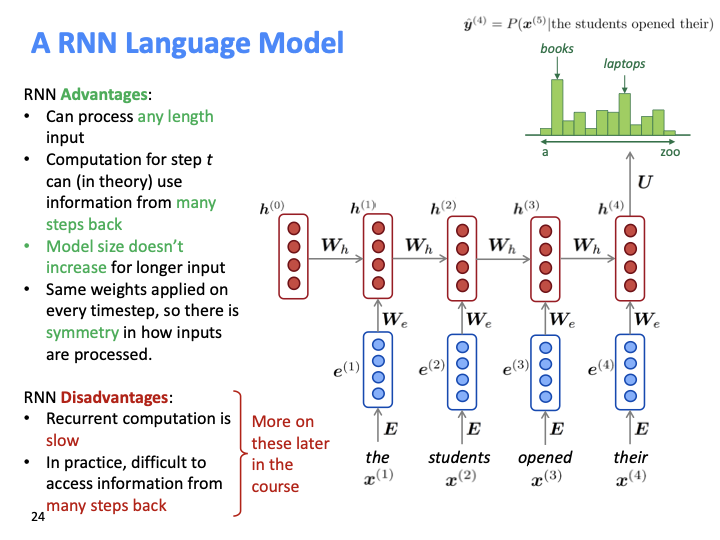
fixed size window일때는 각 단어에 differecnt weight를 곱해서 비효율적이었다. RNN에서는 같은 weight를 매번 곱하기 때문에 symmetry하다.
학생 질문 중에 RNN 작동에 대한 질문이 있었다. 다른 context에서의 다른 단어들에 대해 학습을 하는데 왜 매번 같은 wegiht으로 transformation을 적용하는가?
각 단어에 대해서가 아닌 general represenation of language를 학습하는것이다. 그리고 모든 hidden state들은 vector이고, single number가 아니다. vector이기 때문에 많은 정보를 포함할 수 있는 capacity를 갖고 있다. 긴 input에 의해 큰 모델이 필요하지 않다.
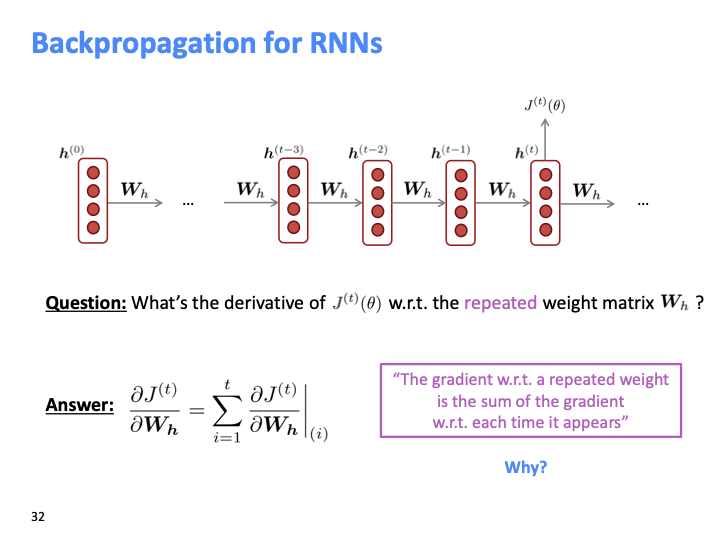
RNN의 backpropagation의 결과가 위와 같은 이유에 대해 생각해보자.
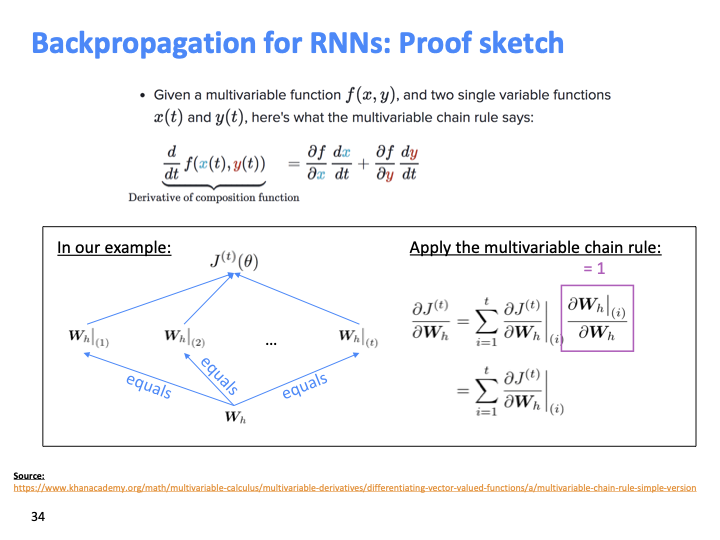
multivariable chain rule에 의해 위와 같이 식이 전개 되고, 모두 같은 weight이기 때문에 1이다.
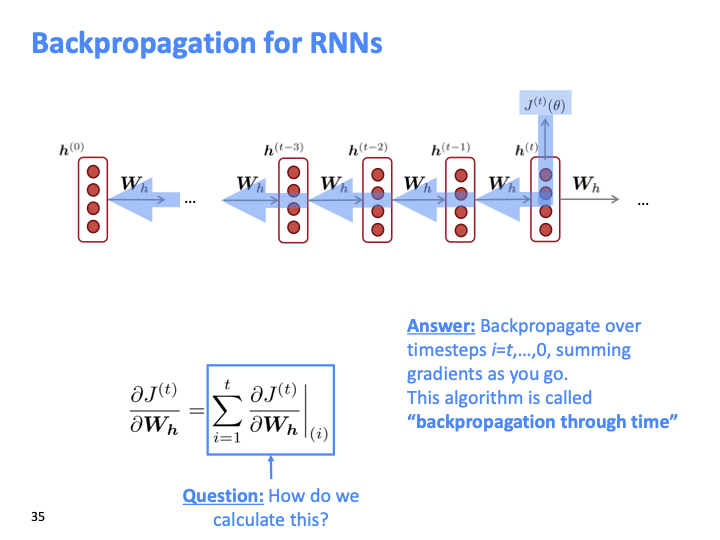
RNN을 backpropagate하면 i=t,…,0 순으로 gradient를 누적하여 더한다. 그래서 이 알고리즘을 backpropagation through time이라고 부른다.
Cf) SGD는 true gradient의 approximation이라고 볼 수 있다. 예를들어 하나의 batch에 대한 gradient는 전체 corpus에 대한 true gradient의 근사이다. 데이터를 shuffle하여 SGD를 사용하고, 많은 step에 대해 이를 수행하면 충분히 좋은 근사를 얻을 수 있다.
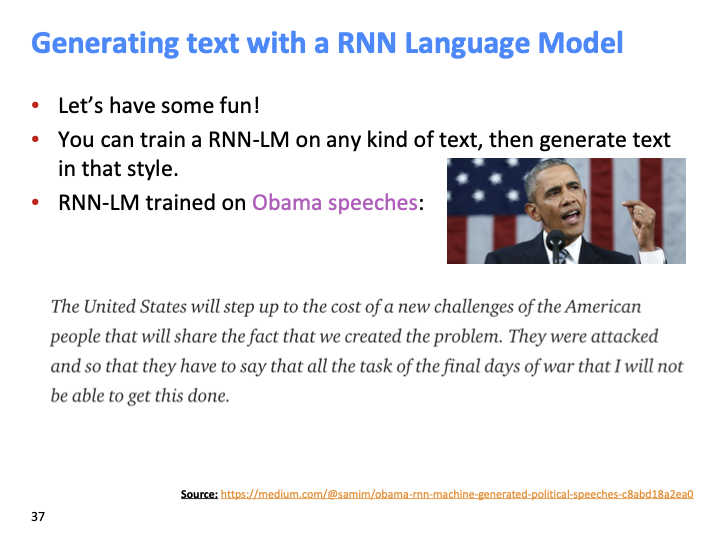
RNN을 이용하여 text를 generate 할 수 있다. n-gram보다 훨씬 낫다.

위 예시를 보면 title에 있는 정보를 기억하여 recipe 형태를 출력한 것을 볼 수 있다.

$1/T$ 승을 취한 이유는 normalize하기 위한 것이다. $1/T$가 없으면 corpus가 커질 수록 perplexity값이 계속 작아 질 수 있다.
$J(\theta)$ : object function으로, Minimize $J(\theta)$ = optimize perplexity

Language Modeling은 benchmark task로, 다른 많은 task들의 subcomponent이다. 특히, generating text or estimationg the probablity of text 의 task에 해당한다.
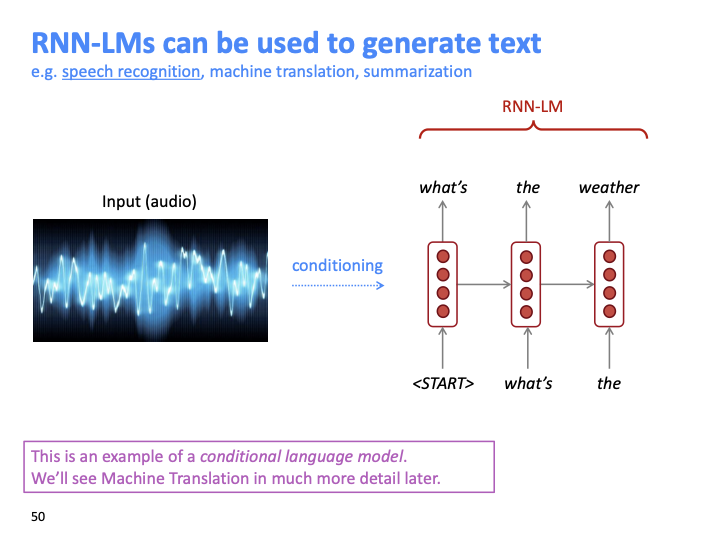
RNN은 pos tagging task, classification, question answering과 같은 task에서의 encoder module로 사용 될 수 있다.
또한 RNN-LM은 text를 generate할 때도 쓰일 수 있다. 위 예시는 conditional language model이다.

vanilla RNN은 보통 말하는 기본 RNN을 의미한다.