CS224N|Lecture 1 Introduction and Word Vectors
01 Aug 2021
Clova ai rush 2021에 참가하면서 nlp 관련 하여 한국어 text dataset으로 extreme classification, multi-label classification 과제에 참여했다. 어떤 분야를 집중적으로 파볼지 오리무중이었던 차에 좋은 동기가 되어 수업을 듣게 되었다.

수업을 시작하기 앞서 xkcd cartoon으로 언어가 얼마나 흥미로운 시스템인지 설명했다. 그중 흥미로웠던 얘기는 다음과 같다.
언어는 uncertain evovled system of communication 이지만, 어떤 면에서는 꽤 의사소통이 잘되듯이 사람들은 그 언어가 주는 의미에 대해 동의 한다. 우리는 아마도 사람들이 의미하는 바를 확률적 추론을 통해 추측하여 이해한다.
언어에 의해 전달되는 정보의 양은 매우 느리다. 우리는 form of adaptive compression인 시스템을 사용하여 의사소통 한다. 우리는 누군가와 대화할 때 나 자신과 비슷하게 그들의 머리 속에 꽤 많은 양의 지식이 있다고 가정한다. (가령 각 단어가 무엇을 의미하고 그 단어가 문장 속에서 어떻게 작동하는지.) 그래서 상대적으로 짧은 단어를 말해도 많은 것들을 이해할 수 있다.
위 설명을 듣고, nlp에서 word vector들의 값이 내포하고 있는 의미들이나, 작동하는 방식이 우리가 실생활에서 의사소통하는 방식과 비슷하다고 생각했다.

단어의 의미를 어떻게 나타내는가에 대한 물음으로 본 내용을 시작한다. 이후 슬라이드에 나오겠지만, 일단 첫번째 나타내는 방법으로 denotational semantics (표시적 의미론)이 있다. 보통 언어학자가 생각하는 방법이다. 예를 들어 chair라는 단어는 온갖 chair를 포함한다.

그렇다면 컴퓨터에서는 usable meaning에 대해 어떻게 표현할까? python pakage 중에 nltk(Natural Language Toolkit)이라는 것이 있고, WordNet을 사용하여 동의어(synonym)과 hypernyms(상위어)에 대해 검색할 수 있다. WordNet은 일종의 thesaurus(유의어 사전)이다. 하지만 WordNet은 문제점이 많다.

WordNet은 생각보다 잘 작동하지 않는다. 동의어(synonym)는 nuance를 고려하지 않는다. 가령 proficient(=능숙한)이 good의 동의어 리스트에 올라와 있는 것을 보면 알 수 있다. 또한 human labor를 통해 등재되는 사전이기 때문에 새로운 단어가 없다.

그래서 word meaning을 represent하는 더 나은 방법으로써 traditioanl NLP가 소개되었다. 2012년도까지의 연구를 보통 traditiaonl nlp라고 한다.(nlp에 대해 neural style을 사용한 것이 2013년도부터이다.)
localist representation은 각 단어를 one-hot vector로 표현하는 방법이다. 하지만 이렇게 사용하면 안좋은 점은 language에는 정말 많은 단어가 있고, derivation morphology(=실재하는 단어에 단어를 계속 붙여 나가며 단어를 만드는 방법)으로 인해 단어 수는 infinite하다고 할 수 있다. 하지만 단어의 수는 minor problem이고 더 큰 문제점이 있다.

단어의 의미 관계를 이해하는 것이 더 큰 문제이다. 단어들은 one-hot vector이므로, 모든 단어의 pair는 서로 orthogonal하다. 두개의 one-hot vector사이에 유사성이 전혀 없다.
그렇다면 big table of word similairity는 어떤가 라는 질문을 할 수 있다. (즉, WordNet과 동일하다.) 이것은 사실 2005년에 구글이 했던 것이다. 예를 들어 $5*10^5$개의 단어가 있다고 하면, 각 pair의 one hot vector에 대한 table을 만들려면 2.5조 이상의 정말 큰 table을 만들어야 한다. 구현이 불가능하다고 볼 수 있다.
해결 방법은 유사성을 vector 그 자체로 encode하는 방법이다.

앞서 단어의 의미를 나타내는 방법은 denotational semantics (표시적 의미론)이었고, 또 하나의 방법은 distributional semantic(분포 의미론)이다. 특정 단어가 어떤 context에 쓰이는 것이 옳고, 옳지 않 고를 설명할 수 있다 라는 것이 이 방법의 아이디어라고 할 수 있다. 현대의 통계적 NLP에서 가장 성공적인 아이디어로 J.R.Firth가 만들었다.
단어 w가 어떤 text에 나타난다면, 그 context는 그 단어 w 주변에 나타나는 set of words 이다. 슬라이드 아래부분에 나와있는 예시처럼 (banking 주변에 나타나는) context words가 banking을 나타낸다.

이제 traditioanl localist representation이 아닌 distributed representation을 사용할 것이다. 각 단어에 대해 dense vector를 사용할 것이고, 같은 context에 사용되는 vectors of words와 값이 유사할 것이다.
word vectors는 word embeddings 또는 word representations이라고 불리기도 한다. word vector의 크기는 최소 50, 보통은 300, 매우 좋은 성능을 위해서라면 1000,2000,…의 크기를 사용한다. 그리고 앞서 본 one-hot vector의 500,000 vector보다는 훨씬 작다.

예시의 vector는 dimension이 9이지만, 실제로는 100이상이다. 100 dimensional vector를 visualize하기엔 정말 어려우므로, 2 dimension으로 project down하여 visualize한다. 원래의 vector space에 대한 detail을 모두 무시하여 투사했음에도 단어와의 유사성을 관찰 할 수 있다.

NLP에 가장 큰 영향을 주었던 것이 2013년에 나온 Word2vec이다. Thomas Mikolov가 만들었고, 정말 간단하면서도 scalable한 word representaion 방법이다. distributed representation of word에 대한 첫번째 work는 아니긴 하다. (더 오래전에 Yoshua Bengio가 만들었다.)
NLP 사람들은 large pile of text를 corpus라고 부른다. 먼저 word vector들은 random vector로 시작한다. context에 있는 단어 중 한개를 center word로 정하고, fixed size만큼의 주변 단어 context word를 예측한다. center word에 대한 위치를 계속 바꾸며 iteration을 수행한다.
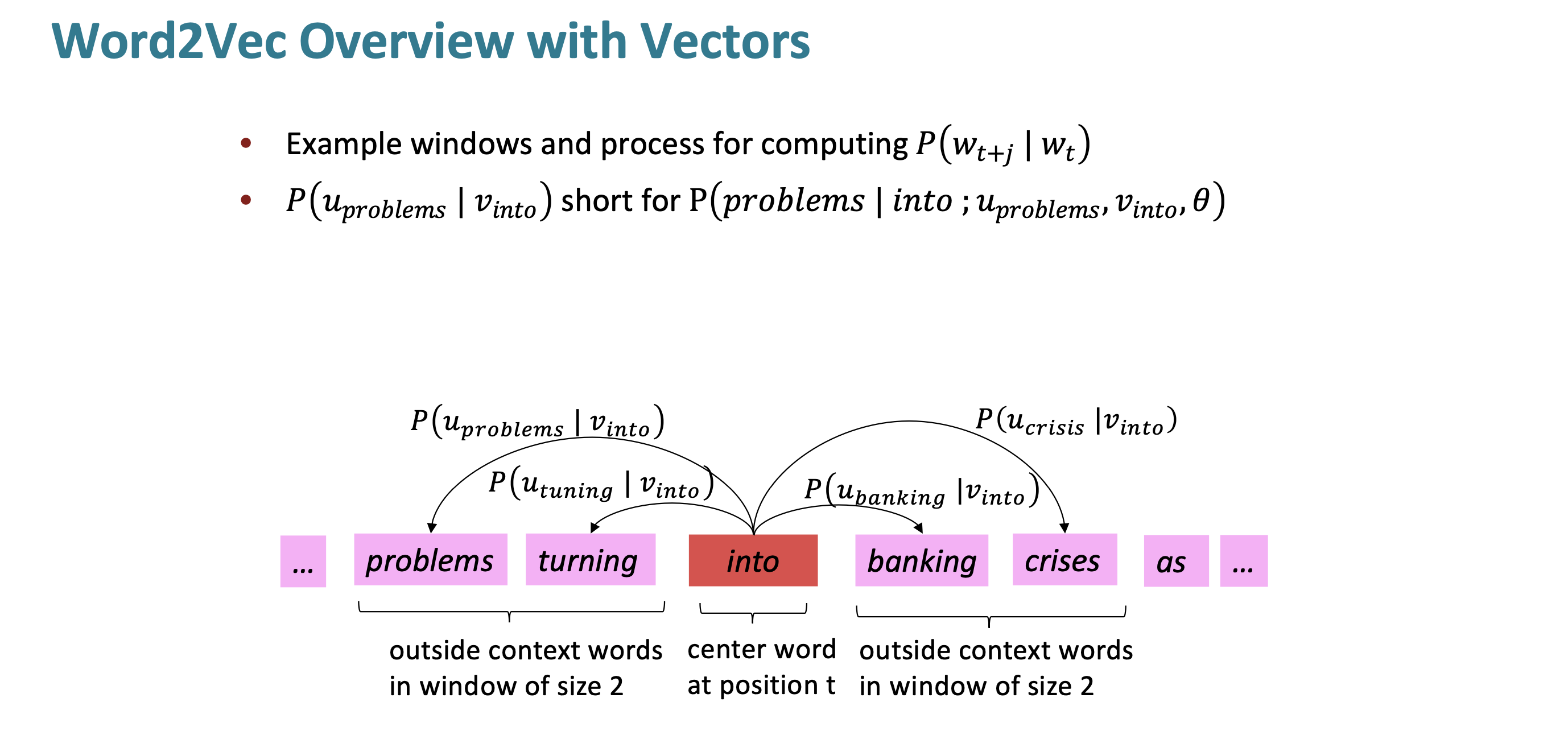
예를 들어 설명해 보겠다. “into”라는 단어 주변에 어떤 단어들이 나타나는지 predict한다. 얼마나 잘 predict하는지 보고 vector representation을 더 잘 predict하는 방향으로 바꾼다. 그런 다음 다음 단어로 넘어 간다.
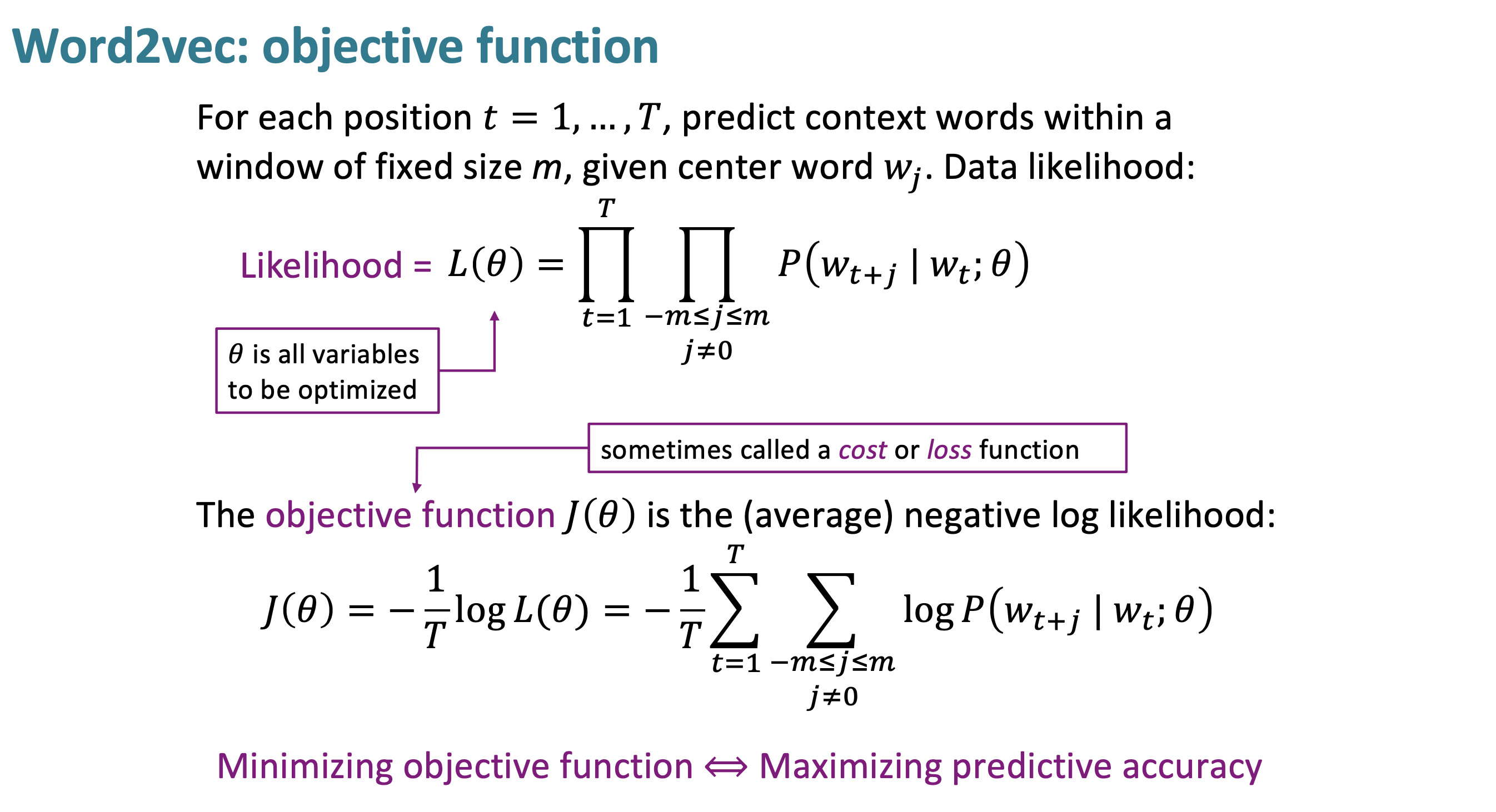
$P(w_{t+j} \mid w_t;\theta)$ : Probability model은 $w_t$ 단어를 중심으로 좌우 m크기 만큼의 단어에 대해 예측하는 모델이다.
$L(\theta)$ : model Likelihood는 text에 있는 각 단어에 대해center 단어 주변의 단어에 대해 얼마나 잘 예측하는지 에 대한 모델이다. $L(\theta)$은 오직 $\theta$에만 dependent하다. $\theta$는 단어들의 word vector space이다.
$J(\theta)$ : objective function으로 위의 Likelihood에 대한 값을 최적화할 때, minimize하기 위해 -을 붙여주고, normalize하기 위해 average로 계산을 해준 식이다.

각 word는 2가지 word vector representation이 있다. (1) $v_w$ : w가 center word일 경우, (2) $u_w$ : w가 context word일 경우이다.
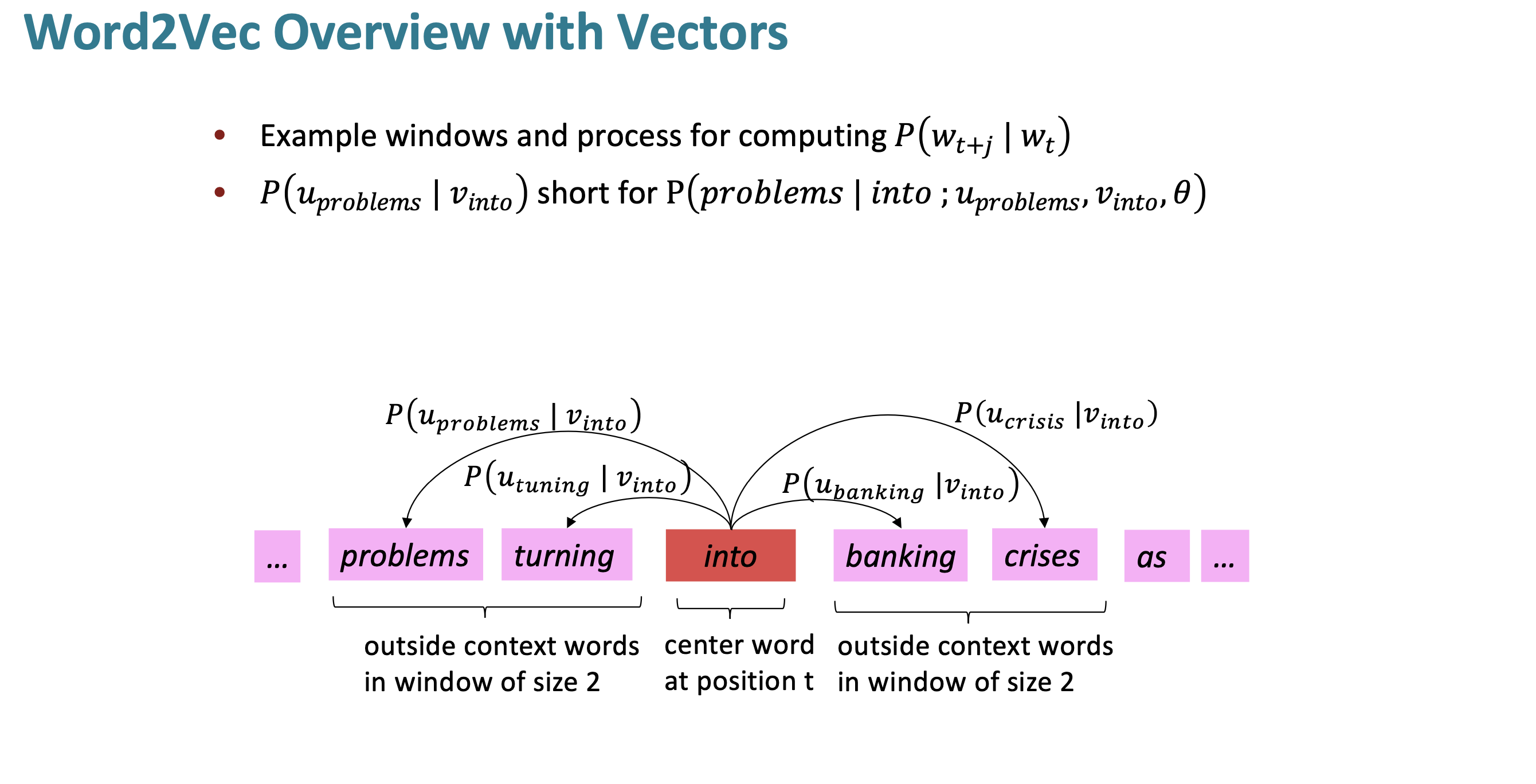
위에서 말한 prediction function은 center word, context word에 대해 위와 같이 계산된다. “into”가 center word이므로, $v_w$이다.
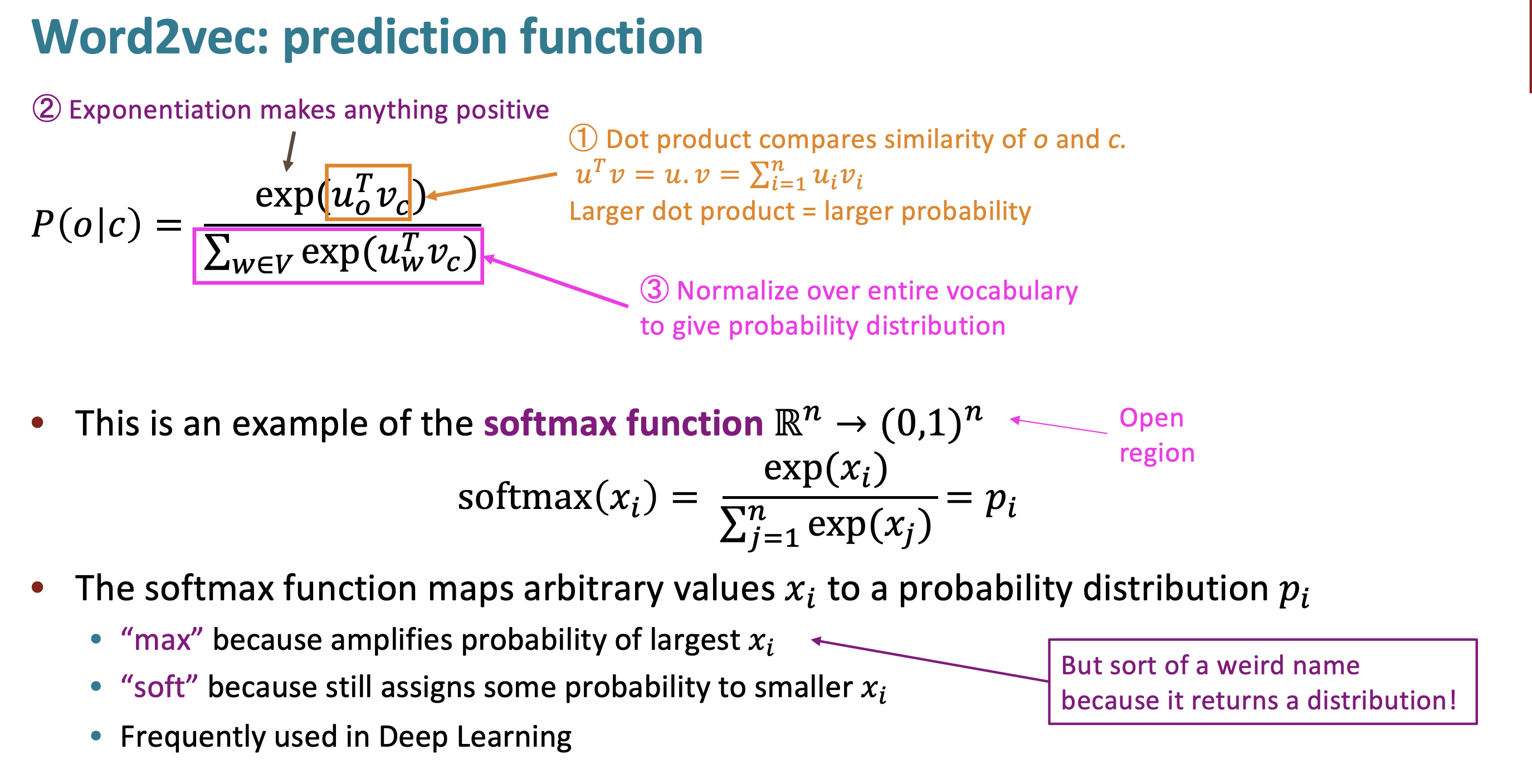
Prediction function이 어떻게 동작하는지 설명하겠다. (1) dot product이 center word와 context word 사이의 유사도를 계산한다. (2) 계산한 유사도를 모두 양수로 만들기 위해 exponentitation해주고 (3) probability의 총합이 1이 되기 위해 나눠준다.
prediction function은 일종의 softmax function이라고 볼 수 있다. (식이 완전히 똑같다.)
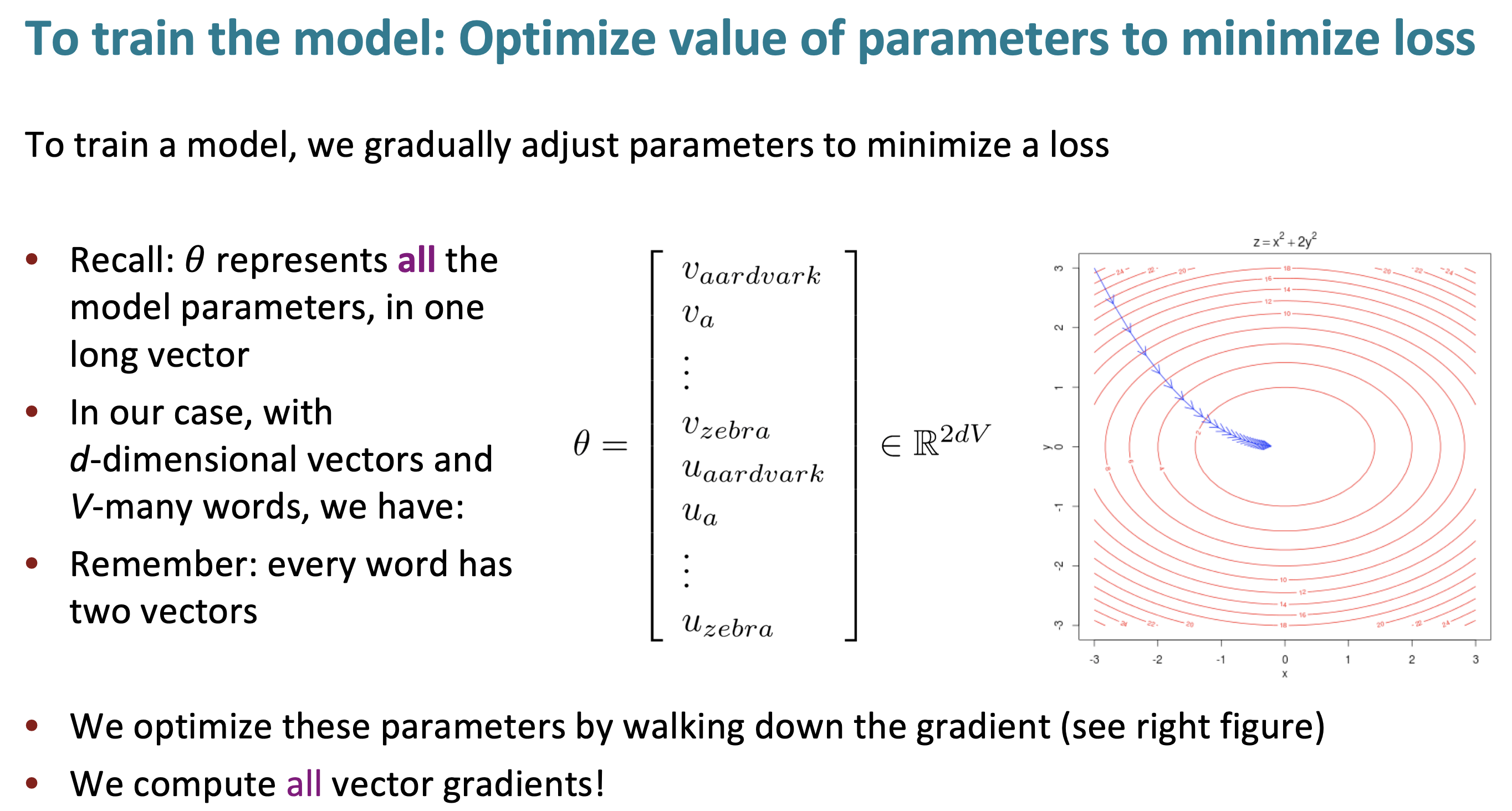
model을 학습하기 위해 loss를 최소화 하기 위한 parmeter를 구해야 한다. 이제 실제로 vector gradient를 구하기 위해 어떤 식이 있는지 살펴 볼 것이다.
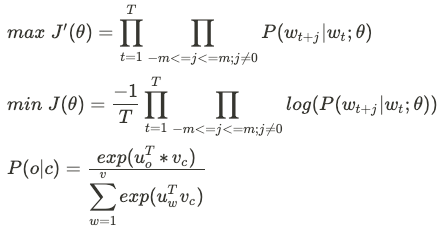
u,v는 처음에 randomly initialize 된다. gradient의 값과 방향도 radomly initialize 된다. center word 앞 뒤로 10개씩만 예측한다 하더라도 매우 loose한 모델일 것이고, 굉장히 잘하면 5%일 것이다. 하지만 그럼에도 불구하고, withdrawal이 football보다 bank 근처에서 나타날 확률이 크다는 것을 알 수 있다.
Probablity model 에서 center word 에 대해서 gradient를 어떻게 계산하는지 수식을 써보겠다.
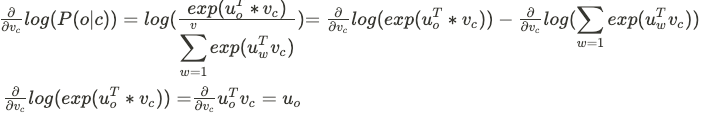
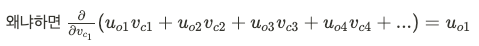
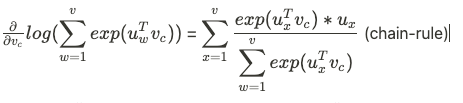
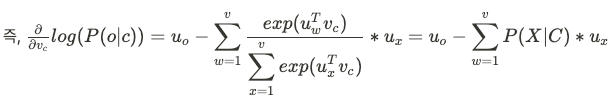
말로 풀어서 설명하자면,
slope in multi dimensional space = 관찰된 context word vector - current word에 대해 expected contex word의 값 이라고 할 수 있다.
실습 수업으로는 gensim을 사용하여 wordvector를 만드는 내용이었다. gensim으로 word2vec은 이전에도 해봤지만 pretrained된 glove는 처음 사용해본다.
gensim은 word similarity pakage로 “Latent Dirichelet anlysis”를 사용한 방법이라고 한다. (fourier series에서 디리클레 조건은 들어봤다.)
gensim은 Glove vector를 원래는 지원하지 않지만 Glove file을 word2vec file format으로 바꾸는 utility를 제공한다.
import numpy as np
# Get the interactive Tools for Matplotlib
%matplotlib notebook
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from sklearn.decomposition import PCA
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
glove_file = datapath('glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
glove2word2vec(glove_file, word2vec_glove_file)
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
similar는 유용하나 non-similar는 그 자체로는 유용하지 않다.
model.most_similar('banana')
"""
[('coconut', 0.7097253203392029),
('mango', 0.7054824829101562),
('bananas', 0.6887733340263367),
('potato', 0.6629636287689209),
('pineapple', 0.6534532308578491),
('fruit', 0.6519854664802551),
('peanut', 0.6420575976371765),
('pecan', 0.6349173188209534),
('cashew', 0.6294420957565308),
('papaya', 0.6246591210365295)]
"""
model.most_similar(negative='banana')
"""
[('keyrates', 0.7173939347267151),
('sungrebe', 0.7119238972663879),
('þórður', 0.7067720293998718),
('zety', 0.7056615352630615),
('23aou94', 0.6959497928619385),
('___________________________________________________________',
0.694915235042572),
('elymians', 0.6945434212684631),
('camarina', 0.6927202939987183),
('ryryryryryry', 0.6905653476715088),
('maurilio', 0.6865653991699219)]
"""
result = model.most_similar(positive=['woman', 'king'], negative=['man'])
print("{}: {:.4f}".format(*result[0]))
"""
queen: 0.7699
"""
def analogy(x1, x2, y1):
result = model.most_similar(positive=[y1, x2], negative=[x1])
return result[0][0]
analogy('japan', 'japanese', 'australia')
"""
australian
"""

하지만 negative idea를 위와 같은 analogy에 유용하게 사용할 수 있다. king - man + woman = queen 이다.
def display_pca_scatterplot(model, words=None, sample=0):
if words == None:
if sample > 0:
words = np.random.choice(list(model.index_to_key), sample)
else:
words = [ word for word in model.vocab ]
word_vectors = np.array([model[w] for w in words])
twodim = PCA().fit_transform(word_vectors)[:,:2]
plt.figure(figsize=(6,6))
plt.scatter(twodim[:,0], twodim[:,1], edgecolors='k', c='r')
for word, (x,y) in zip(words, twodim):
plt.text(x+0.05, y+0.05, word)
display_pca_scatterplot(model,
['coffee', 'tea', 'beer', 'wine', 'brandy', 'rum', 'champagne', 'water',
'spaghetti', 'borscht', 'hamburger', 'pizza', 'falafel', 'sushi', 'meatballs',
'dog', 'horse', 'cat', 'monkey', 'parrot', 'koala', 'lizard',
'frog', 'toad', 'monkey', 'ape', 'kangaroo', 'wombat', 'wolf',
'france', 'germany', 'hungary', 'luxembourg', 'australia', 'fiji', 'china',
'homework', 'assignment', 'problem', 'exam', 'test', 'class',
'school', 'college', 'university', 'institute'])
다음은 PCA(차원 축소)를 통해 Glove model을 시각화 시킨 결과이다.