CS224N|Lecture 5 Linguistic Structure Dependency Parsing
16 Aug 2021
Syntactic Strucutre, Dependency Grammer, Transition-based depedency parsing, Neural dependency parsing에 관한 내용이었습니다. 저번학기에 Compiler에 대해 수강했는데 Parser를 만들때 사용하는 Context-Free-Grammar나, Chomsky Hierarchy, LR parser를 만들때 사용하는 shift-reduce parsing 등 에 관련된 내용이 나와서 반가웠습니다.

언어학자가 문장의 구조에 대해 분류하는 2가지 구조가 있습니다. 첫번째 위의 예시와 같은 Phrase structure이고, 두번째로 nlp에서 보통 사용하는 Dependency structure 입니다.
Phrase structure의 기본적인 idea는 다음과 같습니다. senetence들은 기본적인 단어들이 점진적으로 중첩되어 더 큰 단위로 만들어진다는 것 입니다. 예를들어 위와 같이 words로 시작하여 phrase를 만들고, phrase을 합쳐서 bigger phrase로 만드는 것입니다.

Phrase structure는 단어들을 nested된 구성요소에 organize합니다. phrase structure에 해당하는 CFG로 예를 들어 설명해 보겠습니다. NP → Det N 이라는 rule이 있다고 해봅시다. 그러면 nested된 구조로써 NP→ Det (Adj)N과 같은 형식으로 rule을 더 만들 수 있습니다.
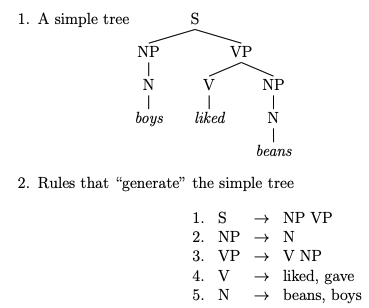
Phrase struture에 대한 tree와 그에 해당하는 CFG입니다.

그리고 nested되는 형태로 위와같이 새로운 rule를 만들 수 있습니다.
정리하면 이런 언어의 구조를 describe하기 위해 CFG를 사용할 수 있고, 이런 일들은 언어학자가 하는 일입니다. 당연하게 다른 언어는 다른 구조를 갖습니다. 그리고 이것이 언어학에 대해 접근할때 dominant한 접근법입니다. 언어학 수업을 가면 이런 phrase structrue grammar tree를 만든다고 합니다. 지금부터 설명할 depedency structure는 컴퓨터 언어학(computational lingustics)에서 dominant한 접근법입니다.

Dependency structure의 기본적인 idea는 phrasal category의 set을 갖기보다는 직접적으로 재귀적인 구조로 문장의 구조를 나타내는 것 입니다. 즉, 다른 단어들에 어떤 dependence가 있는지를 보여주는 구조 입니다.

사람들은 복잡한 의미를 전달하기 위해 단어들을 합쳐 더 큰 단위로 구성함으로써 복잡한 생각을 의사소통 합니다. 그래서 언어를 올바르게 해석하기 위해서 언어 모델은 문장 구조(sentence structure)를 이해해야할 필요가 있습니다.
지금부터 문장 구조(sentence structure)를 올바르게 이해하지 못할때 생기는 잘못된 중의적 해석에 대한 예시를 보겠습니다.

첫번째 의미는 cop(경찰)이 남자를 칼로 찔러서 죽였다는 것이고, 두번째는 칼을 가진 남자를 경찰이 죽였다는 뜻입니다. 어떤 단어가 어떤 단어를 modify할꺼지에 따라 해석이 달라집니다. 즉 위의 예시에서도 문장의 구조가 중요한것을 볼 수 있습니다.

또 다른 예시는 위와 같습니다. 영어가 가장 중의성이 많이 나타나는 것은 prepositional phrase attachment라고 합니다.

위의 문장에는 4개의 PP(prepositional phrase)가 있고, 각 PP들이 어떤 것을 modify하는지에 따라 조합의 수가 많아 집니다. triangulation probabilstic graphical model에서 배우는 Caltaln number만큼 조합의 수가 나온다고 합니다. 즉 factorial의 만큼 ambiguity에 대한 중의적 표현이 생깁니다.
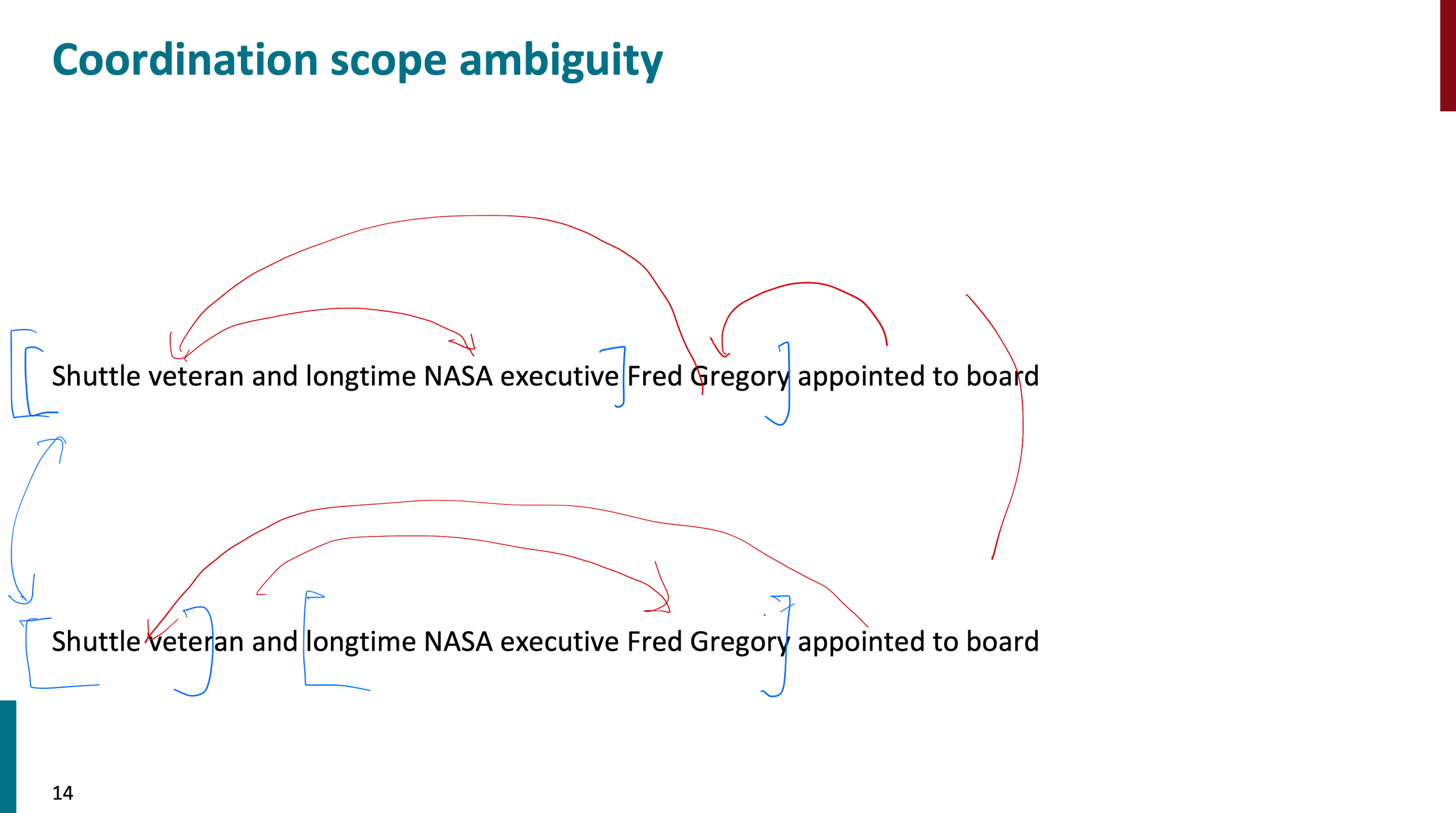
coordination scope ambiguity로써 위의 문장에 대해 두가지 구조로 나타낼 수 있습니다. 이 예시말고도 수업에서 Adjectival/Adverbial Modifier Ambiugity 이나 Verb Phrase attachment ambiguity에 대해서도 설명했습니다. 이런 예시들로 올바르게 해석하기 위해선 문장의 구조를 이해하는 것이 중요하다는 것을 강조했습니다.
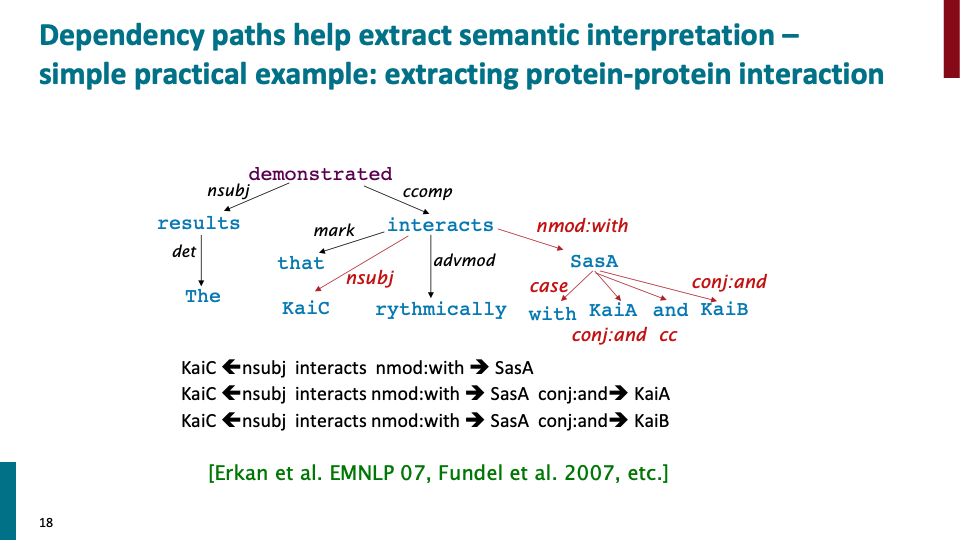
우리는 이런 종류의 패턴과 dependency에 대해 예를 들어 biomdeical text에 나오는 protein-protein interaction과 같은 것 또한 분석할 수 있습니다.
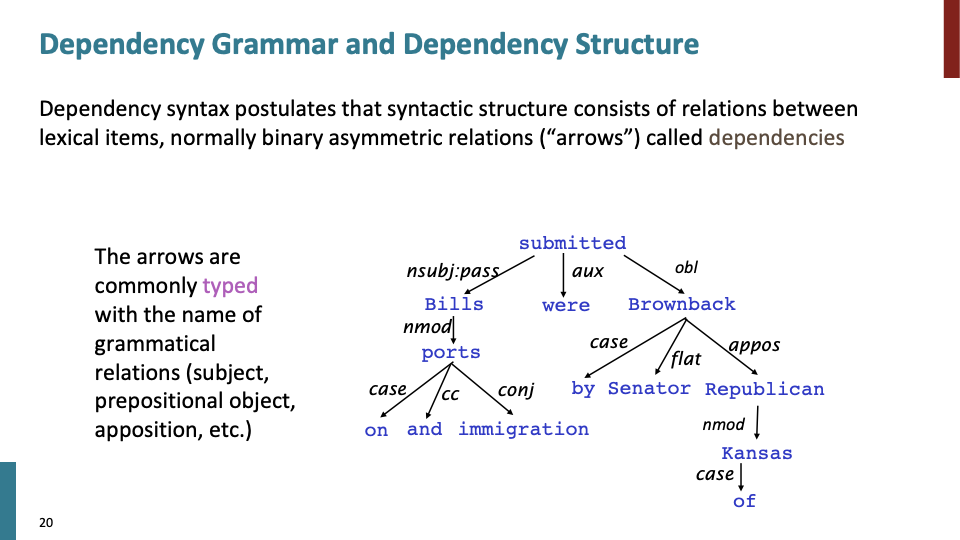
수업에서는 nsubj과 같은 문법적 관계를 나타내는 label을 사용하지 않고 arrow만 사용하여 설명했습니다. arrow를 보고 예를들어 preposistional pharse(전치사 구)가 어떤 term을 modifying하고 있고, 올바른 해석인지에 대해 알 수 있습니다.
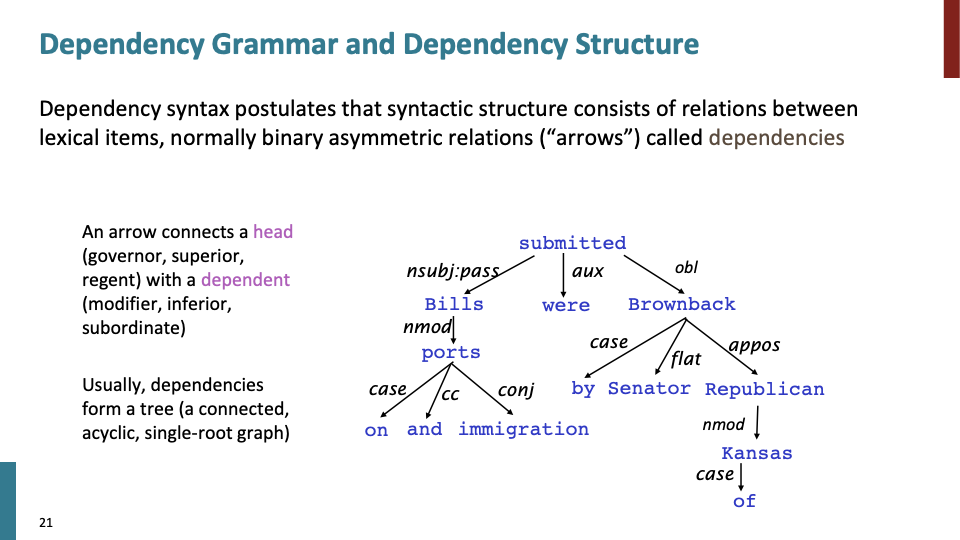
위와 같은 dependency grammar(tree)가 있을때, tree의 root를 head of dependency라 칭합니다. 그리고 보통 dependency는 tree의 형태를 형성합니다.

인류의 역사를 보면, 인간의 언어의 구조를 이해하기 위한 대부분의 시도들은 본질적으로 dependency grammar 였습니다. 1953년 촘스키가 Context-Free-Grammar를 만들었고, 촘스키 계층을 통해 언어의 complexity를 정리하였습니다. 그리고 NLP 초기의 parser 로써 dependency parser를 만들었고, 언어에서 dependency grammar를 publish 하였습니다.
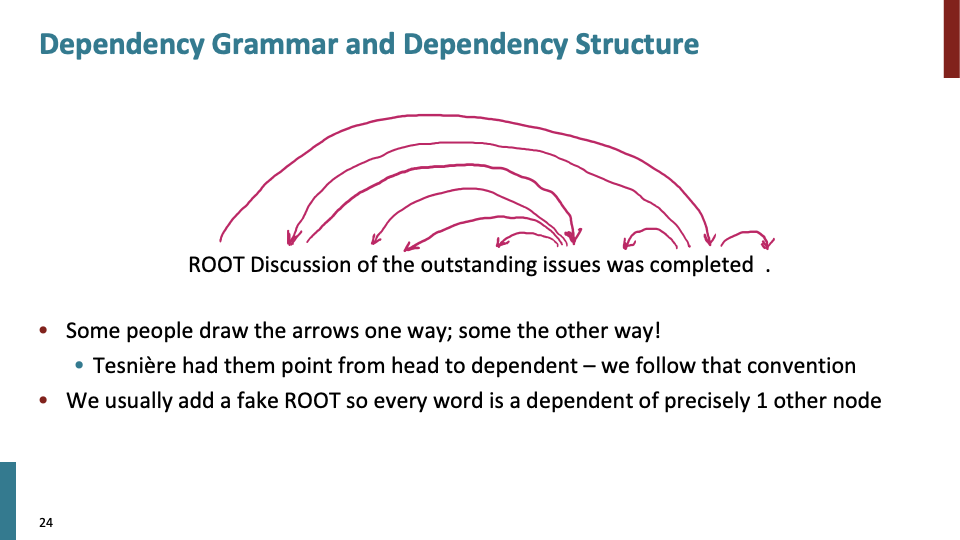
head→dependent 로의 arrow 방향이 convention이고, fake root를 만들어서, 모든 단어가 다른 노드의 dependent가 되게 만들어 있습니다.

dependency parser를 만들거나 다른 인간 언어의 구조를 만들때, 지난 25년동안 centeral tool로써 사용된 아이디어가 tree bank입니다. tree bank는 문장에 문법적 구조를 붙이는 방법 입니다. sentence를 support하는 tree bank는 sentence을 더 useful하게 만들었습니다. (이후 슬라이드에서 설명)
universal dependency tree bank의 목표는 어떤 언어에서나 사용 가능한 parallel system of dependency description을 만드는 것 이었습니다.

60s~80s때 parser를 만든 사람들은 grammar rule에 대해 그들만의 notation을 만들었고, 공유된 resource가 없었습니다. 그래서 Tree bank의 reusability때문에 이것을 이용하게 되었습니다. 또한 grammar가 주어져 있고, ambiguous한 문장에 대해 올바른 구조를 찾을때 treebank가 없다면 많은 parser를 확인하여 찾아야 했습니다.
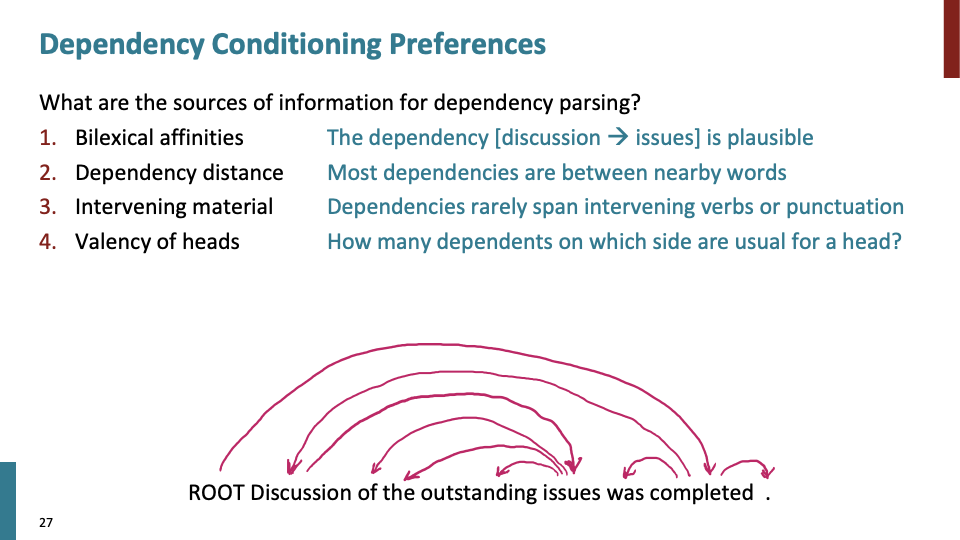
dependency parsing에 있는 정보 입니다. 2. depedency distance는 단어들이 얼마나 떨어져 있는지에 대한 것이고, 대부분 dependency가 있는 것들은 가까이에 위치합니다. 4. Valenncy of heads에서 how many dependent가 갖는 의미는 예를들어 설명 하겠습니다. 위 문장에 was completed를 보면, subject가 하나 있어야 하고, object은 없어야 합니다.

각 단어가 어떤 다른 단어 혹은 루트의 dependent가 될것이고, dependencies들이 tree를 형성할 것입니다. cycle을 만들어진다면 tree가 아니기 때문에 잘못 만들어 진것입니다.
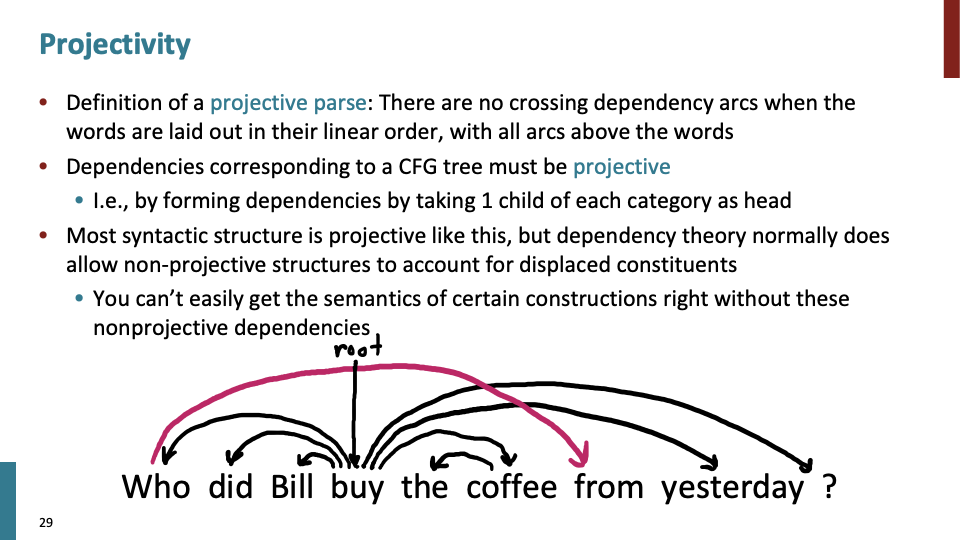
대부분의 경우 arrow들은 교차(cross)되지 않지만, 되는 경우도 있습니다. 교차되지 않는 경우를 projective라하고 교차되는 경우를 non-projective하다고 합니다.

위의 파싱 방법중 4번째 방법은 google이 매 page를 parsing할때, 사용하는 방법 입니다. practical deployments of parsing에 큰 영향을 끼쳤습니다.

이전 슬라이드에서 설명한 4번째 방법으로, Nivre에 의해 parsing 방법이 popularize되었습니다. Shift-reduce parsing 방법에 영감을 받아 만든 방법으로, reduce할때 dependency를 build 합니다.
shift - reduce parser에 대한 자세한 내용은 compiler의 LR parser에서 나옵니다.

Formal description of Transistion based shift-reduce parser 입니다. reduce는 left-arc,right-arc과 동일한 action입니다.
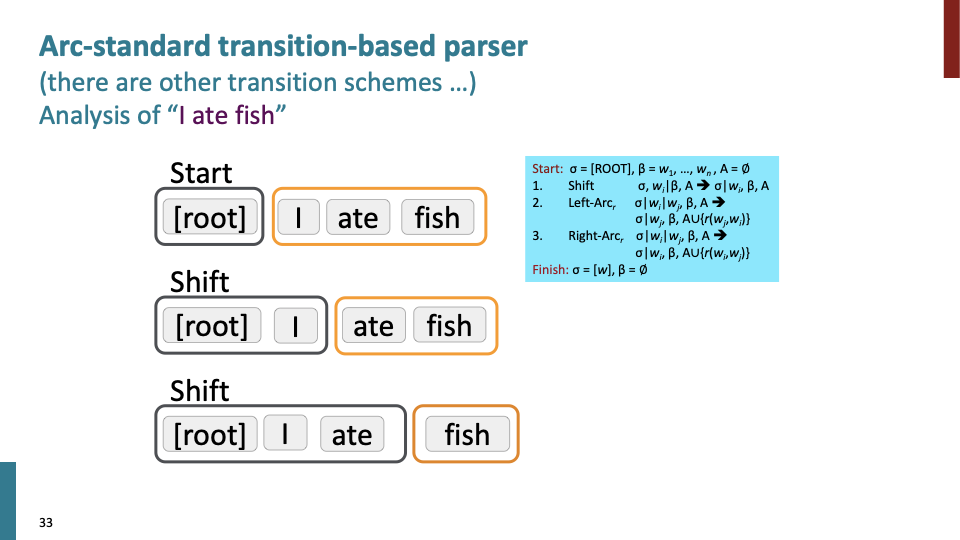
Stack(검은색 박스)에는 우리가 build해야 하는 것들이 들어있고, Buffer(노란색 박스)에는 source 문장이 들어가 있습니다. action은 두가지로 shift(스택에 shift)하거나 reduce(build dependency)가 있습니다.
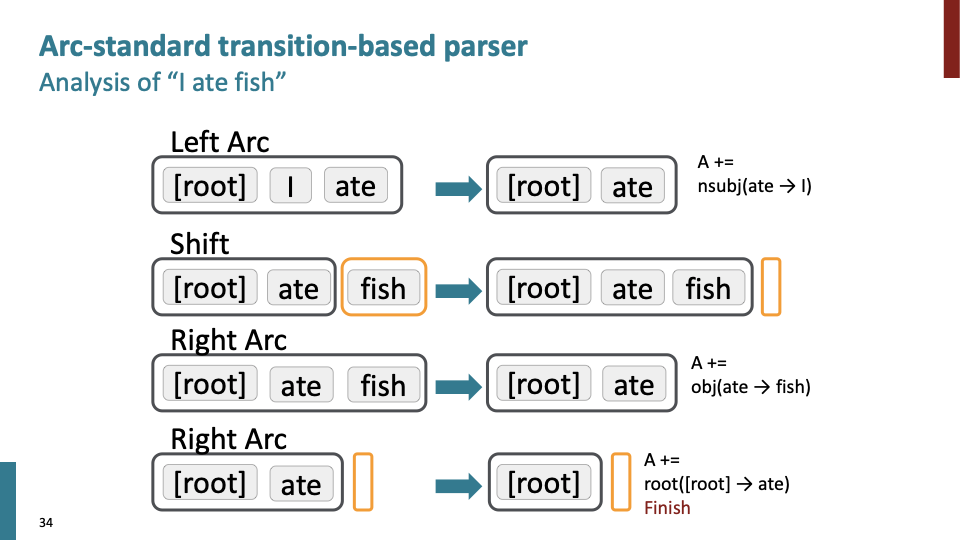
shift-reduce에 따른 여러 경우의 수가 있고, 모든 경우의 수에 대해 해봤을때, 운좋게 finish가 될 수 있고, 이것은 비효율적 입니다. 60년대 사람들은 dynamic programming을 통해 가능한 경우의 수를 효율적으로 탐색했긴 하지만, Nirve은 다른 방식으로 했습니다.

Parser에서 어떤 특정한 위치에 주어졌을때, Machine classifier를 통해 다음에 어떤 것을 (shift or left arc or right arc)해야할지 구했습니다. 이 방법은 높은 정확도로 올바른 액션을 예측했습니다.
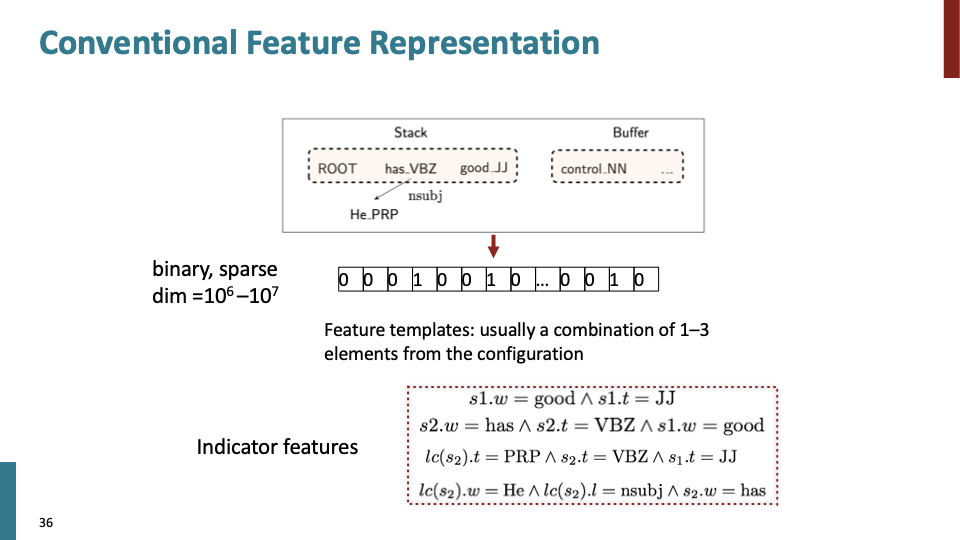
conventionnal한 방법으로 매우 복잡한 binary indicatot feature를 추출하여, 이를 SVM(서포트 벡터 머신)에 넣어 parser를 만들었고, 꽤 잘 작동했습니다.
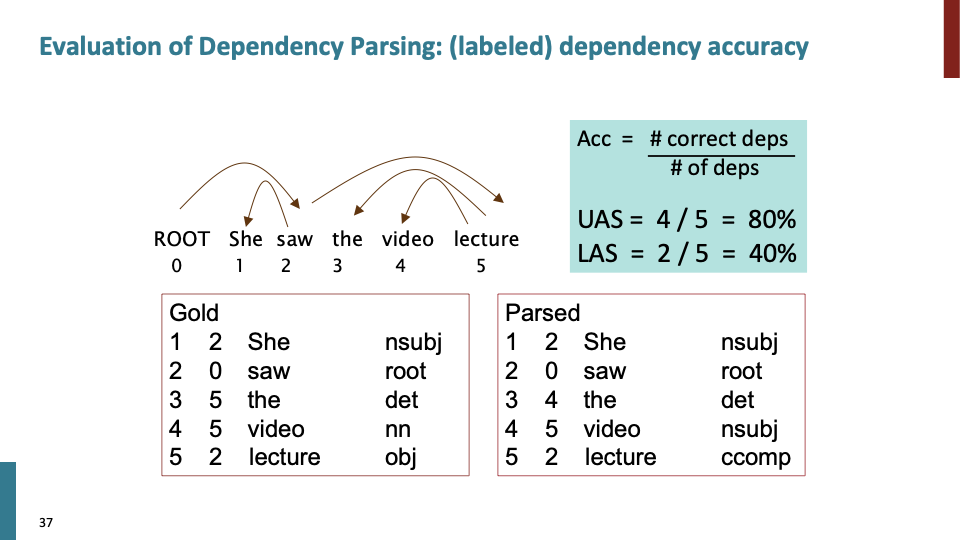
dependency parser를 evaluate하는 방법입니다. parser를 만들고 나서 gold label과 parsed label이 얼마나 일치하는지 개수를 세어 정확도를 평가 했습니다. UAS (=unlabeled attachment score)은 label을 무시하고 dependent의 개수를 이용한 지표이고, LAS(=labeled attachment score)은 label을 이용한 지표입니다.

neural dependency parser가 필요한 이유는 앞서 만든 feature들이 sparse, incomplete하여 이것들을 계산하는 데에는 expensive computation을 필요로 했기 때문입니다. 저 규칙들을 없애고, Neural net을 직접 통해 stack과 buffer를 배치했습니다. 신경망을 통한 방법은 원래의 dendency parsre가 겪은 문제점들을 해결하고, 더 빠른 dendency parser를 만들 수 있게 합니다. 즉, 더 dense, compact feature를 학습할 수 있습니다.
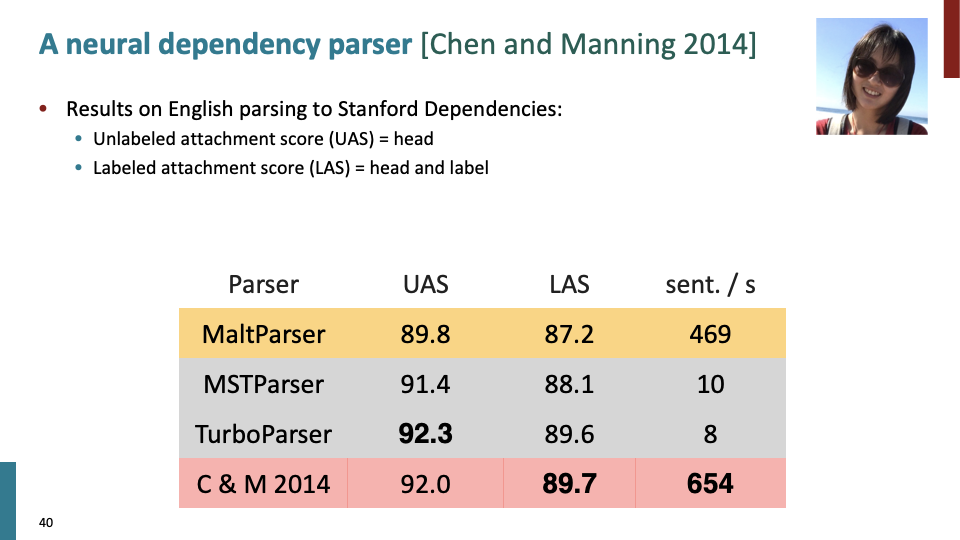
MaltParser 가 Nivre가 만든 shift-reduce parser이고, 2,3번째 parser는 90년대때 만든 graph based dependency parser이고, 마지막 parser가 가장 빠른 신경망을 이용해 만든 파서 입니다.

대부분의 NLP work은 fine-grained(미세하게 조정된) parts of speech를 사용합니다. 예를들어, work, works, working에 대해 각기 다른 verb로 고려합니다. 그리고 그들의 similarity를 묘사하기 위해 distributed representation을 사용할 수 있습니다.
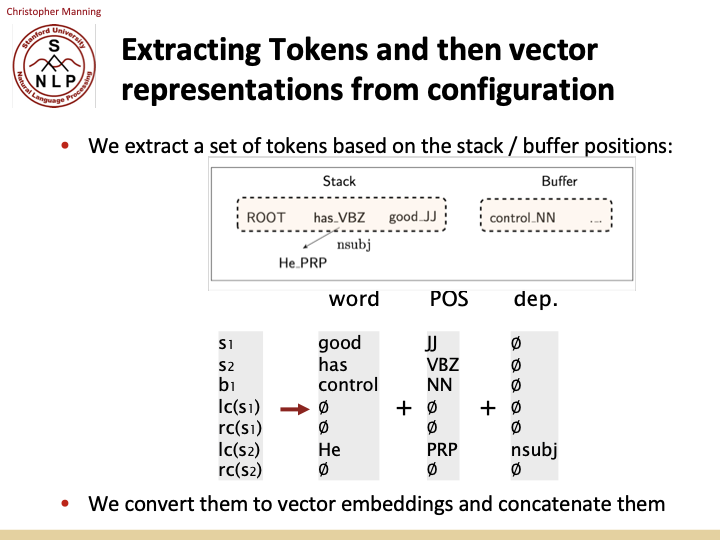
아이디어는 다음과 같습니다. 스택과 버퍼의 각 포지션마다 단어와 part of a speech가 있고, 구조를 이미 build 했다면 dependency를 알 수 있습니다. 각 위치당 word, pos, dep가 존재하고, 이것들 모두를 distributed representation으로 변환할 수 있습니다. 그리고 이 distributed representation을 이용하여 parser를 build할 것 입니다. 이와 같이 Nirve와 같은 방식으로 파서를 만들고, 우리는 신경망에서 그 다음을 무엇을 할지에 대해 변경할 것입니다.
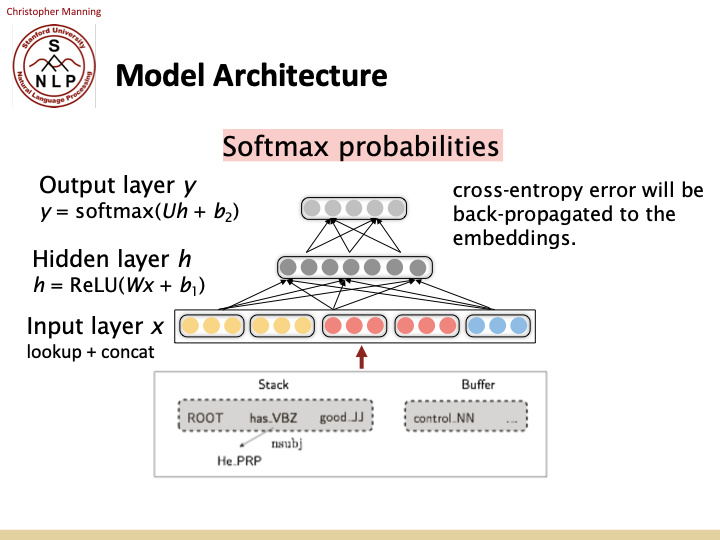
위에서 설명한 concatenate한것이 input layer가 됩니다.
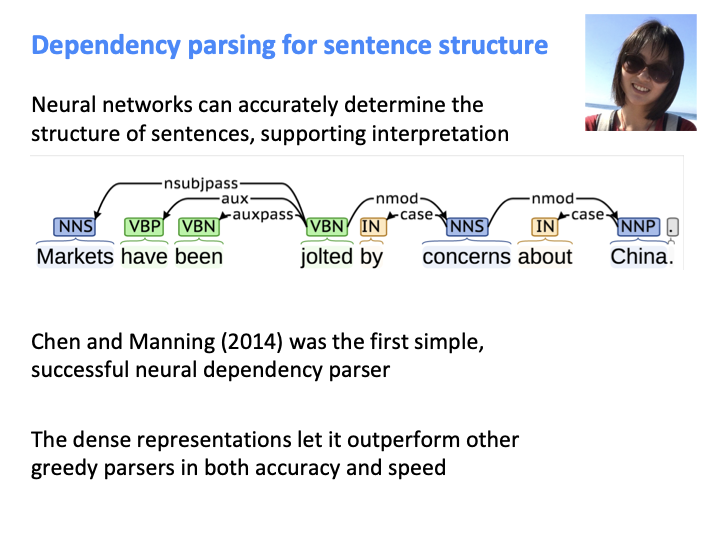
Nirve가 했던 모든 좋은것과 dense representation을 더한 parser가 더 좋은 성능을 보였습니다.

Google은 bigger, deeper network으로 더 좋은 성능의 parsing 방법을 만들었습니다. 그리고 beam search는 단순히 다음 action으로 가장 좋은게 뭔지 보고, 시도하고 이 과정을 반복하는 것 대신에 two action을 고려해보고 어떤일이 일어나는지 explore해보자는 idea입니다.